Day 24 - 天眼CNN 的耳朵和嘴巴 - BERT
BERT 全名为 Bidirectional Encoder Representations from Transformers
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Transformer Encoder 的架构
- Google 以无监督的方式利用大量无标注文本「炼成」的语言代表模型,其架构为 Transformer 中的 Encoder。
- 使用google pre-trained models (2018)---很重要, 下面解释
- 多语言
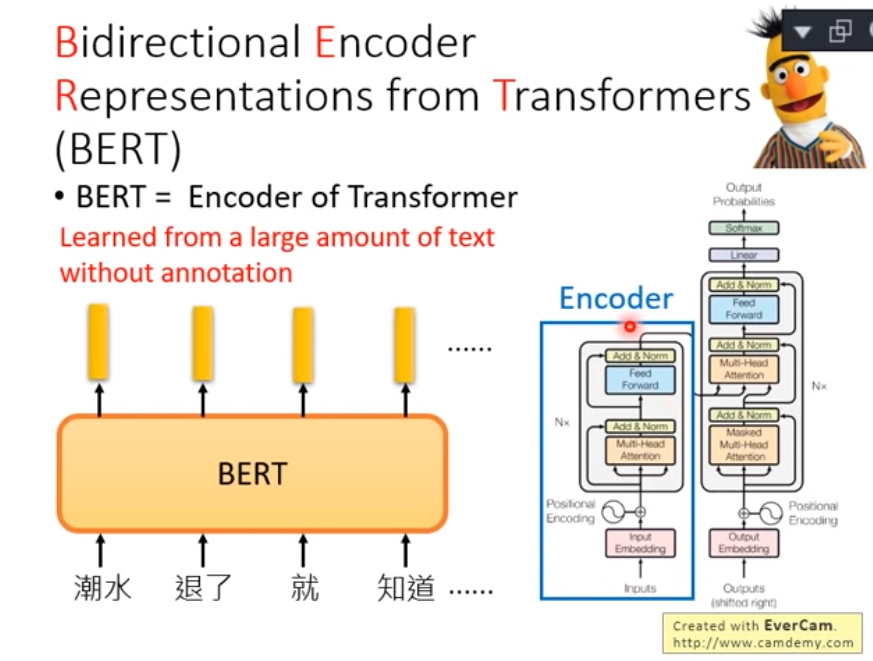
BERT 好处及影响
- 1:无监督数据无限大。不像 ImageNet 还要找人标注数据,要训练 LM 的话网路上所有文本都是你潜在的资料集(BERT 预训练使用的数据集共有 33 亿个字,其中包含维基百科及 BooksCorpus)
- 2:厉害的 语言模型(Language Model, LM) 能够学会语法结构、解读语义甚至指代消解。透过特徵撷取或是 fine-tuning 能更有效率地训练下游任务并提升其表现
- 3:减少处理不同 NLP 任务所需的 architecture engineering 成本(即迁移学习)
迁移学习-站在巨人肩膀
以往为了解决不同的 NLP 任务,我们会为该任务设计一个最适合的神经网路架构并做训练。设计这些模型并测试其 performance 是非常耗费成本的(人力、时间、计算资源)。
* 如果有一个能直接处理各式 NLP 任务的通用架构该有多好?
* BERT 论文的作者们使用 Transfomer Encoder、大量文本以及两个预训练目标,事先训练好一个可以套用到多个 NLP 任务的 BERT 模型,再以此为基础 fine tune 多个下游任务。
这就是近来 NLP 领域非常流行的两阶段迁移学习:
- 先以 LM Pretraining 的方式预先训练出一个对自然语言有一定「理解」的通用模型
- 再将该模型拿来做特徵撷取或是 fine tune 下游的(监督式)任务
Google 在预训练 BERT 时让它同时进行两个任务:
- 克漏字填空(1953 年被提出的 Cloze task,学术点的说法是 Masked Language Model, MLM)
- 判断第 2 个句子在原始文本中是否跟第 1 个句子相接(Next Sentence Prediction, NSP)
ELMo , GPT and BERT
ELMo link 利用独立训练的双向两层 LSTM 做语言模型并将中间得到的隐状态向量串接当作每个词汇的 contextual word repr.;
GPT 则是使用 Transformer 的 Decoder 来训练一个中规中矩、从左到右的单向语言模型。可以参考另一篇文章:直观理解 GPT-2 语言模型并生成金庸武侠小说来深入了解 GPT 与 GPT-2。
BERT 跟它们的差异在於利用 MLM(即克漏字)的概念及 Transformer Encoder 的架构,摆脱以往语言模型只能从单个方向(由左到右或由右到左)估计下个词汇出现机率的窘境,训练出一个双向的语言代表模型。这使得 BERT 输出的每个 token 的 repr. Tn 都同时蕴含了前後文资讯,真正的双向 representation。
跟以往模型相比,BERT 能更好地处理自然语言,在着名的问答任务 SQuAD2.0 也有卓越表现。
参考一: 进击的BERT:NLP 界的巨人之力与迁移学习
参考二: ELMO, BERT , GPT李宏毅教授讲解目前 NLP 领域的最新研究是如何让机器读懂文字的
注:本文是搜寻数个网站及各种不同来源之结果,着重在学习,有些内容已难办别出处,我会尽可能列入出处,若有疏忽或出处不可考,请联络我, 我会列入, 尚请见谅。
>>: [Cmoney 菁英软件工程师战斗营] IOS APP 菜鸟开发笔记(6)----关於标记丛集(Cluster Item)
[Day 09] 资料和资料之间的一对多关联
透过 DAO 方式存取资料,除了用传统的 join 方式处理资料表之间的关联外,也可以直接从物件之间...
我们的基因体时代-AI, Data和生物资讯 Day23- 基因注释资料在Bioconductor中视觉化之呈现:Gviz
上一篇我们的基因体时代-AI, Data和生物资讯 Day22- 基因注释资料在Bioconduct...
Dungeon Mizarka 007
利用Zenject进行架构端的调整是持续性的,有些功能也会因为之前是以Hard Code的方式完成而...
radio vs checkbox
延续昨天的v-model绑定,昨天我们知道他可以绑定input, textarea和select e...
D32 - 完赛心得
30 天的填坑之旅终於结束了 ...(›´ω`‹ ) 不知道大家觉得如何呢? 第一次挑战将主题分成 ...