DAY08 资料前处理-缺失值处理方法
前面我们介绍了如何使用探索性分析(EDA)来观察资料的型态,也学会用图表来找出这些资料的潜在讯息,今天我们就要开始对资料进行处理,不罗唆我们直接进正文。
一、缺失值(Missing Value)
缺失值(Missing Value)指的是在蒐集数据的过程中发生人为或机器上的疏失,导致资料缺失的情况。
根据缺失的特性,缺失值的种类可以分为以下几种:
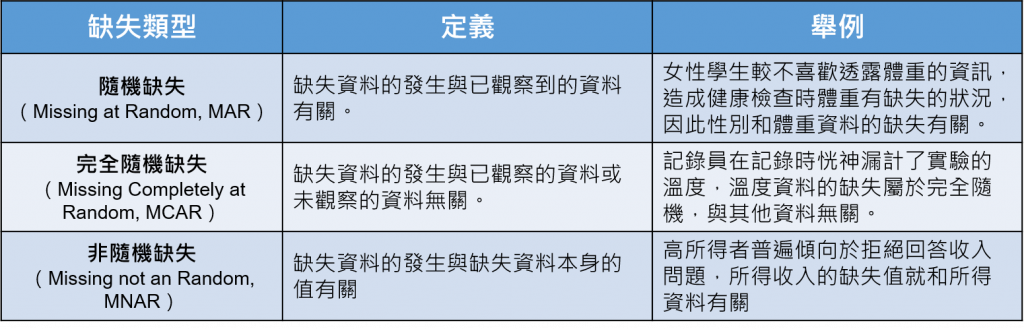
在现实生活中,我们所获得的资料发生缺失值的情况是相当正常的,那为什麽我们需要处理缺失资料呢?最直观的答案就是我们不处理的话,演算法是无法正常运作的。
二、缺失值处理方法
缺失值的处理方法为删除与补值,需依照资料的特性选择较合适的处理:
-删除
直接删除有缺失值的资料样本
▲优点:
做法简单
▲缺点:
可能会遗失重要资讯
若删除资料与其他变数有关,会影响整体资料
-补值
▲以一个固定值去填补,例如全部补0
▲依照时间顺序去补值(跟时间序列有关的资料)
▲依照现有资料的平均值、中位数、众数...等去补值
▲透过机器学习的预测方法去补值
三、范例(铁达尼号生存预测)
下面我们将使用"Titanic生存预测"这个资料来做示范,让大家也能一起动手尝试。
这是个典型的资料集,几乎每个初学者都会透过这个资料集进行第一个专案练习,此资料分析目的在於透过铁达尼号船上一些船课的资料来预测乘客最後是否生还,对於初学者来说非常容易上手。
下载完毕以後开启Jupyter Notebook并将资料集上传至环境

import我们需要用到的套件
import pandas as pd
import numpy as np
使用pandas的功能读入资料集
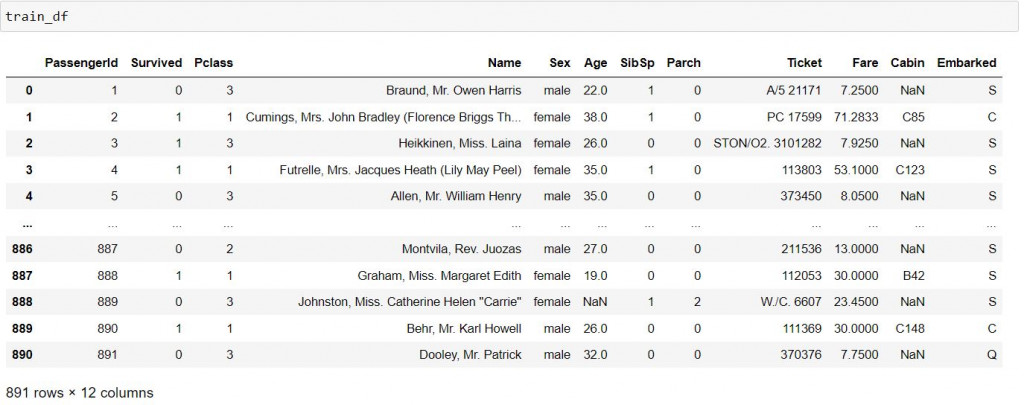
train_df = pd.read_csv('train.csv')
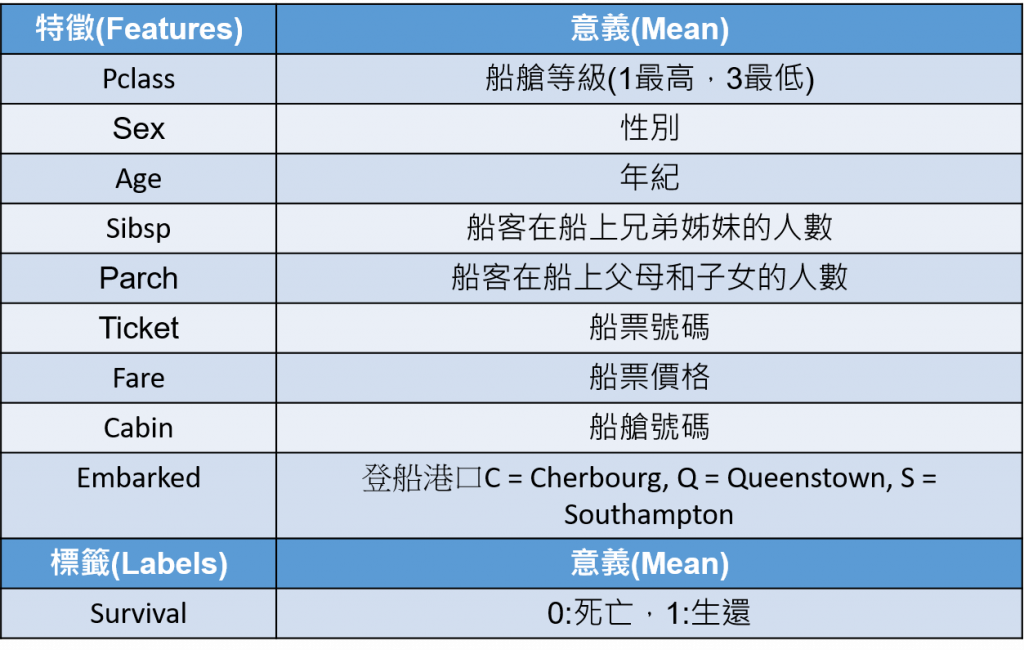
可以看到这笔资料共有891笔资料,11种特徵+是否生还的标签(0、1)
帮大家整理成表格比较好理解
找出含有缺失值的特徵
train_df.insull().sum()
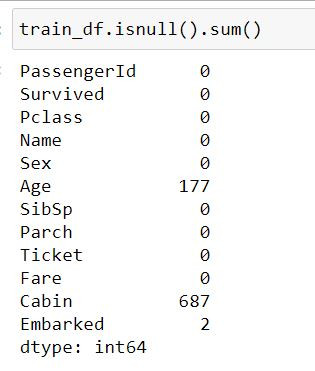
这里也给大家一个能够视觉化成表格的def
def Missing_Counts( Data, NoMissing=True ) :
missing = Data.isnull().sum()
if NoMissing==False :
missing = missing[ missing>0 ]
missing.sort_values( ascending=False, inplace=True )
Missing_Count = pd.DataFrame( { 'Column Name':missing.index, 'Missing Count':missing.values } )
Missing_Count[ 'Percentage(%)' ] = Missing_Count['Missing Count'].apply( lambda x: '{:.2%}'.format(x/Data.shape[0] ))
return Missing_Count
Missing_Counts(train_df)
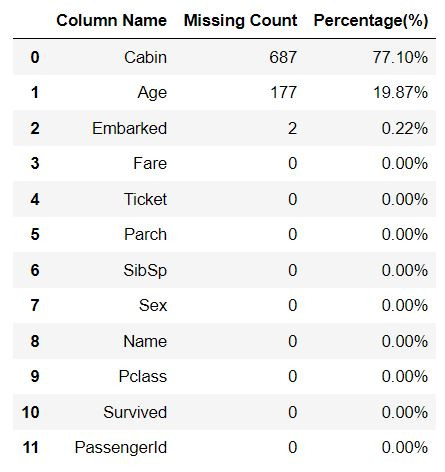
首先我们可以看到Embarked的缺失数量非常少,只有2笔而已,我们可以选择简单填补或删除,那这边示范删除的方法,其实非常简单,只要一行程序即可。
train_df=train_df.dropna(subset=["Embarked"]) #subset参数里面放要删除缺失值的特徵
删除两笔资料後,总资料数下降为889笔。接着我们处理缺失将近77%的Cabin资料。
查看Cabin的资料类型分布
train_df['Cabin'].unique()

像这种属於完全随机缺失的资料不太好进行补值,假如删除的话也会遗失过多资讯,因此我的作法是自行给定一个值"No_Cabin"代表缺失船舱号码的乘客来进行补植。
train_df['Cabin']=train_df['Cabin'].fillna("No_Cabin")
接着我们处理年龄(Age)的部分
年龄的处理就比较麻烦了,缺失了将近20%的资料外,年龄会受其他变数的影响,例如年纪较小的人可能会有家长陪同(Parch),逃生时可能会优先,存活机率也相对大。因此我们需要比对其他变数对年龄的影响来做补值。
利用箱形图查看Age与Sex的关系
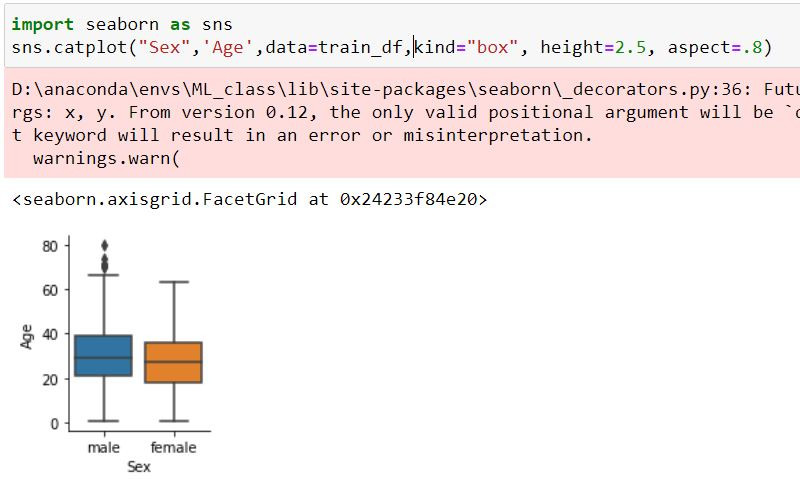
可以发现不论男女在各年龄层都有族群存在,Sex不太能做为补值参考
观察缺失资料在船舱等级(Pclass)的分布
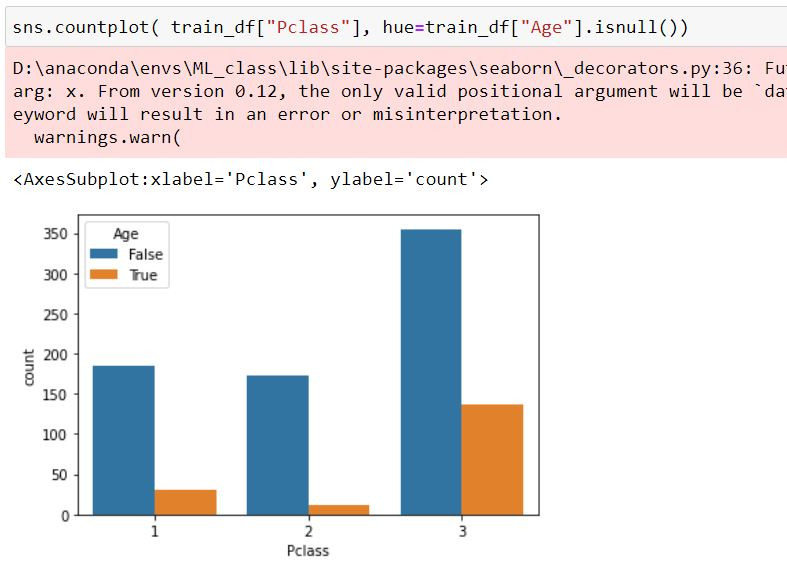
发现大部分的缺失状况都是出现在3等舱中
观察Age和Survived的相关性
index_survived = (train_df["Age"].isnull()==False)&(train_df["Survived"]==1)
index_died = (train_df["Age"].isnull()==False)&(train_df["Survived"]==0)
sns.distplot( train_df.loc[index_survived ,'Age'], bins=20, color='blue', label='Survived' )
sns.distplot( train_df.loc[index_died ,'Age'], bins=20, color='red', label='Survived' )
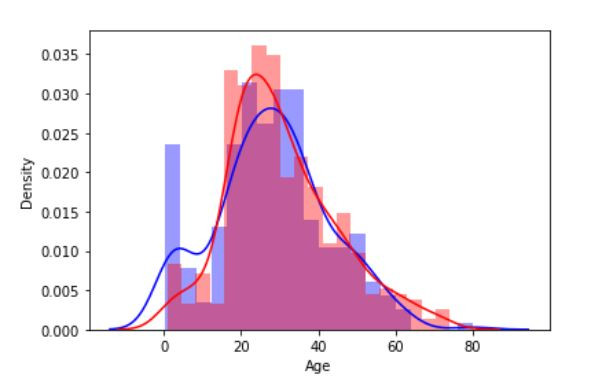
可以看到有较明显生存率的年龄分布是10岁以下、17岁、26岁左右的年龄(蓝色较高的)
Age和Name的相关性
外国人的称谓和职业、年纪多少会有点关系,因此我们先处理Name这个栏位,将姓氏取出,命名为新的特徵"Title"
train_df['Title'] = train_df.Name.str.split(', ', expand=True)[1]
train_df['Title'] = train_df.Title.str.split('.', expand=True)[0]
train_df['Title'].unique()

计算每个Title的年龄平均
# 计算每个 Title 的年龄平均值
Age_Mean = train_df[['Title','Age']].groupby( by=['Title'] ).mean()
Age_Mean.columns = ['Age_Mean']
Age_Mean.reset_index( inplace=True )
display( Age_Mean )
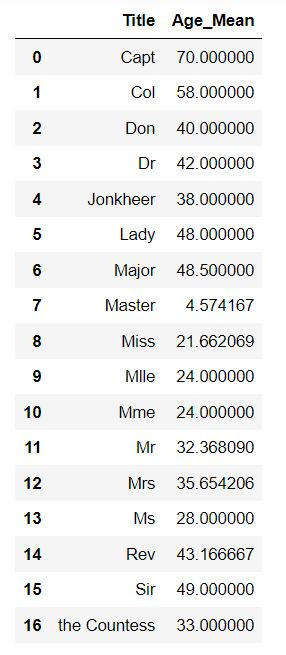
根据缺失值的Title所对应的平均进行补值
train_df=train_df.reset_index() #重整index
train_df["Age"].isnull()
for i in range(len(train_df["Age"].isnull())):
if train_df["Age"].isnull()[i]==True:
for j in range(len(Age_Mean.Title)):
if train_df["Title"][i]==Age_Mean.Title[j]:
train_df["Age"][i]=Age_Mean.Age_Mean[j]
这样一来缺失值就填补完毕啦,最後我们确定一下
四、结论
今天我们介绍了缺失值的原因、类别以及一些简单的处理方法,其实这些都算是皮毛而已,缺失值填补的学问可是非常大的,有兴趣的朋友可以找一些Paper来看,小编想说的是,缺失值的填补没有一种方法是绝对的,我们也很难去验证我们填补的值是否正确(毕竟资料就遗失了,对照不了),所以我们只能透过分析相关性,用比较合理的方法去还原本来的资料,最後希望大家都有从中受益啦!
>>: [CSS] Flex/Grid Layout Modules, part 3
JS DOM(文件物件模型)
DOM(Document Object Model) 文件物件模型 今天简单聊聊之後要进入的主题,D...
JS 18 - 阵列也有赝品?如何辨识伪造的阵列?
大家好! 昨天我们建立了看似阵列的物件,其实它就是接下来要介绍的伪阵列物件(Array-like O...
AE卷轴制作1-Day2
练习范例教学 六指渊:https://www.sixvfx.com/rolling_paper 开始...
Day26:Dynamic Programming(DP) - 动态规划(下)
Dynamic Programmin的经典应用除了斐波那契数之外,还有背包问题、最短路径问题、河内...
[Day 25]从零开始学习 JS 的连续-30 Days---addEventListener 事件监听
addEventListener 事件监听 JavaScript 是一个事件驱动 (Event-dr...