Azure MLS-Notebooks中开发
<<致歉>>
开了两个免费的Azure帐号,由於没有紧盯着预算,不小心玩性大发,把两个帐号的额度全部耗尽,所以想说明的资料都被锁住了。但我会尽量依记忆,来说明重点部分。截图就抱歉了!!
所以,开了compute後,请小心额度,不然一天耗费NTD400-500,很快就见底了!
<<致歉---END>>
我们若想自己开发模型,通常可从两个地方进入IDE进行开发工作。
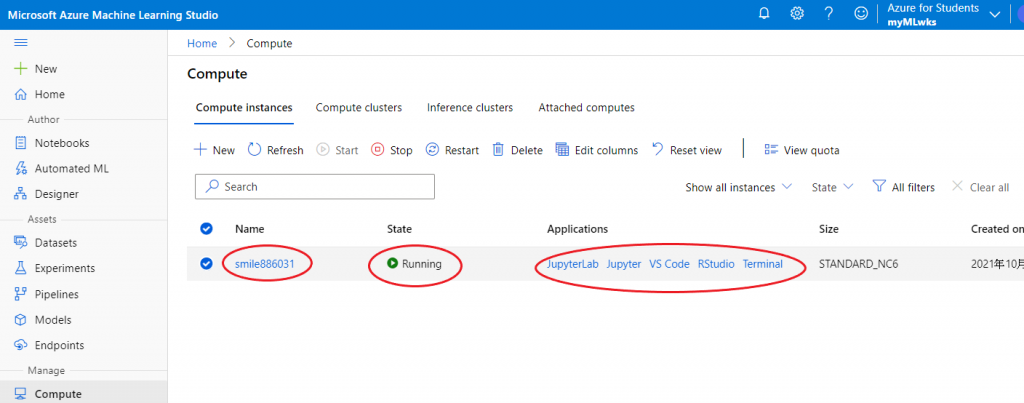
- Compute:见图<AZ-ComIns02.png>。可从此处进入Jupyter and JupyterLab,缺点是没有IntelliCode的功能,写起程序会很累。
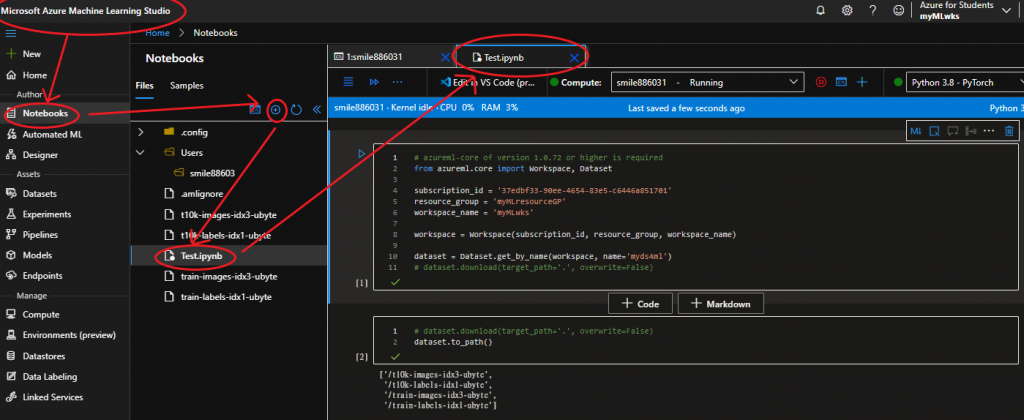
- Notebook:见图<AZ-TermNB.png>。从此处开发程序,具有IntelliCode的功能,效率提升多了。
图<AZ-ComIns02.png>
图<AZ-TermNB.png>
我们建立好自己的MNIST [Azure dataset],如何喂给dataloader呢?
首先,我们得分辨出 [Azure dataset]和[torchvision.datasets.MNIST]是不同的。当然,您可以使用mlxtend直接读local file。但是,我们此处不使用该package。
在下列程序码中,若我们的 [Azure dataset]中 (root=data_dir),存在所需的档案,那麽 download=True 便会取用 local file。有了dataset,自然即可喂给dataloader了。
xy_train = torchvision.datasets.MNIST(
root=data_dir,
train=True,
download=True, # if exists, loads the local files
transform=my_transform_train
)
这个部分,我们主要谈自己开发模型时的环境,及dataset的连结。接下来,我们开始谈Azure AutoML。
<<: Vue.js 从零开始:Vue CLI / Gihub Pages
>>: Day 28 维护 PostgreSQL 资料库的参数?
Day 12 (Ai)
2021版本才能存云端文件 => 可以版本控制 =>视窗 =>版本纪录 1.基础...
Day 9:使用 Typora 发表你的第一篇 Hexo 文章
今天我们正式要使用 Markdown 撰写你的第一篇部落格文章啦! 用指令建立文章或草稿 .md 档...
Day 01 | 前言、规划及为什麽需要 Test Case Management?
目录 前言 文章规划 为什麽需要 Test Case Management? 需求与选择 需求是什麽...
卡夫卡的藏书阁【Book7】- Kafka 实作新增 Topic
「不要屈服,不要淡化,不要使它看来合逻辑,不要依据潮流而修改你的灵魂。相反的,狠狠的追随你最强烈的...
Angular 深入浅出三十天:表单与测试 Day15 - 整合测试实作 - 被保人 by Reactive Forms
昨天帮我们用 Reactive Forms 所撰写的被保人表单写完单元测试之後,今天则是要来为它写...