【28】遇到不平衡资料(Imbalanced Data) 时 使用 Oversampling 解决实验
昨天我们使用了降低多数样本 Undersampling 的方式来解决少数样本的问题,今天我们要用复制少数样本 Oversampling 方式来实验看看,当然,这种方式的缺点就是因为复制了少数样本,等於是每次 epoch 都会重复看到这些复制的资料,对於泛化来说,最终的模型在遇到这些少量样本的变形时,仍然缺乏良好的预测性。
首先,我们一样要先准备好训练资料,原本的训练样本分布如下
{0: 5923,
1: 6742,
2: 5958,
3: 6131,
4: 5842,
5: 5421,
6: 5918,
7: 6265,
8: 5851,
9: 5949}
实验一:复制60倍
我们针对 6,8,9 这三种标签复制60倍(其他样本数在5400~6800都有,这边复制60倍让他接近6000)
idx_we_want = list(range(sum(counts[:6]))) + list(range(sum(counts[:7]) ,sum(counts[:7])+counts[7])) # [0,5] + [7,7]
train_label_imbalanced = train_labels_sorted[idx_we_want]
train_images_imbalanced = train_images_sorted[idx_we_want]
idx_we_want = list(range(sum(counts[:6]),sum(counts[:6])+100)) + list(range(sum(counts[:8]),sum(counts[:8])+100)) + list(range(sum(counts[:9]),sum(counts[:9])+100))
train_label_689 = train_labels_sorted[idx_we_want]
train_images_689 = train_images_sorted[idx_we_want]
train_label_689 = train_label_689.repeat(60)
train_images_689 = train_images_689.repeat(60, axis=0)
train_label_imbalanced = np.concatenate((train_label_imbalanced, train_label_689))
train_images_imbalanced = np.concatenate((train_images_imbalanced, train_images_689), axis=0)
train_images_imbalanced, train_label_imbalanced = shuffle(train_images_imbalanced, train_label_imbalanced)
复制完成後,我们将分布再次印出,确认数量无误。
unique, counts = np.unique(train_label_imbalanced, return_counts=True)
dict(zip(unique, counts))
再来就可以训练了
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, [3, 3], activation='relu', input_shape=(28,28,1)))
model.add(tf.keras.layers.Conv2D(64, [3, 3], activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train_im,
epochs=EPOCHS,
validation_data=ds_test,
)
产出:
Epoch 28/30
loss: 0.0108 - sparse_categorical_accuracy: 0.9963 - val_loss: 0.5889 - val_sparse_categorical_accuracy: 0.9024
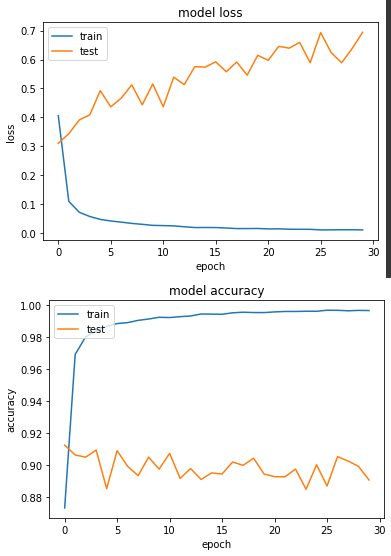
其准确度和昨天的 Undersampling 差不多。
实验二:复制 30 倍
基於好奇,我想知道 Oversampling 方式如果复制的数量减半,那对模型会有什麽样的影响?因此和实验一相比,我将复制的数量缩减到30倍。
idx_we_want = list(range(sum(counts[:6]))) + list(range(sum(counts[:7]) ,sum(counts[:7])+counts[7])) # [0,5] + [7,7]
train_label_imbalanced = train_labels_sorted[idx_we_want]
train_images_imbalanced = train_images_sorted[idx_we_want]
idx_we_want = list(range(sum(counts[:6]),sum(counts[:6])+100)) + list(range(sum(counts[:8]),sum(counts[:8])+100)) + list(range(sum(counts[:9]),sum(counts[:9])+100))
train_label_689 = train_labels_sorted[idx_we_want]
train_images_689 = train_images_sorted[idx_we_want]
train_label_689 = train_label_689.repeat(30)
train_images_689 = train_images_689.repeat(30, axis=0)
train_label_imbalanced = np.concatenate((train_label_imbalanced, train_label_689))
train_images_imbalanced = np.concatenate((train_images_imbalanced, train_images_689), axis=0)
train_images_imbalanced, train_label_imbalanced = shuffle(train_images_imbalanced, train_label_imbalanced)
资料分布:
{0: 5923,
1: 6742,
2: 5958,
3: 6131,
4: 5842,
5: 5421,
6: 3000,
7: 6265,
8: 3000,
9: 3000}
训练产出:
Epoch 12/30
loss: 0.0292 - sparse_categorical_accuracy: 0.9910 - val_loss: 0.4467 - val_sparse_categorical_accuracy: 0.9079
准确度一样有达90%。
以上两个实验都表示使用 Oversampling 来训练对少数样本的准确度都能有所提升,不过从实验一和实验二的 loss 来看,会发现训练越久,loss 值是越来越大的,这代表发生了过拟合,下一篇会再介绍另一个方法。
<<: Day-27 请问 git rebase 和 git merge 是什麽?差别又在哪里?
>>: Day 29:K-近邻演算法(k-nearest neighbors)
Day 5 双向绑定及回圈
今天来介绍v-model&data跟v-for的用法 data→用来储存里面的资料,当dat...
Day 11 Odoo Actions (ir.actions.act_url)
Odoo模组开发实战 目录 Action 1.1 URL Actions (ir.actions.a...
Day7 - TextView(一)
TextView喜虾密东西勒?? 其实就是程序一开始"Hello World!"...
Day 28: Incident Response on AWS
天有不测风云,任何单位就算已经完全做到了前面四大面向,你应该还是要在内部建立一套事件回应的机制,透过...
DAY 10-《区块密码2》AES(2)-密钥排程及安全性
"AE、AES、AED、AEIOU。" --- 密钥排程 key schedul...