[Day 3] 你真了解资料吗?试试看视觉化分析吧!
你真了解资料吗?试试看视觉化分析吧!
今日学习目标
- 探索式分析 (EDA)
- 聊聊何谓 EDA,为何要做数据分析?
- 撰写第一支 EDA 程序
- 透过鸢尾花 (iris) 资料集,来查看资料的分布状态
探索式分析 (EDA)
探索式资料分析 (Exploratory Data Analysis, EDA),主要概念是利用数据统计的方式视觉化资料。透过资料的探索式分析可以查看资料集当中每个特徵彼此的重要程度以及其资料分布状况,有良好的数据分析习惯能够帮助你更了解资料集的特性。另外做 EDA 的好处是可以从各种面向先了解资料的状况,以利後续的模型分析。
EDA 必要的套件
- 资料处理 – Pandas, Numpy
- 绘图相关 – Matplotlib, Seaborn
- Matplotlib:Python 最常被使用到的绘图套件
- Seaborn:以 matplotlib 为底层的高阶绘图套件

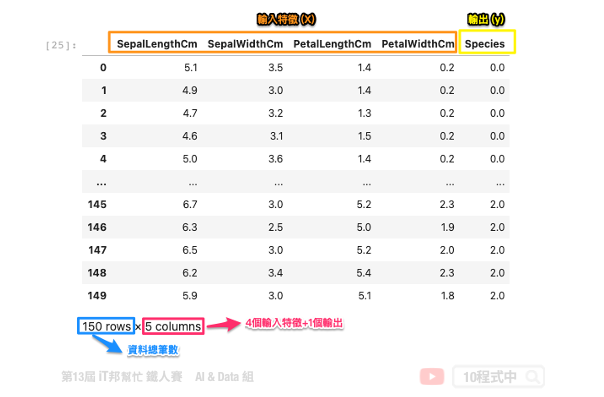
鸢尾花朵资料集一览
此资料集总共有4个输入特徵。分别为花萼长度、花萼宽度、花瓣长度与花瓣宽度。输出特徵为花朵的品种,共有三种类别分别为 0: iris setosa、 1: iris versicolor、 2: iris virginica。

载入必要套件
首先我们载入资料探索式分析所需的套件。分别有进行数据处理的函式库的
pandas、高阶大量的维度阵列与矩阵运算的 numpy、处理资料视觉化的绘图库 matplotlib 与 seaborn。最後一个是资料集来源,此系列范例我们采用 Sklearn 所提供的鸢尾花分类的资料集。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
Sklearn Toy datasets
Sklearn 套件中提供了七个快速入门的 Toy datasets 很推荐初学者可以载入来玩玩看,并且练习做资料探索与建模。每一个资料集呼叫的方法非常简单。以鸢尾花朵资料集为例,我们可以透过 API 取得输入与输出。
from sklearn.datasets import load_iris
iris = load_iris()
# 输入特徵
X = iris.data
# 输出特徵
y = iris.target
Sklearn 提供了许多 API 方法可以呼叫:
- data: 取得输入特徵
- target: 取得输出特徵
- feature_names: 取得输入特徵的名称
- target_names: 取得输出的类别标签(分类资料集)
- DESCR: 资料集详细描述
如果想试试其他的资料集可以参考:
- 回归问题
- load_boston 波士顿房价预测
- load_diabetes 糖尿病预测
- load_linnerud 体能评估预测
- 分类问题
- load_iris 鸢尾花种类预测
- load_digits 手写数字辨识
- load_wine 葡萄酒种类预测
- load_breast_cancer 乳癌预测
载入资料集
首先我们载入鸢尾花朵资料集。为了方便分析我们将 numpy 格式的资料转换成 DataFrame 的格式进行资料探索。因为透过 Pandas 的 DataFrame 格式我们更能用表格的形式观察资料。
iris = load_iris()
df_data = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
columns= ['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species'])
df_data
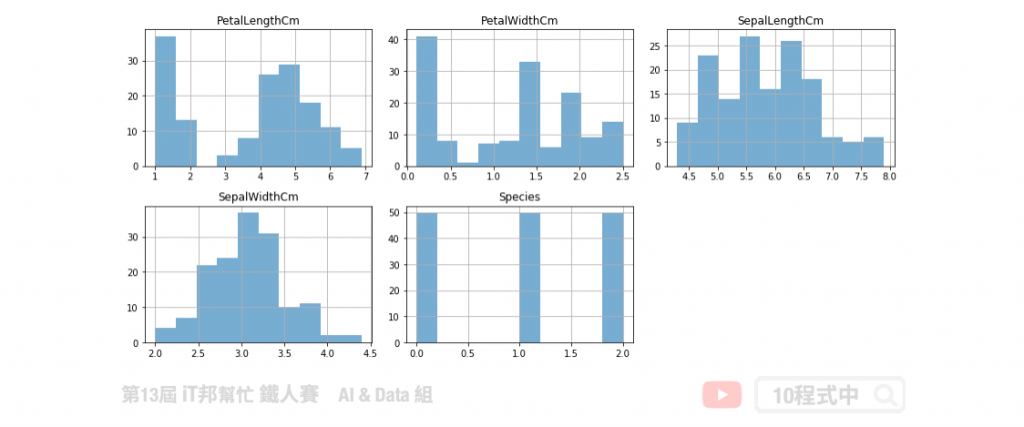
直方图
直方图是一种对数据分布情况的图形表示,是一种二维统计图表。我们可以直接呼叫 Pandas 内建函式 hist() 进行直方图分析。其中我们可以设定 bins(箱数),预设值为 10。如果设定的输量越大,其代表需要分割的精度越细。通常取一个适当的箱数即可观察该特徵在资料集中的分布情况。藉由直方图我们可以知道每个值域的分布大小与数量。我们也能发现输出项的类别共有三个,并且这三个类别的数量都刚好各有 50 笔资料。我们也能得知这一份资料集的输出类别是一个非常均匀的资料。
#直方图 histograms
df_data.hist(alpha=0.6,layout=(3,3), figsize=(12, 8), bins=10)
plt.tight_layout()
plt.show()
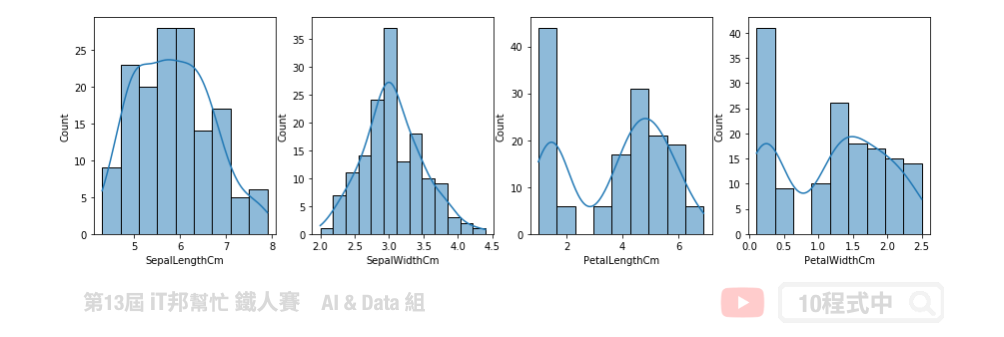
我们也可以透过 Seaborn 的 histplot 做出更详细的直方图分析。并利用和密度估计 kde=True 来查看每个特徵的分布状况。
fig, axes = plt.subplots(nrows=1,ncols=4)
fig.set_size_inches(15, 4)
sns.histplot(df_data["SepalLengthCm"][:],ax=axes[0], kde=True)
sns.histplot(df_data["SepalWidthCm"][:],ax=axes[1], kde=True)
sns.histplot(df_data["PetalLengthCm"][:],ax=axes[2], kde=True)
sns.histplot(df_data["PetalWidthCm"][:],ax=axes[3], kde=True)
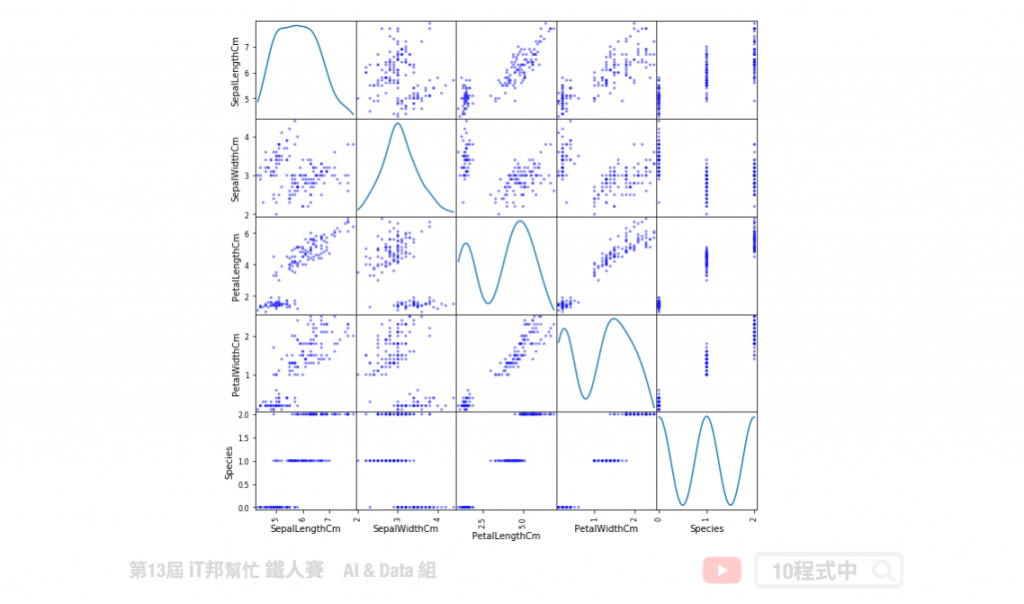
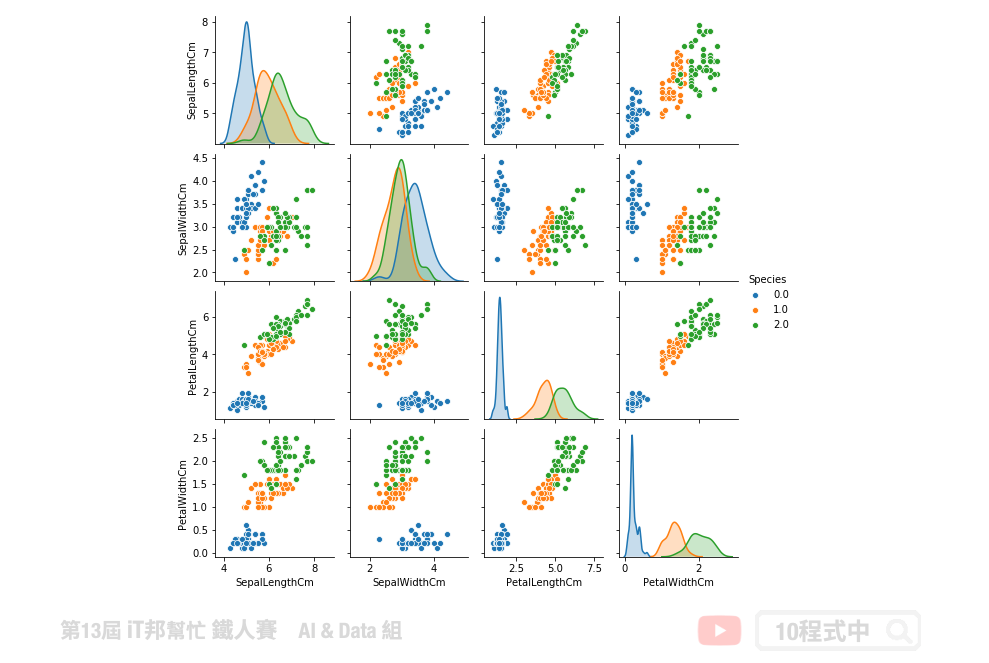
核密度估计
核密度估计分爲两部分,分别有对角线部分和非对角线部分。在对角线部分是以核密度估计图(Kernel Density Estimation)的方式呈现,也就是用来看某一个特徵的分布情况,x轴对应着该特徵的数值,y轴对应着该特徵的密度也就是特徵出现的频率。在非对角线的部分为两个特徵之间分布的关联散点图。将任意两个特徵进行配对,以其中一个爲横座标,另一个爲纵座标,将所有的数据点绘制在图上,用来衡量两个变量的关联程度。
使用 Pandas 绘制:
from pandas.plotting import scatter_matrix
scatter_matrix( df_data,figsize=(10, 10),color='b',diagonal='kde')
使用 Seaborn 绘制:
sns.pairplot(df_data, hue="Species", height=2, diag_kind="kde")
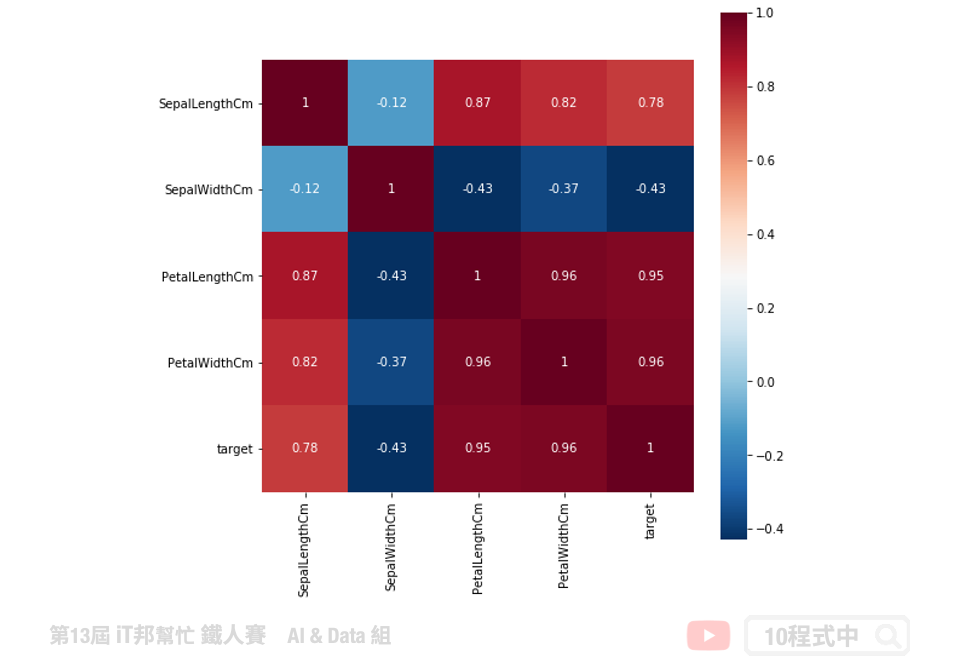
关联分析
透过 pandas 的 corr() 函式可以快速的计算每个特徵间的彼此关联程度。其区间值为-1~1之间,数字越大代表关联程度正相关越高。相反的当负的程度很高我们可以解释这两个特徵之间是有很高的负
关联性。
# correlation 计算
corr = df_data[['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species']].corr()
plt.figure(figsize=(8,8))
sns.heatmap(corr, square=True, annot=True, cmap="RdBu_r")
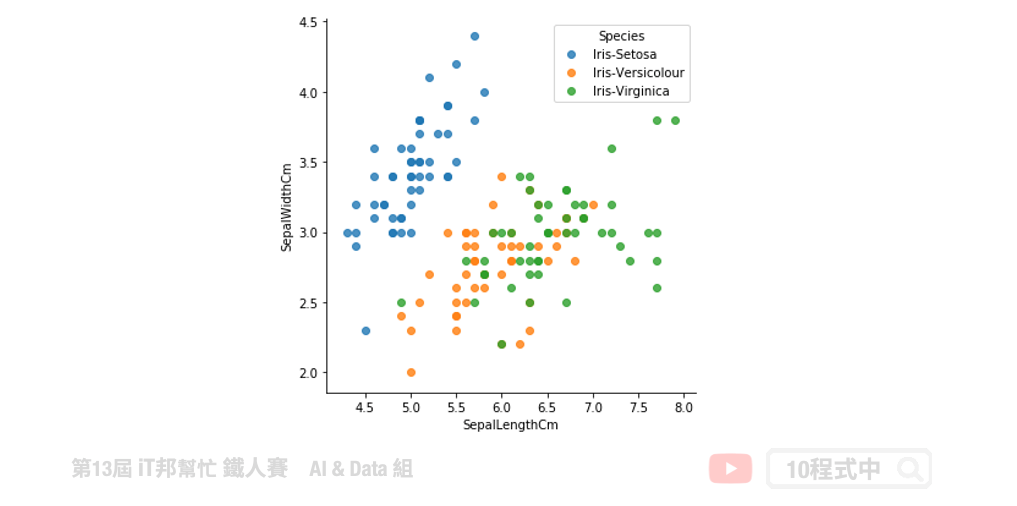
散布图
透过散布图我们可以从二维的平面上观察两两特徵间彼此的分布状况。如果该特徵重要程度越高,群聚的效果会更加显着。
sns.lmplot("SepalLengthCm", "SepalWidthCm", hue='Species', data=df_data, fit_reg=False, legend=False)
plt.legend(title='Species', loc='upper right', labels=['Iris-Setosa', 'Iris-Versicolour', 'Iris-Virginica'])
箱形图
透过箱形图可以分析每个特徵的分布状况以及是否有离群值。我们利用箱形图来表示四分位数来观察数据分散情况。箱形的两端为第一个四分位数涵盖25%之资料(Q1)与第三个四分位数涵盖75%之资料(Q3),而箱形图的中间线为中位数显示涵盖前50%资料之位置。箱形上虚线的端点为极大值,箱型下虚线的点为极小值。
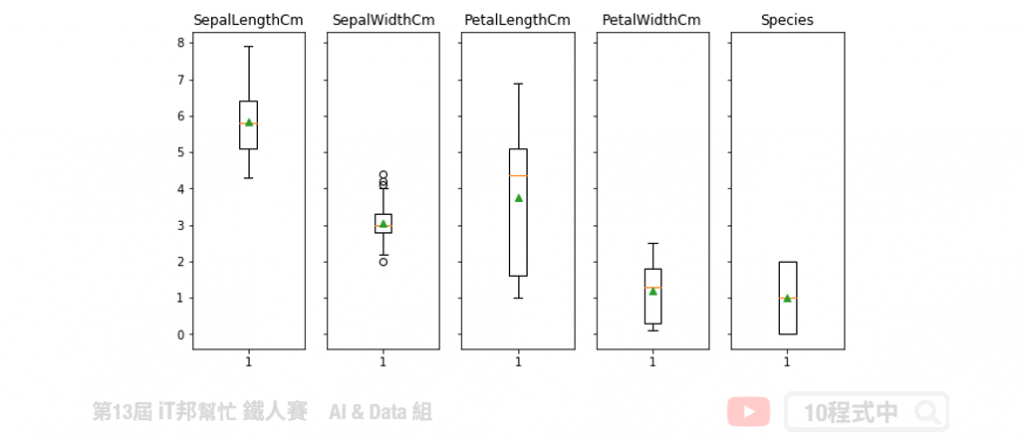
今天所介绍的资料视觉化都是很基础的资料探索方式。只要简单的几个步骤就能帮助你了解收集的资料,并利於後面资料处理及建模。未来我再带给各位一些不错的资料视觉套件,帮助你对资料迳行更多的视觉分析。
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: Day01 - Vue3 环境设置 Vue CLI 帮我准备手术室卡关笔记
Week38 - 各种安全性演算法的应用 - 概念篇 [高智能方程序系列]
本文章同时发布於: Medium iT 邦帮忙 大家好,这几天较有时间,终於可以好好的思考文章 XD...
Day 30 消费者每天在变,广告没有尽头
经过 29 天的探讨,已经慢慢建立概念了无论是关键字或是广告的文案,基本上无论 Google Ads...
Day 17 | Flutter的常用 widgets - Container、Row、Column
StatefulWidget 的build 回到昨天 StatefulWidget 的 build ...
【左京淳的JAVA学习笔记】第七章 API
API(application program interface)是指程序之间具有特定规范的接口。...
验证资料/产生测试资料/表格显示 - day05
储存前,验证资料正确性 当使用者输入资料後需要验证资料正确性,并提示给使用者。在VoK要做到这点非常...