[Python]专题P01─台湾春节国道预估塞车时间准不准?
Hi! 大家好久不见,我是Eric。真的是时隔多日,我们的网站终於又更新啦!这次要练习运用Python中的matplotlib套件来做一个小专题,继续来看下去
[缘起] :每逢春节过年,高速公路局都会提前公布国道预估塞车的时段给大家参考,那到底准不准呢?这次,我们就要来用Python来检验看看。这次要看的是最近3年(2019-2021)的初一。
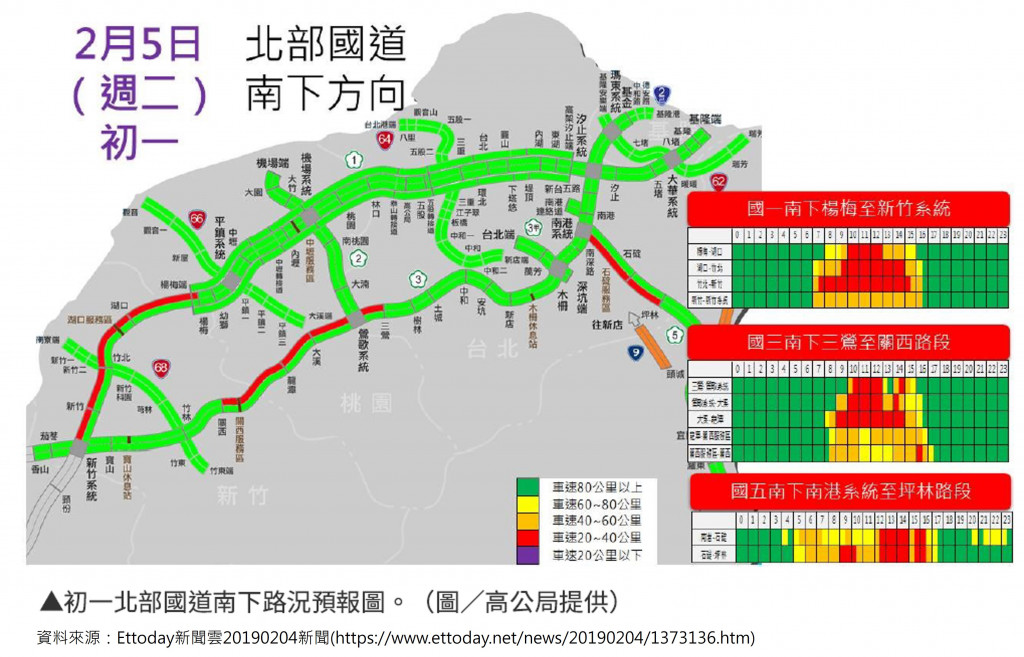
2019年初一预估塞车时段最久的是南下竹北-新竹(07:30-13:30),如下图:
2020年(X) Covid19年(O) 初一预估塞车时段最久的是南下南港系统-石碇(06:00-16:30),如下图:
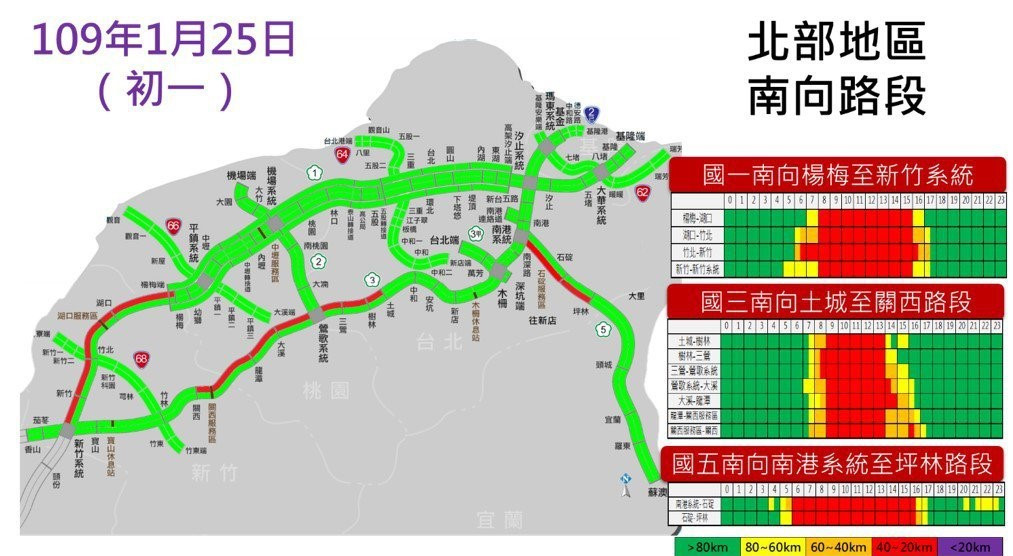
资料来源:交通部高速公路局
2021年初一预估塞车时段最久的是一样是南下南港系统-石碇(05:30-15:30),如下图:
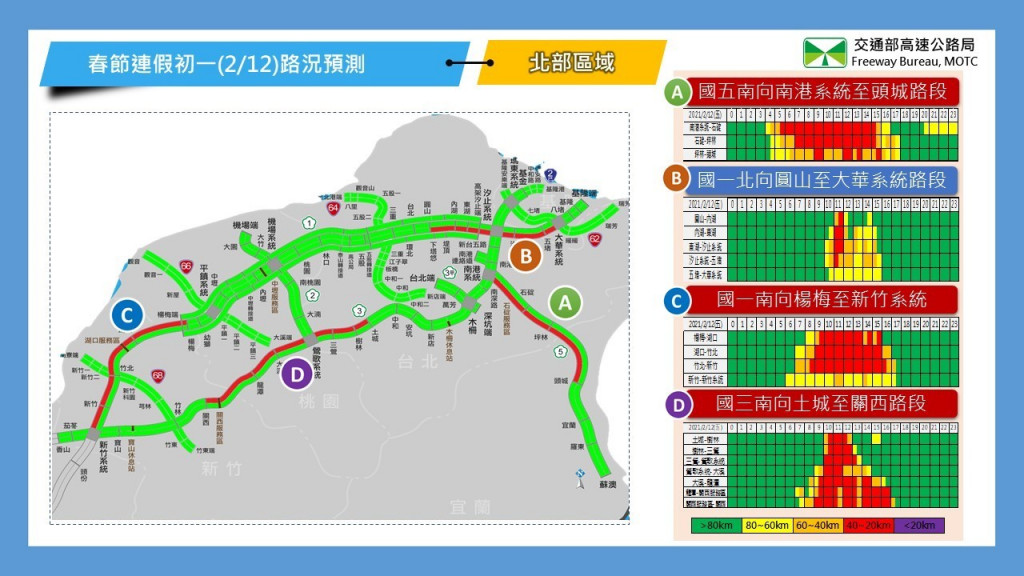
资料来源:大年初一下午再出门 记得避开国道六大地雷路段(2020-01-24 15:38:12联合报 记者侯俐安/台北即时报导)
[方法] :运用[Python]的[pandas、matplotlib]套件。
[使用资料] :交通部高速公路局交通资料库ETC(Electronic Toll Collection )资料─各类车种通行量统计(TDCS_M03A),2019-2021年。
[参考资料] :
1.资料科学家的pandas实战手册:掌握40个实用数据技巧https://leemeng.tw/practical-pandas-tutorial-for-aspiring-data-scientists.html
2.[Python资料科学]用Pandas分析资料— 资料的聚合
https://medium.com/seaniap/%E7%94%A8pandas%E5%88%86%E6%9E%90%E8%B3%87%E6%96%99-%E8%B3%87%E6%96%99%E7%9A%84%E8%81%9A%E5%90%88-e08f1b1504ed
以下程序范例为以2019年为例,其余2年只差在年份与目标路段喔,大致上流程都一样。
1. 载入资料
import pandas as pd #载入pandas资料处理套件
from glob import glob #载入glob回传资料路径套件
files = glob("C:/Users/Eric/Desktop/Python/M03A_20190205/TDCS_M03A_20190205_*.csv") #以glob函数来取得资料夹中所有开头为TDCS_M03A_20190205_的资料
df = pd.concat([pd.read_csv(f,header=None) for f in files],ignore_index=True) #以concat函数,并配合列表推导,将同一个资料夹内所有档案一次载入,同时设定以资料没有栏位名称的方式
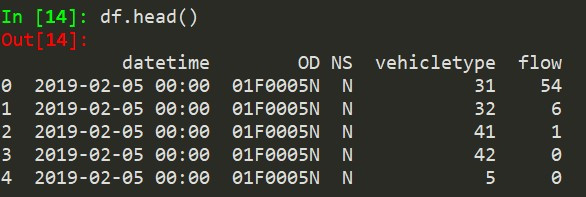
df.head() #先偷看一下资料长相,如图1
图1
2. 资料前置处理
df.columns = ["datetime", "OD", "NS", "vehicletype", "flow"] #命名栏位名称
df_05 = df[df["OD"] == "01F0928S"] #将目标路段(国五南向竹北-新竹)筛选出来,并储存於另一个资料框
df_05.head() #再偷看一下资料长相,如图2
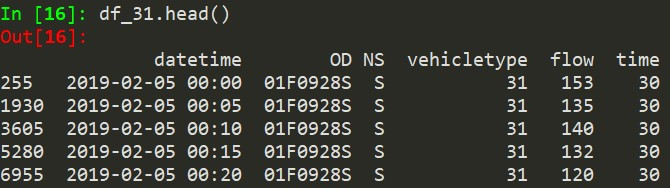
df_31 = df_05[df_05["vehicletype"] == 31] #将目标车种(小客车)筛选出来
df_31.head() #再...看一次就好,如图3
图2
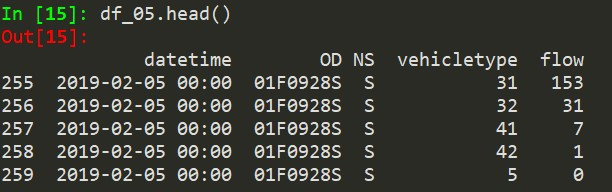
图3
3. 产生x轴时间区间(由於原资料每5分钟时间间隔区分太细,不利於视觉化呈现,以每30分钟间隔分组取代,并把每个分组的车流量加总起来,如01:35-02:00这6笔资料,都分为20:00这组)
#原资料间隔是每5分钟,为了简化资料,改以30分钟为间隔,故需要合并资料,前面的7笔(00:00-00:30)与後面的5笔(23:35-23:55)除外,中间资料均为每6个一组,如00:50-00:30组成一组,组名叫0030
num1 = [i for i in range(100,2400,100)] #产生100、200...2300的整点时间
num2 = [i for i in range(130,2430,100)] #产生130、230...2330的半点时间
temp = []
import math #载入要四舍五入函数的套件
#首先处理中间时间(除了前面7笔与後面5笔之外的资料),总共有46个时间,先依据是否可被2整除来依序放到列表中,藉此串起来,产生100、130、200、230...2330的资料
for i in range(0,46):
if i % 2 == 0:
temp.append(num1[i//2])
else:
temp.append(math.ceil(num2[i//2]))
temp2 = [i for i in temp for j in range(6)] #让中间时间每个都重复6次
num3 = [30]
temp3 = [i for i in num3 for j in range(7)] #让前面的时间重复7次
num4 = [2400]
temp4 = [i for i in num4 for j in range(5)] #让後面的时间重复5次
time = temp3 + temp2 + temp4 #把所有时间串在一起
len(time) #检查时间总数是否相同,前面有7笔,中间46笔重复6次,後面有5笔,所以总计有288个
df_31_addtime = df_31 #复制原始资料,以备後续要加入新时间栏位
df_31_addtime["time"] = time #将以30分钟为间隔的新时间加入原表格,并命名为time栏位
df_31_addtime_group = df_31_addtime.groupby("time") #依据"time"这个栏位将原资料群组化
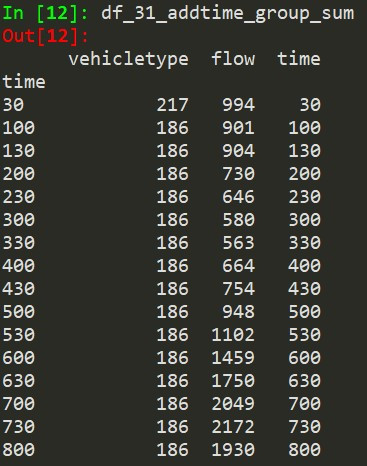
df_31_addtime_group_sum = df_31_addtime_group.sum() #依据各群组计算各栏位总和数值,并另外存在新变数中,如图4
#因之前群组化时是依据新时间分组,故原本新时间分组已经被用掉了,故要再新增一次作为之後画图的x轴
temp5 = num3 + temp + num4
df_31_addtime_group_end = df_31_addtime_group_sum
df_31_addtime_group_end["time"] = temp5
图4
5. 资料视觉化
import matplotlib.pyplot as plt #载入画图套件
plt.style.use("ggplot") #设定要运用叫做ggplot的主题
#画第一条线,plt.plot(x, y, c)参数分别为x轴资料、y轴资料及折线的颜色 = 蓝色
plt.plot(df_31_addtime_group_end["time"], df_31_addtime_group_end["flow"],c = "blue")
#设定y轴坐标轴范围,调整图的呈现
plt.ylim(400, 2500)
# 设定图例,参数为标签、位置
plt.legend(labels=["2019"], loc = 2)
plt.xlabel("Time", fontweight = "bold", ) # 设定x轴标题及粗体
plt.ylabel("Flow", fontweight = "bold") # 设定y轴标题及粗体
# 设定图的标题、文字大小、粗体及位置
plt.title("TWN Highway traffic flow", fontsize = 15, fontweight = "bold")
plt.savefig("2019 TWN Highway traffic flow.jpg", # 储存图档
bbox_inches='tight', # 去除座标轴占用的空间
pad_inches=0.0) # 去除所有白边
plt.close() # 关闭图表
6. 大功告成
2019年:
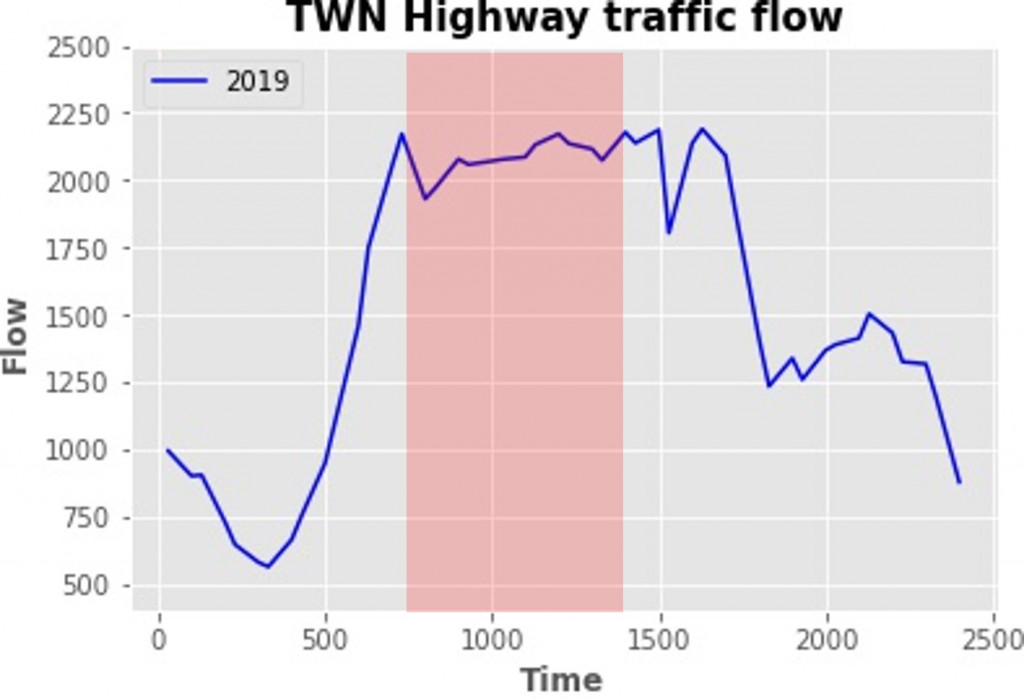
简评:可以看出大抵预估相符,但实际塞车时间较长,约从6点开始一路塞到16点左右。
2020年:
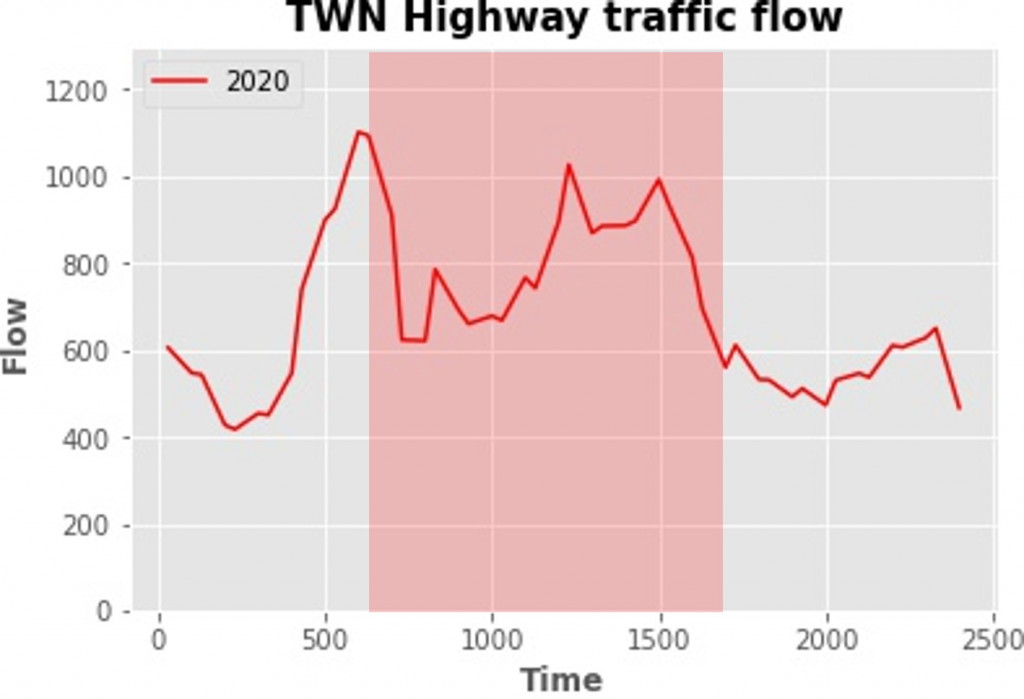
简评:2020年的预估与实际也大致相符,但约6点-11点左右车流明显变少。
2021年:
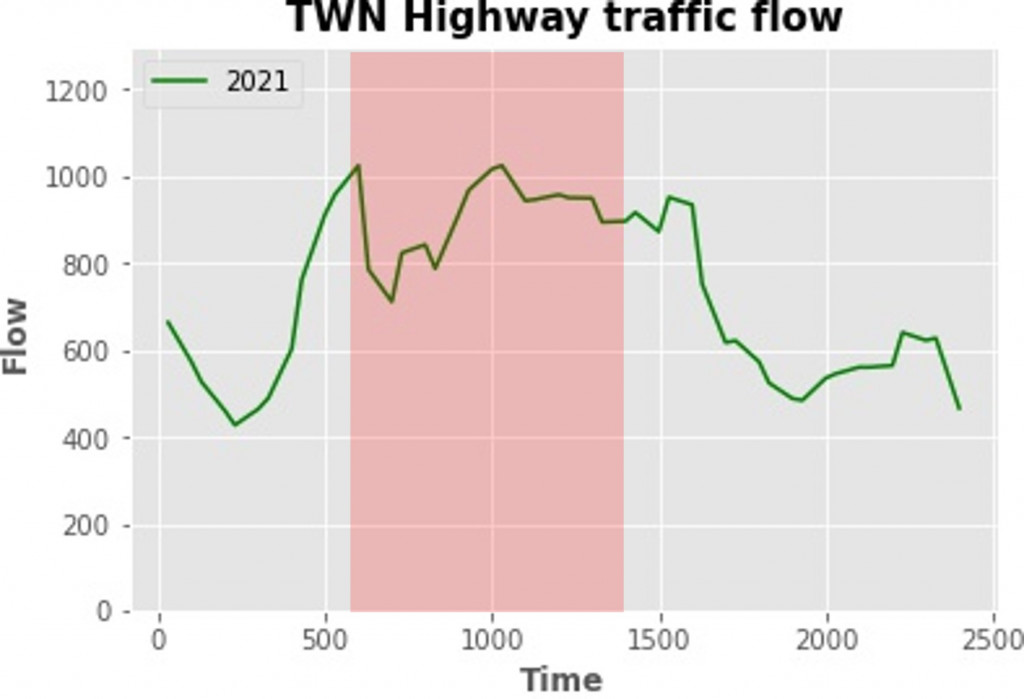
简评:2021年的实际车流时序与2020年几乎相同,均依循着相同的模式。
7. 结论
透过开放资料,我们可以运用Python来自己做一些简单分析,经由最近3年时间,我们可以发现塞车时间通常会较预估的时间区间来得长,所以如果明年也想作为春节出游的参考的话,也可以自己运用Python来当作自己的小助手喔。
[Day21] 回呼函式 Callback Function
先来看看 MDN 的定义。 回呼函式(callback function)是指能藉由 argumen...
DAY21-EXCEL统计分析:单因子完全随机集区实例
某间面包店的面包师傅想研究不同配方做出的面包所销售出的差异,但依照部烤箱的不同温度又会有所不同,故想...
[Day 24] Node Event loop 3
前言 今天继续看看 event loop 的核心循环, uv_run() , 可以查看以下网址 ht...
Day1 Open-Match 简介
在众多游戏类型中,对战游戏类型游戏占有很重要的一席之地。不论是手机游戏市场,还是以电脑为主的竞技游戏...
鬼故事 - 灭证高手
鬼故事 - 灭证高手 Credit: Scooby-Doo 灵感来源:UCCU Hacker 故事开...