DAY06 探索性资料分析
一、当拿到资料後
1.问自己,想要这笔资料为你做什麽?
举例来说,今天你拿到一笔资料,老板要你去预测员工明年有谁会离职?这时候你就可以先想,什麽因素是平常导致离职的关键,例如加班时间过长、薪水太低等。在开始做之前先有一个目标,到後面就不至於会手忙脚乱。
2.观察资料型态
资料分成结构化跟非结构化。若拿到结构化的资料,要去了解每个特徵所带来的含义,而若拿到非结构化的资料,要将资料作转换後才能拿来做分析,结构化与非结构化资料的差异举例如下:
- 结构化:数值、类别型资料、表格...
- 非结构化:图像、影片、文字、音讯...
3.判断资料是什麽类型的问题
一般来说,会遇到的问题不外乎就是分类(Classificaction)、回归(Regression)两大类问题,而什麽是分类及回归问题呢?举例来说:我们要预测员工是否离职,这种有标签的预测就属於分类问题。而预测当地房价,预测出来的是连续的数值,就是回归问题。
4.了解资料个特徵所代表的含义
通常比赛资料会给你每个特徵栏位所代表的意义,有可能是直接写在网站上,有可能另外给你一个档案,在拿到资料後记得要先了解资料特徵所代表的含义,会需要了解是因为做资料分析的时候,不一定所有的资料集都与你的领域有相关,最大化的去了解有助於下一步的分析。
二、观察资料
1.是否有缺失值
通常我们拿到的资料不一定是一份完整的资料,这时候要去观察资料中的空值有多少,去决定後续做资料前处理时该用什麽方法去补值。
df_train.isnull().sum() #检查df_train这笔资料缺值数量
2.资料是否存在离群值
举例来说有一笔资料叫台湾天气温度,而资料中有一笔资料显示1000度,但正常来说台湾根本不会有1000度的天气,这笔资料就是所谓的离群值,通常我们会搭配视觉化来找出离群值,而离群值若没处理好,会大大的影响後面分析的结果,所以在前面一定要好好的观察资料。
通常离群值要搭配统计图比较容易观测的出来,这部分留到之後再一并说明。
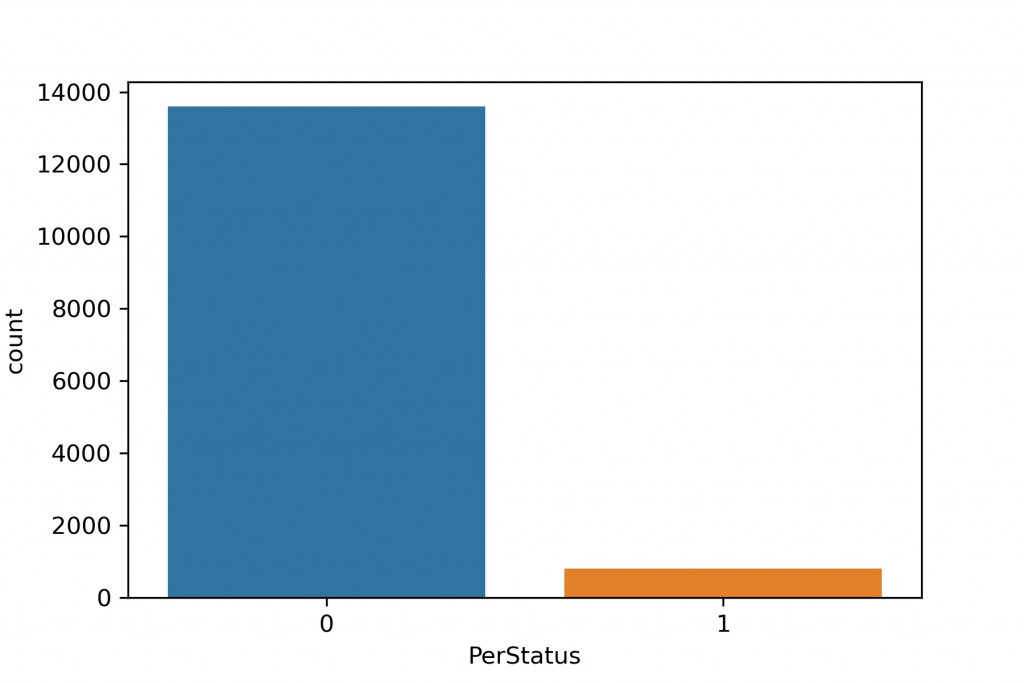
3.资料分布情况
通常我们比较常遇到的是资料不平衡的问题,这部分没处理好有可能会让模型训练出问题,後面在做资料前处理的时候会再提到解决的方法。
df_train["feature_name"].value_counts() #计算feature_name这个特徵数量有多少
4.资料是离散型资料还是连续型资料
-
离散型资料:举例来说,班上男生有几个,女生有几个就是离散型资料
-
连续型资料:而男女生身高资料分布即为连续型资料
而下一章会以图来详细说明。
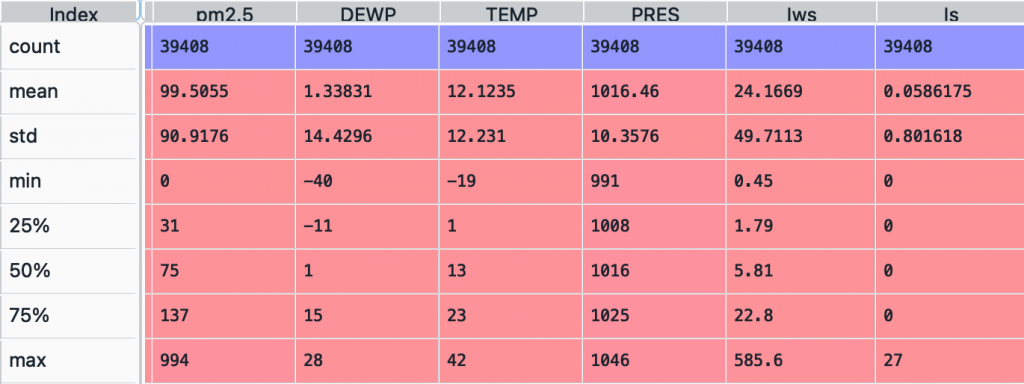
5.叙述性统计
透过叙述性统计,呈现出各个特徵的统计资讯,让你对资料有初步的掌握
- count:让你知道资料有几笔
- mean:各个特徵的平均数
- std:各个特徵的标准差
- 四分位数:最小值、Q2、Q3、最大值
注意这个并不是每种资料都适用,像一些离散型的资料,用这个方法观察是没有意义的,因为资料间是彼此独立,把它平均是没有任何意义的。
以天气资料为例
资料集来源:https://www.kaggle.com/djhavera/beijing-pm25-data-data-set
df_train.describe()
三、结论
透过以上步骤是不是对资料的掌握度变得更高了呢?大家快去网路上找资料来实际做看看。记住!对资料的掌握度越高,後面的步骤做起来就会越加顺手。
<<: [Day 6] Course 2_Ask Questions - 有效的提问并做资料导向决策
>>: [Day-6] R语言 - 怎麽选 分群群数 & 距离? ( Clustering Distance & Index )
04 - Tmux - 终端机管理工具
在开发时,常常需要多个指令同时运作(例如一个启动前端专案、一个启动後端专案),因此会需要同时开启多个...
Day 27:我们又回来了redux
来最後几天我们又跳回去React-Testing-Library XDDD 相信还是有很多公司使用r...
[Java Day25] 6.2. 改写
教材网址 https://coding104.blogspot.com/2021/06/java-o...
Laravel:Route Wildcards 2
前言 Laravel:Route Wildcards - iT 邦帮忙::一起帮忙解决难题,拯救 I...
[Vue2] 从初学到放弃 Day7-怎麽变化里面的值
先用官网里面的范例 <div id="example"> <p...