案例:在AWS上透过SageMaker跟CodePipeline驾驭MLOps的参考架构(下)
接续上一篇关於专案参加角色与pipeline的介绍,这一篇继续谈论每一区块需要的服务以及如何依照使用情境的顺序将各服务串接。
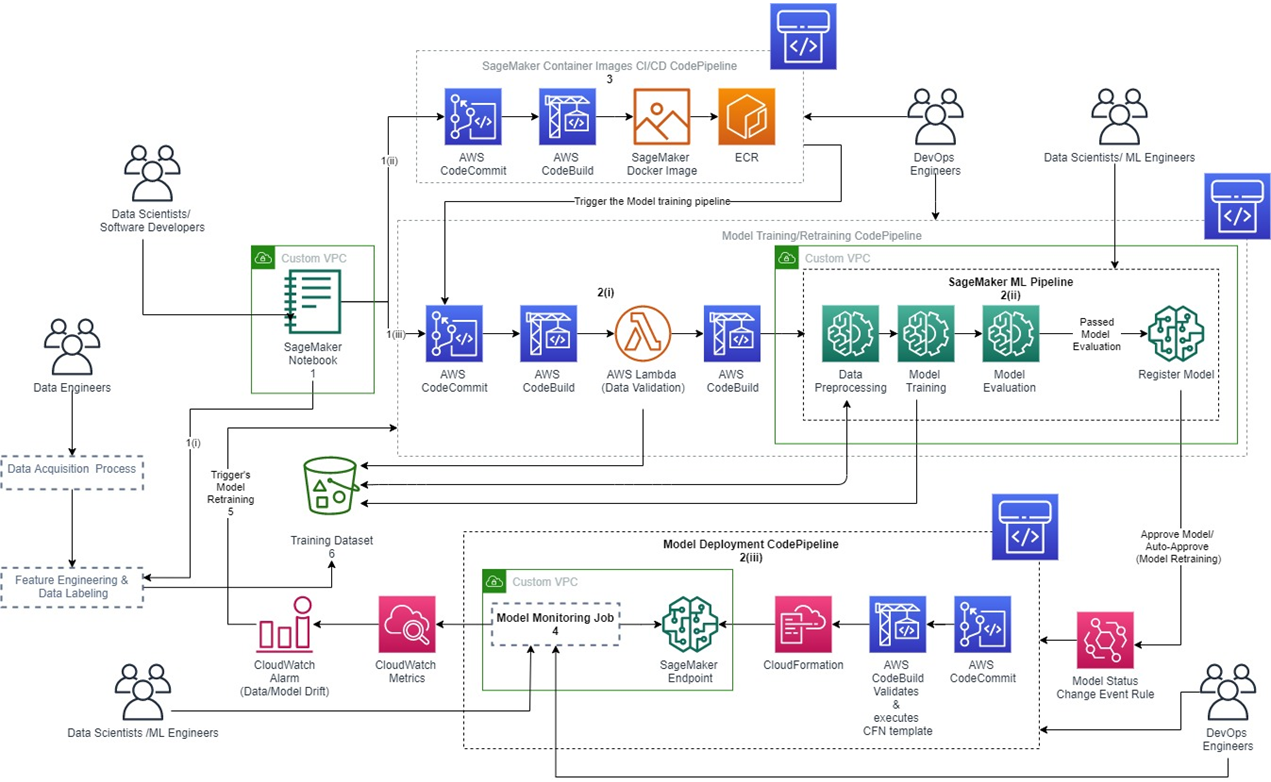
*图片来源:使用 MLOps 在 AWS 上驯服机器学习:参考架构
服务介绍
在架构图当中,除了pipeline之外,也可以看到几个不同颜色的方格,代表不同性质的AWS服务,举例来说:
(1)绿色的方块,与资料储存、模型开发相关,相关的服务有SageMaker、S3。其中Amazon SageMaker属於专门为 ML 所搭建的服务,其包含一系列广泛的功能,协助资料科学家和开发人员快速准备、建置、培训和部署高品质的机器学习 (ML) 模型。而Amazon S3则是Amazon Simple Storage Service的缩写,用来做物件储存服务,可放置不同类型的物件,并能够在上面做备份、还原、版本控制等等。
(2)蓝色的区块则是属於基础架构的服务,架设CI/CD pipeline,相关的服务有CodeCommit跟CodeBuild。其中AWS CodeCommit,属於私有托管的Git储存服务,用於存储、跟踪和版本更改 ML 代码的版本控制系统,与其他AWS服务的高整合,而有更快速的开发周期。AWS CodeBuild可以用来建立持续整合与部属的服务,管理、发布到多个不同的开发环境。
(3)橘色的ECR跟SageMaker Docker image则是用来让你能够使用预设image,然後可以根据建置好的image推送到ECR。Amazon ECR是Amazon Elastic Container Registry的缩写,为大家所开发的Docker image提供托管服务,能够在上面存放、管理、共享及部署容器映像(docker image)。
(4)粉红色的方块,与系统监测、通知有关,也有部署架构的配置,相关的服务有CloudWatch、CloudFormation。Amazon CloudWatch是AWS上面集结所有服务的日志的地方,可以透过cloudwatch观测系统现况、透过日志、指标和事件的形式来收集监控和运作资料。AWS CloudFormation,透过将服务的部属配置放在同一个档案,让开发人员轻松建立相关 AWS 和第三方资源服务集合集合,达成基础设施即代码 (IaC, infrastructure as code)的服务。将专案所需的资源可以透过程序码配置以及版本控制。
在知道每一个pipeline、每一个架构图中的服务与功用之後,如果不想选择全托管的服务,也可以自行抽换成其他提供类似功能第三方服务,或者自行架设该服务做取代。
执行细节
1. 网路安全性
透过security group和自定义VPC设定来确保网路使用的安全性。并将ML专案的服务发布到私有网路内,并透过部署模板来发布所需资源。将 Amazon SageMaker 的专案发布在AWS Service Catalog中。
2. 容器化机器学习、模型监控和自动化
从系统维护面来说,不管是ML服务或是软件服务,尽可能的让这些服务容器化。这样在AWS、其他公有云、私有云或本机的环境,只要是容器可以运作的环境,都可以轻易地重新实现服务。
透过Amazon SageMaker Model Monitor进行模型监控,可以观察数据漂移、模型漂移、模型预测的偏差和特徵属性的漂移这几个指标。
透过容器化以及模型监控,可以协助ML系统完成更高程度的自动化。
3. ML服务选择
在这个专案当中有使用到的ML服务只有提到Amazon SageMaker,不过在所有的AWS AI服务当中,还可以细分为三个不同的层级:
-
AI 服务:相较於後面两者,使用AI服务的门槛相对低,如果有符合的情境以及适合的资料,便可以使用预先训练好的模型。在AI服务由几个不同的服务所构成,开发者能够透过 API 呼叫将 ML 功能快速新增到当前的专案当中。举例像是提供电脑视觉服务的Amazon Rekognition和文字分析服务的Amazon Comprehend。
-
ML 服务: AWS 提供托管服务和资源(例如Amazon SageMaker),资料科学家可以透过此服务进行各种ML工作的开发,例如标记资料集、构建、训练、部署和管理训练好的 ML 模型等等。也可透过ML 服务优化资料科学家的工作体验,可以专注在使用情境跟交付价值上。
-
ML 框架和基础设施:也有开发者使用TensorFlow、PyTorch 和 Apache MXNet 等开源框架在开发模型,这些团队则属於第三类型。可以使用深度学习容器(DLC)来构建、训练和部署 ML 模型。
一个专案的ML服务可以从这三者选其一,也可以依照情境,组合所需要的服务和基础架设。
4. 启动再训练
对於模型上线之後,什麽时候要再训练,这边提供三个方式:
- 预定:在预定时间启动模型再训练过程,例如每一周,每两周等等这样的时间间隔。可使用Amazon EventBridge或是其他排程来预定事件来实施。
- 事件驱动:比如说当新的数据累积到一定的数量,当这样的事件发生的时候,触发启动下一次的模型训练。这个也可以透过Amazon EventBridge来设定。
- 指标驱动:这一项则是透过指标的监控,来触发下一轮模型训练。CloudWatch 本身是AWS上面的日志收集服务,开发者可在上面设定警报(alert),如果该警报发生就会触发模型重新训练过程。这个方式可以完全自动化在模型漂移的校正工作上。
结论
透过上一篇与这一篇的分析,相信大家对於案例的学习有更深一步的学习。接下来也会带大家看其他的案例参考。
<<: Day 0xA UVa490 Rotating Sentences
Day29 Swagger
年轻人不要看到标题就兴奋好吗? 以目前前後端分离的趋势,前端及後端工程师势必会由两个人以上来担任,那...
(笔记D2) Spring MVC 框架处理流程
2-1 使用 Spring MVC 框架提供的分派器(Dispatcher Servlet), 处理...
[day-13] Python 内建的数值类函式
Python 内建的数值类函式 数值类函式 执行结果 功能 abs(-10) 10 取绝对值 min...
Day18 如果你愿意一层一层一层的剥开我的心
Pivot 今天继续来研究PivotTable.js(Gittub)是怎麽写的,我们来研究它所提供...
[Day 10] 从零开始的股票预测 - 基本面
一、基本面 基本面分析是一种证券或股票估价的方法,利用财务分析和经济学上的研究来评估企业价值或预测证...