DAY04 浅谈资料科学与Machine Learning
一、何谓资料科学
资料科学白话来讲,就是透过资料数据来解决问题的一门科学,我们在得知客户的需求、环境限制等因素後,利用能蒐集到的资料建立一套「模型」,透过模型的计算来分析问题及解法,透过此解法则可挖掘问题背後的商业价值。
二、资料科学领域
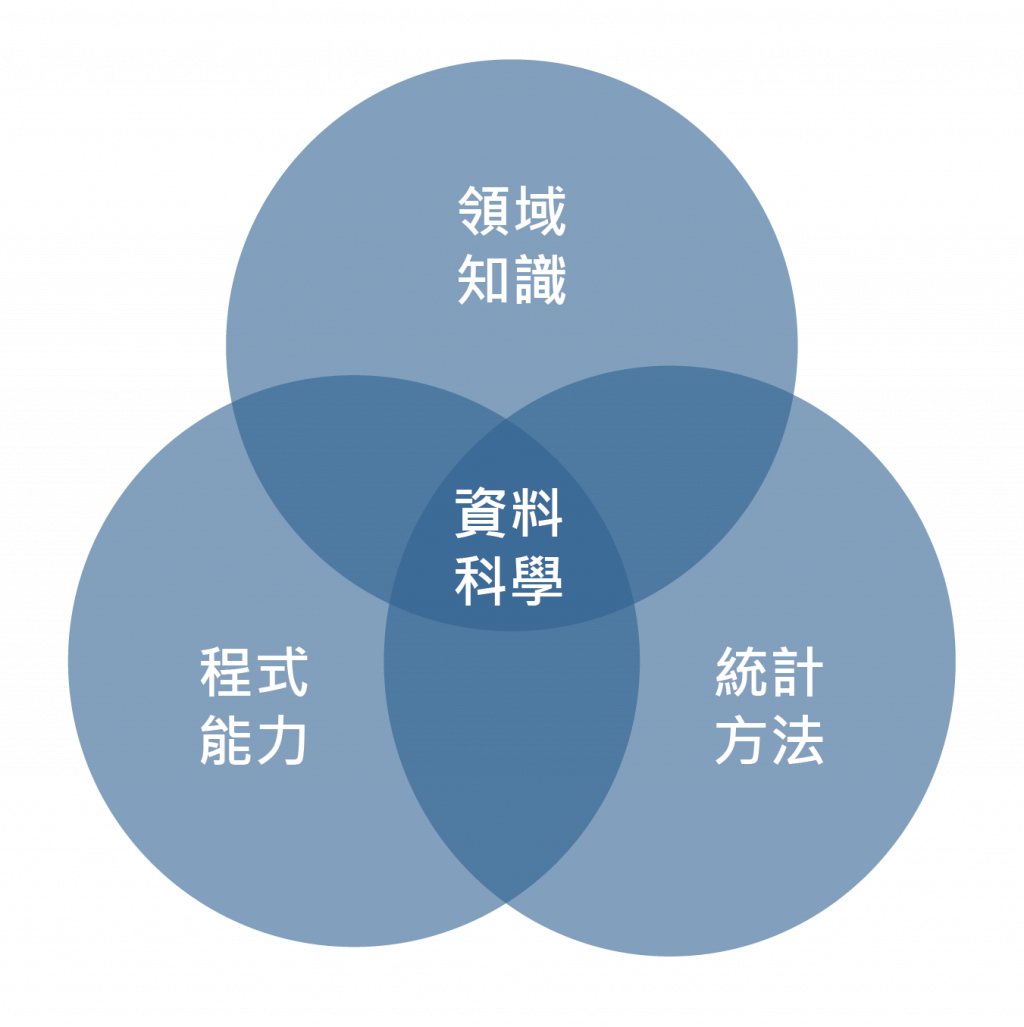
而资料科学的领域包含了领域知识、统计方法和程序能力,三者缺一不可,要想成为该领域的资料科学家,除了须有该领域的知识外,还需透过统计方法和程序能力系统化的呈现资料科学的效益。
三、机器学习(Machine Learning)
机器学习为人工智慧(AI)领域的一个分支,即机器透过学习资料的经验找到资料运行的规则,并改善演算法的效能,是一种对复杂系统建模的替代方法,例如机器人透过阅读无数棋谱来决定下一步棋该如何下才能达到最大效益,而机器学习的问题可以分为以下几个种类:
1. 监督式学习(Supervised Learning)
监督式学习的资料集包含(X,Y),X为各项特徵,Y为Label,或是统计所说的应变量。
若Label的类型为类别型资料(Categorical),称为"分类问题",Ex:制程良率分析(Good/Bad)
若Label的类型为连续型资料(Continuous),称为"回归问题",Ex:股价预测(股价为多少)
2.非监度式学习(Unsupervised Learning)
资料集中只有特徵而没有特徵,演算法仅能根据特徵区分种类,用於分群分析(Clustering)。
Ex:判断金融交易是否异常(诈欺状况)
四、机器学习哪些资料
要进行资料分析,我们不可能完全都靠人力,而是让机器学会我们人类的概念想法,并以高效率的工作方式实现他。那资料是透过什麽学习的呢?没错!就是经验,而经验来自大量的资料,今天我们想要透过一份身体资料预测一个人是男是女,我们可能会先蒐集大量的人类男女资料,并让机器去找到一些关键影响性别的因素,也就是我们常说的特徵(Features),例如:身高、体重、体脂...等等,所以不管我们要分析什麽或是预测什麽,拥有一个好的资料集是很重要的首要步骤,拥有越多的数据资料,便能归纳得出更好且更精准的结果!
五、结论
我们来总结一下机器学习的问题类型:
1. 分类(Classificaction)
瑕疵分类(Defect Classification)、异常检测(Anomaly detection)、好坏分类(Good/Bad Classification)
2. 回归(Regression)
产量预测(Yield Prediction)、虚拟计量(Virtual Metrology)
3. 诊断(Diagnosis)
相关性(Correlation)、优先级(Prioritization)
4. 分群(Clustering)
相似性搜索(Similarity Search)、分组(Grouping)
5. 最佳化(Optimization)
运作优化(Operation Optimization)、参数优化(Parameter Optimization)
6. 预测(Prognostics)
预测性维护(Predictive Maintenance)、敏感性分析(Sensitivity Analysis)
介绍了这麽多,大家也可以反思一下,是不是所有复杂的问题都适合用机器学习的方法来解决呢?
答案显然是否定的,适合使用资料分析/机器学习的问题特性应该有下列几点:
1.衡量的指标可以改进
2.没有明确的规则
3.有预期的资料
在遇到资料科学的问题时,大家不妨也可以先想想这个问题的本质,是不是符合以上三点,"知己知彼才能百战百胜",只要了解资料的特性以及问题的本质,做起资料分析就可以事半功倍了!
>>: 前端工程师也能开发全端网页:挑战 30 天用 React 加上 Firebase 打造社群网站|Day4 制作标题导览列
[Day 3] Reactive Programming - Functional Programming
前言 并不是说Reactive 一定要搭配Functional,只是搭配起来更好用,而後面介绍到的R...
Day 28 Chatbot integration- 汇率预测小工具
Chatbot integration- 汇率预测小工具 丑话先说在前头,模型虽然可以达到一定程度准...
结束了!!
我大学读树德资工系,但我大学快升大四时我才认真的学习。我那时主修网路,觉得喔~网路就这样而已,但是我...
[C 语言笔记--Day06] 解题纪录:MAX-MEX Cut
题目:https://codeforces.com/contest/1566/problem/C 题...
[13th-铁人赛]Day 1:Modern CSS 超详细新手攻略 - 简介
嗨大家,我是 Ronnie! 这是我第一次参加iT铁人赛,在开始前先帮我自己订一个小小目标,就是希望...