【29】遇到不平衡资料(Imbalanced Data) 时 使用 SMOTE 解决实验
今天要介绍处理不平衡资料的方法叫 SMOTE (Synthetic Minority Oversampling Technique),其原理就是透过将少数样本以合成的方式来增加,让资料集变得相对平衡,而这边的合成方式是什麽?并没有一定的方式,以一般资料数值分析为例,它从样本的邻近区间生成一个近似值来当新的少数样本。
但是我们这次要介绍的都是图片相关的分类任务,图片的话要如何合成样本呢?没错!就是使用 GAN 啦!所以今天的实验分成两阶段。
- 先用 GAN 透过不平衡训练集训练生成器。
- 利用上述的生成器产生不平衡的少数样本(数字6,8,9),再进行一次分类训练。
本次文章因为主要想实验利用 GAN 产生的样本能够对训练任务带来多少效益,所以不会着重在 GAN 的讲解上,我们会使用 Conditional GAN ,这种可以指定标签的生成器作为示范,其 Conditional GAN 的程序码我会从 Keras 官方 Conditional GAN 教学文件修改来使用,比较不同的地方是 Keras 范例是使用完整的训练集和测试及产生的,我则是使用6,8,9个只有100笔的不平衡资料来模拟真实情况。
实验一:用 cGAN (Conditional GAN) 直接跑不平衡资料(6,8,9的样本只有100笔)
dataset = tf.data.Dataset.from_tensor_slices((train_images_imbalanced, train_label_imbalanced))
def normalize_img(image, label):
return tf.cast(image, tf.float32) / 255., tf.one_hot(label, num_classes)
dataset = dataset.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
dataset = dataset.cache()
dataset = dataset.shuffle(1000)
dataset = dataset.batch(128)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
cond_gan = ConditionalGAN(
discriminator=discriminator, generator=generator, latent_dim=latent_dim
)
cond_gan.compile(
d_optimizer=tf.keras.optimizers.Adam(learning_rate=0.0003),
g_optimizer=tf.keras.optimizers.Adam(learning_rate=0.0003),
loss_fn=tf.keras.losses.BinaryCrossentropy(from_logits=True),
)
cond_gan.fit(dataset, epochs=20)
产出:
Epoch 30/30
g_loss: 0.7804 - d_loss: 0.6826
和 Keras 官网的 loss 比较,因为我们用不平衡资料,导致生成器(g_loss)偏高。
values = [6, 8, 9]
n_values = np.max(values) + 1
one_hot = np.eye(n_values)[values]
for v in one_hot:
fake = np.random.rand(128)
label = np.asarray(v, dtype=np.float32)
fake = np.concatenate((fake,label))
fake = cond_gan.generator.predict(np.expand_dims(fake, axis=0))
fake *= 255.0
converted_images = fake.astype(np.uint8)
converted_images = tf.image.resize(converted_images, (28, 28)).numpy().astype(np.uint8).squeeze()
plt.imshow(converted_images)
plt.show()
生成器产生的1,2,3:
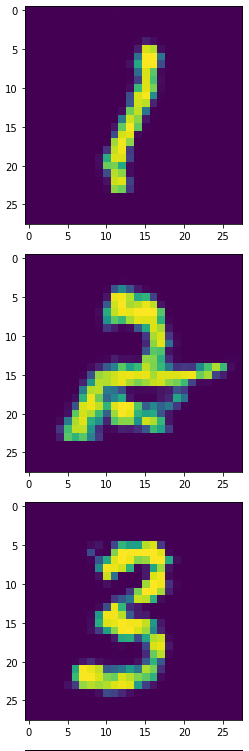
生成器产生的6,8,9:
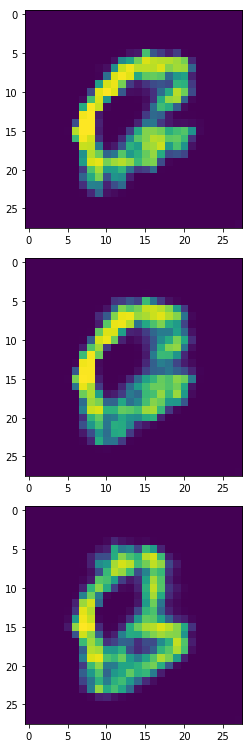
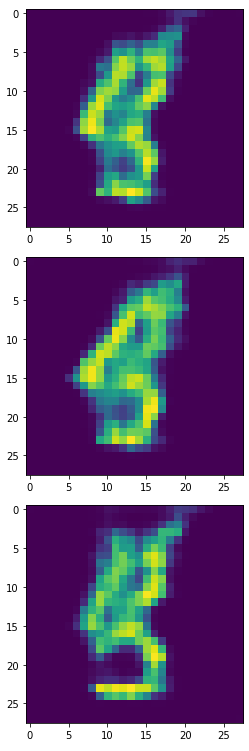
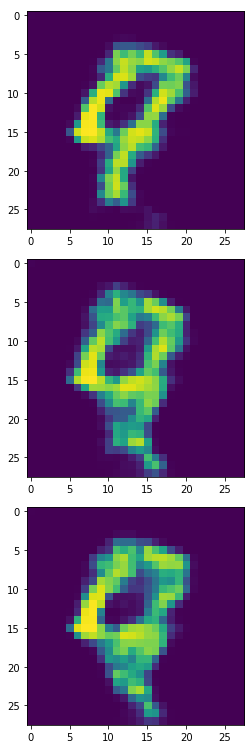
将生成器的6,8,9印出来後,长得很歪...看来我故意挑6,8,9这三组数字是真有搞到模型XD。
虽然这个生成器产生的样本有些奇怪,但我们仍使用这些长歪的6,8,9来做分类任务,我们产生4900个合成样本加上原本100个本来的样本来 Oversampling。
DUP_COUNT=4900
idx_we_want = list(range(sum(counts[:6]))) + list(range(sum(counts[:7]) ,sum(counts[:7])+counts[7])) # [0,5] + [7,7]
train_label_imbalanced = train_labels_sorted[idx_we_want]
train_images_imbalanced = train_images_sorted[idx_we_want]
idx_we_want = list(range(sum(counts[:6]),sum(counts[:6])+100)) + list(range(sum(counts[:8]),sum(counts[:8])+100)) + list(range(sum(counts[:9]),sum(counts[:9])+100))
train_label_689 = train_labels_sorted[idx_we_want]
train_images_689 = train_images_sorted[idx_we_want]
train_label_689_dup = np.asarray([6,8,9]).repeat(DUP_COUNT)
values = [6, 8, 9]
n_values = np.max(values) + 1
one_hot = np.eye(n_values)[values]
train_images_689_dup = np.zeros((DUP_COUNT*3,28,28,1))
for bucket, v in enumerate(one_hot):
for idx in range(DUP_COUNT):
fake = np.random.rand(128)
label = np.asarray(v, dtype=np.float32)
fake = np.concatenate((fake,label))
fake = cond_gan.generator.predict(np.expand_dims(fake, axis=0))
fake *= 255.0
fake = fake.astype(np.uint8)
fake = tf.image.resize(fake, (28, 28)).numpy().astype(np.uint8).squeeze()
train_images_689_dup[bucket*DUP_COUNT+idx,:,:,0] = fake
train_label_imbalanced = np.concatenate((train_label_imbalanced, train_label_689, train_label_689_dup))
train_images_imbalanced = np.concatenate((train_images_imbalanced, train_images_689, train_images_689_dup), axis=0)
train_images_imbalanced, train_label_imbalanced = shuffle(train_images_imbalanced, train_label_imbalanced)
确认一下各个样本数量是否正确
{0: 5923,
1: 6742,
2: 5958,
3: 6131,
4: 5842,
5: 5421,
6: 5000,
7: 6265,
8: 5000,
9: 5000}
训练模型。
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, [3, 3], activation='relu', input_shape=(28,28,1)))
model.add(tf.keras.layers.Conv2D(64, [3, 3], activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train_im,
epochs=EPOCHS,
validation_data=ds_test,
)
产出:
Epoch 55/60
loss: 0.0065 - sparse_categorical_accuracy: 0.9977 - val_loss: 0.8658 - val_sparse_categorical_accuracy: 0.8487
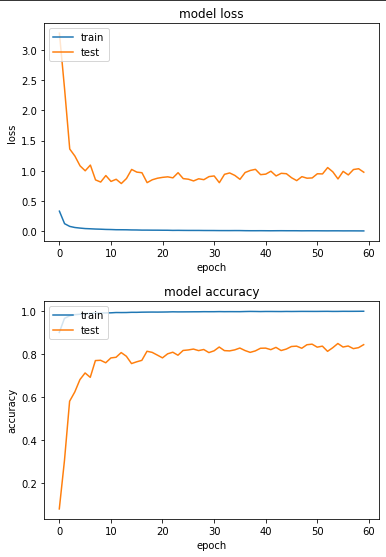
实验二:用 cGAN (Conditional GAN) 跑 Oversampling 後的不平衡资料
有鉴於实验一生成器效果不彰,所以这次实验我尝试将少量样本透过 Oversampling 的方式放大50倍,再拿去做 GAN 来生成样本。
idx_we_want = []
for idx in [0,1,2,3,4,5,7]:
idx_we_want += list(range(sum(counts[:idx]) ,sum(counts[:idx])+5000))
train_label_imbalanced = train_labels_sorted[idx_we_want]
train_images_imbalanced = train_images_sorted[idx_we_want]
idx_we_want = list(range(sum(counts[:6]),sum(counts[:6])+100)) + list(range(sum(counts[:8]),sum(counts[:8])+100)) + list(range(sum(counts[:9]),sum(counts[:9])+100))
train_label_689 = train_labels_sorted[idx_we_want]
train_images_689 = train_images_sorted[idx_we_want]
train_label_689 = train_label_689.repeat(50)
train_images_689 = train_images_689.repeat(50, axis=0)
train_label_imbalanced = np.concatenate((train_label_imbalanced, train_label_689))
train_images_imbalanced = np.concatenate((train_images_imbalanced, train_images_689), axis=0)
train_images_imbalanced, train_label_imbalanced = shuffle(train_images_imbalanced, train_label_imbalanced)
资料分布,[0,1,2,3,4,5,7]拿前面的5000张,而[6,8,9]则是用前100张 repeat 50次,来产生等量的5000张。
{0: 5000,
1: 5000,
2: 5000,
3: 5000,
4: 5000,
5: 5000,
6: 5000,
7: 5000,
8: 5000,
9: 5000}
GAN 训练结果:
Epoch 40/40
g_loss: 0.8425 - d_loss: 0.6364
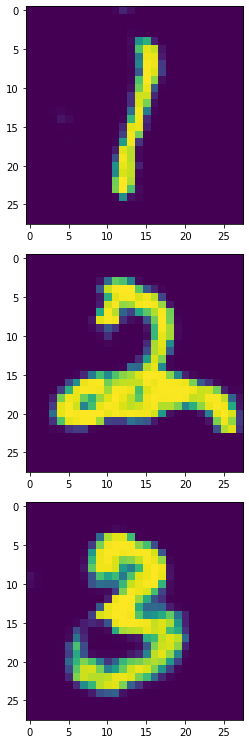
生成器产生的1,2,3:
生成器产生的6,8,9:
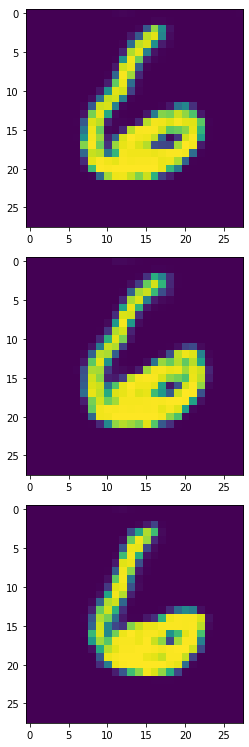
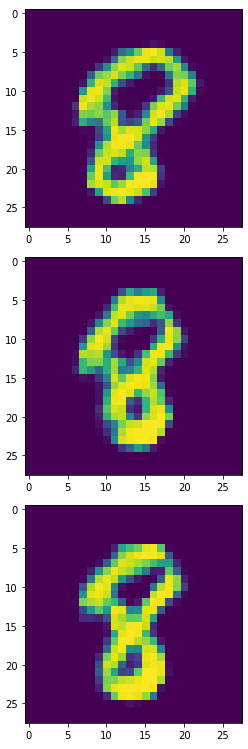
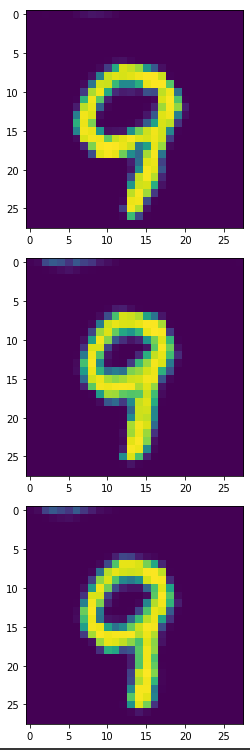
看起来6,8,9比实验一更完整,我们一样将此产出4900个合成样本来训练模型。
生成:
Epoch 57/60
loss: 0.0060 - sparse_categorical_accuracy: 0.9980 - val_loss: 0.8995 - val_sparse_categorical_accuracy: 0.8453
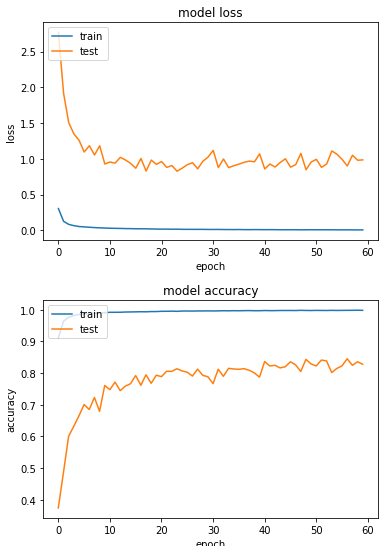
准确度84.5%,可惜并没有比实验一来的高。
以上就是这次使用 GAN 来产生合成样本的实验。
<<: Day29:今天来聊一下如何建立及管理 Azure Sentinel 威胁搜捕查询
>>: Day28 :【TypeScript 学起来】React + TypeScript 实作简单 Todo App Part1
Professional Writer
I am professional blogger and has keen interest in...
Day18-Webhook 实作(番外篇)LINEBot 之 LINEBotTiny
大家好~ 这几天应该对 line-bot-sdk-php 有了一些初浅的认识啦~ 不过在 line-...
@Day12 | C# WixToolset + WPF 帅到不行的安装包 [系统背景服务化]
鉴於 HelloWorld 专案是一般.net Core 的 MVC专案, 我们安装系统完成後,总不...
Day25:安全性和演算法-讯息监别码(Message Authentication Code)
讯息监别码(Message Authentication Code) 讯息监别码(Message A...
予焦啦!支援 RISC-V 权限指令与暂存器
本节是以 Golang 上游 1a708bcf1d17171056a42ec1597ca8848c...