Day 29:K-近邻演算法(k-nearest neighbors)
K-近邻演算法是一个以已知的资料作为输入,为资料进行分类的演算法,在日常生活中有非常多应用。
举例来说,假设我们想要帮一些不知道是章鱼还是乌贼的动物分类,我们依照这些动物的特徵,把过往的资料用像下方的图表表示,例如x轴代表身体长度,y轴代表颜色深浅,图中红色的点都是乌贼(体型细长、颜色较浅),绿色的点都是章鱼(体型较短、颜色较深)。
图片来源:Geeksforgeeks

那麽当今天碰了两只未知的新动物,将牠们的资料也加进图表中(如下图白色三角型)。
我们可能会将左边的点(2.5, 7)归类为章鱼,而右边的(5.5, 4.5)归类为乌贼,因为它们分别靠近绿色和红色两堆资料。
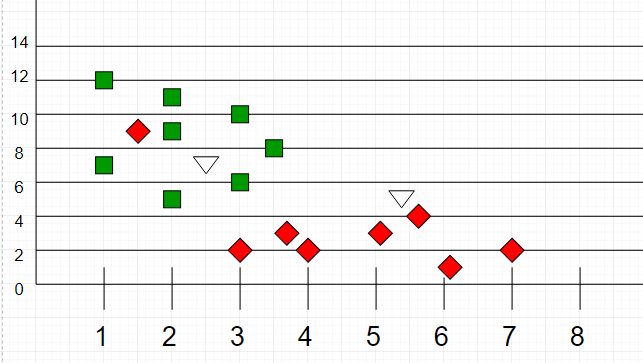
这就是k-近邻演算法的想法,以距离最近(也就是相似度高)的已分类资料来为新的资料分类。
具体来说,k-近邻指的是「最近的K个邻居」,代表以K个邻居中占多数的分类,作为新资料的分类。k的大小会因资料而异,基本上是不会太大的正整数。而距离远近则可以以几种方式计算,常见的方法如计算平面座标两点距离。以上图为例,如果k=5,这时有一个新的点要进行分类,就计算出距离最近的五个点,如果其中有三个红色,两个绿色,则新的资料被归类为红色。
k-近邻演算法是机器学习(machine learning)中很重要的演算法。例如运用在脸部、笔迹、语音等图形识别(pattern recognition)的工作中,就是给电脑有明确分类以及特徵的样本,训练电脑作出一定准确度的判断和辨别。
另外一个应用的地方,就是随处可见的各种影片、音乐、商品推荐系统。例如一个影片播放平台可能会请用户为电影作出评分,分数相仿的用户便是特徵相似的近邻,以此就可以把电影推荐给有相似喜好的人。而当评分的影片越多、种类越广,就越能知道哪些用户相似度高,并更精准地作出推荐。
以上提到的输出大多是资料的分类。除此之外,输出也可以以k个近邻的值来计算的平均值。
假设一个农夫想要知道今年要买多少种子,或者经营烧烤店的老板想知道要进货多少肉,他们就可以参考k-近邻演算法得出的平均值。只要找出跟答案相关性高的特徵(例如是否下雨、有无节/假日、疫情状况如何),接着以这些特徵找出相似度高的过往资料(例如过去k个都是下雨天、连假的日子),计算这些过往日期订货量的平均值,就可以预估当前的进货量。
<<: 【28】遇到不平衡资料(Imbalanced Data) 时 使用 Oversampling 解决实验
>>: Day-27 手把手的手写面是模型 0x2:资料训练和结果输出
住建部谈青年买不起租不好房,你在租房还是已购房?
租房难、买房难,相信是当下社会上大部分年轻工作者的生活痛点,特别是在大城市工作的打工人,光是租房就已...
D5: [漫画]工程师太师了-第3话
工程师太师了: 第3话 杂记: 继续聊天聊满30天~ 之前说过在编剧时发现, 工程师的生活也就只有上...
第六天:在 Windows 上安装 Gradle
在 Windows(在这系列里指的是 Windows 10 以上的版本)上除非您使用 WSL 环境,...
调用 Properties.Resources 全域资源档
有时候难免要使用一些资源档 步骤分为 新增 & 使用 新增 在方案总管的专案上右键 选属性 ...
Ruby幼幼班--Two Sum II
快忘记自己传教过哪些K-pop了.... Two Sum II 题目连结:https://leet...