[自然语言处理基础] 文本预处理(II):正规化,就是一视同仁
前言
上次我们断开了英文文本的锁链,将庞大的字串拆解成成为词条的小单元。语言中仍有时态变化、单复数型态、甚至是口语等复杂甚至随机的因素不利於後续的文字处理,因此我们透过一系列的流程将词条的变形一一还原。

文字的正规化(Text Normalisation)
英文的单词(或小单位)具有以下常见的变形:
- 名词单、复数:亦规则与无规则之分
- 动词时态:亦有规则变化与特例
- 动词人称形态:如 I do 、 he does
- 形容词副词化:如 creative 与 creatively
- 大、小写:句首开头是英文的惯例,对词意并无贡献
- 常见缩写:如 I'm 、 weren't
- 口语形式:如 wanna 、 gonna 、 ain't 、 imma 、 she don't
- 名词性别:现代英文已无保留性别(gender),而德文、法文、西文等大多数印欧语系的名词皆有性别之分,详见最下方连结[2]
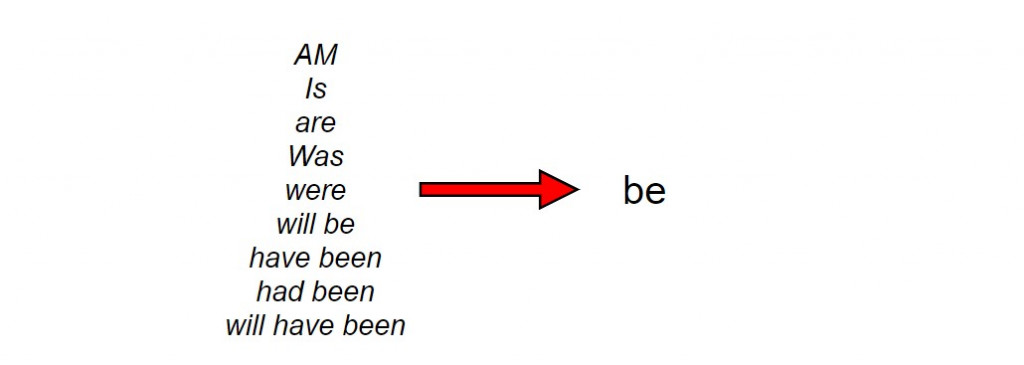
对词条的归一化,将意义相同的诸多变化形态一视同仁,有助於减少资料处理的负担,这个过程称之为正规化(normalisation)。
Why do we need text normalization?
When we normalize text, we attempt to reduce its randomness, bringing it closer to a predefined “standard”. This helps us to reduce the amount of different information that the computer has to deal with, and therefore improves efficiency.本文出处:Text Normalization for Natural Language Processing (NLP)
-
小写转换(Lowercase Conversion)
首先我们去除大小写的差异,按照惯例将所有文字转成小写:
tokenised = ["The", "spectators", "all", "stood", "and", "sang", "the", "national", "anthem"]
# lowercasing each token
tokens_lower = [token.lower() for token in tokenised] # ['the', 'spectators', 'all', 'stood', 'and', 'sang', 'the', 'national', 'anthem']
-
语干提取(Stemming)
在语言学中,词干(word stem)表示一个单词中最基本且核心的形式,例如 friendships 就是由 friendship 与词缀 -s 所组成, friendship 就是其词干;而 friendship 则是由 friend 与词缀 -ship 所构成,此时 friend 则是其词干。因此词干的提取基於不同理念或不同演算法,有时会得到不同的结果。我们以常见的 Porter Stemming Algorithm、 Lancaster Stemming Algorithm 以及 Snowball Stemming Algorithm 说明,从而比较它们的差异。
# importing stemmer classes
from nltk.stem import PorterStemmer, LancasterStemmer, SnowballStemmer
tokens = ["the", "spectators", "all", "stood", "and", "sang", "the", "national", "anthem"]
# stemming
port = PorterStemmer()
stemmed_port = [port.stem(token) for token in tokens]
lanc = LancasterStemmer()
stemmed_lanc = [lanc.stem(token) for token in tokens]
snow = SnowballStemmer("english")
stemmed_snow = [snow.stem(token) for token in tokens]
# showing stemmed results
print("Porter: {}".format(stemmed_port))
print("Lancaster: {}".format(stemmed_lanc))
print("Snowball: {}".format(stemmed_snow))

-
词形还原(Lemmatisation)
很显然,萃取词干并未能满足我们减少词形变化(inflection)的需求,因此我们转而找寻更能代表单词基本形式-词位(lemma),例如 sings、 singing、 sang、 sung 共享同一个词位 sing。以下我们将借用 NLTK.stem 模组中收录的 WordNetLemmatizer 类别找出词位,WordNet为普林斯顿大学所建立的免费公开词汇资料库。
from nltk.stem import WordNetLemmatizer
tokens = ["the", "spectators", "all", "stood", "and", "sang", "the", "national", "anthem"]
lemmatiser = WordNetLemmatizer()
lemmatised = [lemmatiser.lemmatize(token) for token in tokens]
print("lemmatised: {}".format(lemmatised))
执行结果为:

Oops! 效果依然差强人意。我们加入一个法宝,就能够将词形变出来。至於该法宝是什麽,我们留到下集再介绍。
"""
code snippets
"""
lemmatised_magic = [lemmatiser.lemmatize(token, get_part_of_speech(token)) for token in tokens]
print("lemmatised_magic: {}".format(lemmatised_magic))

Voilà! 原形毕露了!
-
停用词去除(Stopword Removal)
在文句中有些单词并对於词义的传达并无太大的作用,如 a/ an、 the 、 is/ are等,被称之为停用词( stop words)。如何去除停用词呢?请稍安勿躁往下看:
from nltk.corpus import stopwords
nltk.download("stopwords")
# defining stopwords in English
stop_words = set(stopwords.words("english"))
# removing stop words
words_no_stop = [word for word in lemmatised if word not in stop_words]
print("stop words removed: {}".format(words_no_stop))
检视结果:

结论
我想今天所谈及的正规化处里技巧中,最令人费解的就是 Stemming 与 Lemmatisation 的差别了。下图呈现两者之比较:

词干提取与词形还原的差异
图片来源:DEVOPEDIA
当我们在搜寻引擎上输入关键字,并不需要输入与搜寻结果百分百吻合的语句,也能立即找出我们要的资讯,文本的正则化功不可没:
今天的介绍就到此,また明日!
阅读更多
- Text Normalization for Natural Language Processing (NLP)
- Gender in English
- Lexeme and Lemma
- WordNet| A Lexical Database for English
Day10:串列的循环
在我们有Day9串列的基础之後,让我们来试试看这些程序码吧! [In] drinks=['cola'...
【Day 17】深度学习(Deep Learning)--- Tip(二)--- ReLU
Vanishing Gradient Problem 昨天我们提到当你的Network很深的时候,设...
Day 2 - 环境配置
开始前 首先威尔猪使用的是 Mac,编辑器用的是 Visual Studio Code,如果是使用 ...
(Day17) this 介绍下 - 绑定 this 的 call & apply & bind 与严格模式
前言 上篇大致讲解了 this 在不同状况的指向,这篇会来讲讲使用 call/apply/bind ...
未知的第四天 -新增页面
在 Nuxt.js 中,我们建立路由不必再自己撰写虚拟路由了,直接建立在 page 内即可 若是要使...