Day 25. slate × Normalizing × Dirty-Path
我们在 上上一篇 也有提到过 slate 将 Normalizing 这项功能的实现拆成了第一步骤的『肮脏标记( Dirty-Path ) 』以及透过肮脏标记实际实行『正规化( Normalize )』的第二步骤。
顺序都分出来了我们当然先来看一下肮脏标记到底是哪里被弄脏了。
Dirty-Path :你才脏,你全家都ㄗ...
首先我们在 weak-map.ts 里可以看到一组名叫 DIRTY_PATHS 的 WeakMap
// weak-map.ts
export const DIRTY_PATHS: WeakMap<Editor, Path[]> = new WeakMap()
它负责纪录编辑器当前的肮脏路径内容,供後续的 methods 使用。
如果读者还记得我们在 Day21 贴的 apply method 的 code 的内容的话就会发现其中设定 Dirty-Paths 的 section 里又拆成了 oldDirtyPaths 与 newDirtyPaths 两个变数,并针对这两组变数额外进行一些处理後才整合进 DIRTY_PATHS 里。
这麽做是因为 Normalize 的执行方式并不是『一个 Operation 搭配一次 Normalize 』,而是『一组完整的 FLUSHING 搭配一次 Normalize 』,想想看一次 Transform 里有好多次的 Operations ,真要是这样实作的话该有多耗效能啊!才刚弄乾净马上就又被弄脏了
而不同的 Operation 有机会生成不同的肮脏路径,也因此 slate 需要这项机制为它整理出一组 FLUSHING 里最後确定需要 Normalize 的 Dirty Paths ,一样来看看它是怎麽运作的:
const set = new Set()
const dirtyPaths: Path[] = []
const add = (path: Path | null) => {
if (path) {
const key = path.join(',')
if (!set.has(key)) {
set.add(key)
dirtyPaths.push(path)
}
}
}
const oldDirtyPaths = DIRTY_PATHS.get(editor) || []
const newDirtyPaths = getDirtyPaths(op)
for (const path of oldDirtyPaths) {
const newPath = Path.transform(path, op)
add(newPath)
}
for (const path of newDirtyPaths) {
add(path)
}
DIRTY_PATHS.set(editor, dirtyPaths)
在每一次的 Operation 中:
-
oldDirtyPaths会去取得储存在DIRTY_PATHS里头前一次的结果,经过这次的 operation transform 为正确的 path 以後经由addmethod 推入dirtyPaths变数里。 -
newDirtyPaths会透过getDirtyPaths取得这次 operation 会制造出的 Dirty-Path 并经由addmethod 推入dirtyPaths变数里。 -
addmethod 会将丢入的 path 与第一行的set比对,只推入还不存在於dirtyPaths变数里的 path 以避免重复推入。 - 最後将
dirtyPaths存为DIRTY_PATHS里editor的 value 。
Dirty-Path Generation
与 Dirty-Path 生成相关的一切逻辑都被封装在 getDirtyPaths 这个 helper function 里。
除了 SetSelectionOperation 与 SetNodeOperation 之外,其他 Operations 都会生成 Dirty-Path 。
const getDirtyPaths = (op: Operation): Path[] => {
switch (op.type) {
case 'insert_text': ... // Implementation
case 'remove_text': ... // Implementation
case 'set_node': ... // Implementation
case 'insert_node': ... // Implementation
case 'merge_node': ... // Implementation
case 'move_node': ... // Implementation
case 'remove_node': ... // Implementation
case 'split_node': ... // Implementation
default: {
return []
}
}
}
一个一个来看他们的判断标记的概念吧:
-
insert_text、remove_text、set_node这三组 Operations 会标记的肮脏路径一样都是『一路从根节点串连下来的祖先路径与
op.path本身的路径』:case 'insert_text': case 'remove_text': case 'set_node': { const { path } = op /** Path.levels: Get a list of paths at every level down to a path. Note: this is the same as `Path.ancestors`, but including the path itself. */ return Path.levels(path) }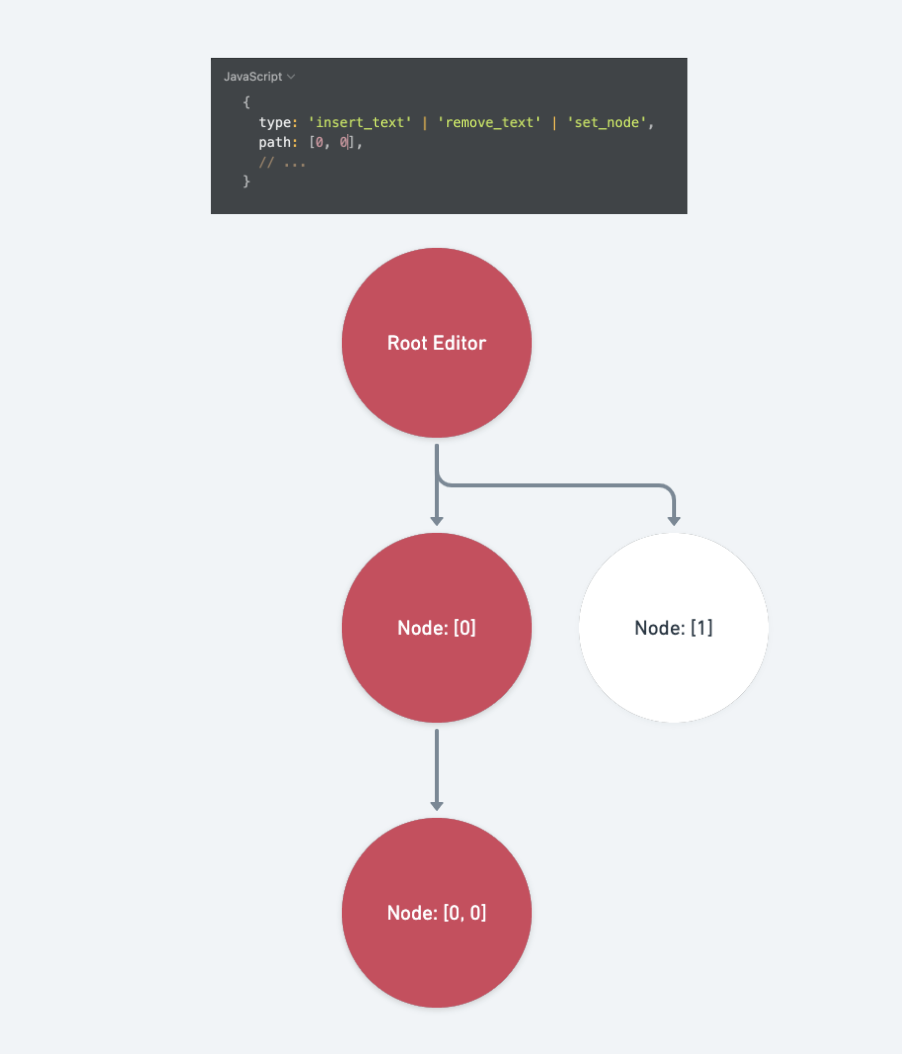
-
insert_node受到肮脏标记的路径包含:
op.path的祖先路径、path本身、path的子层路径:case 'insert_node': { const { node, path } = op const levels = Path.levels(path) const descendants = Text.isText(node) ? [] : Array.from(Node.nodes(node), ([, p]) => path.concat(p)) return [...levels, ...descendants] }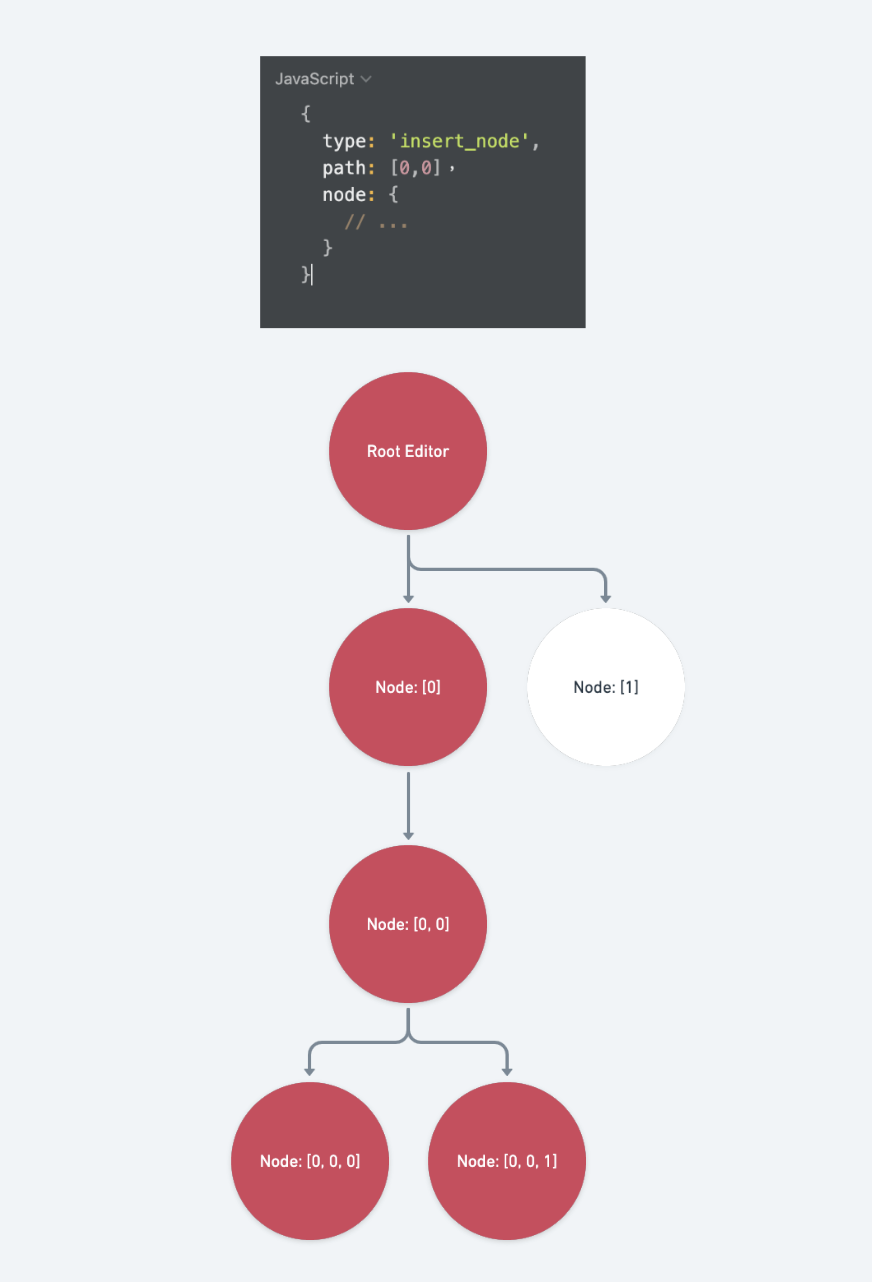
-
merge_node受到肮脏标记的路径包含:
op.path的祖先路径、path同层的前一个 sibling (因为是向前合并,所以只需要标记前一个 sibling 而不需要标记path本身)case 'merge_node': { const { path } = op const ancestors = Path.ancestors(path) const previousPath = Path.previous(path) return [...ancestors, previousPath] }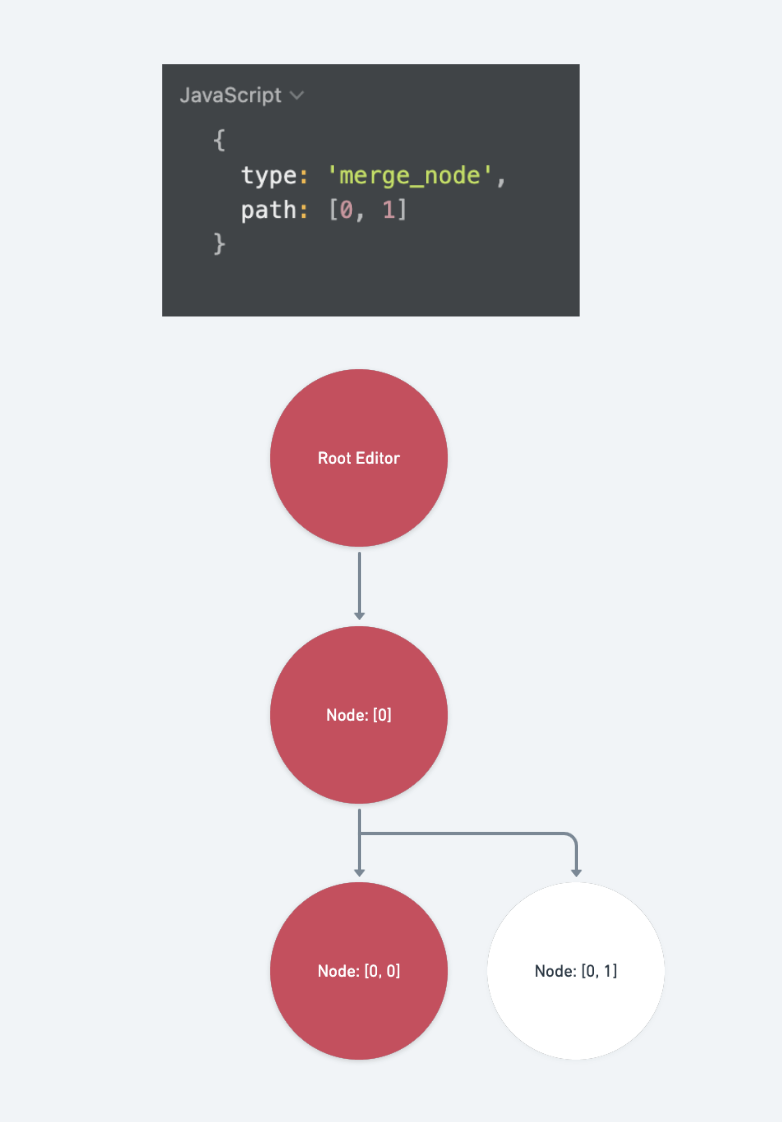
-
move_node受到肮脏标记的路径包含:
-
欲移动路径经由
Path.transform更新过後的所有祖先路径const oldAncestors: Path[] = [] for (const ancestor of Path.ancestors(path)) { const p = Path.transform(ancestor, op) oldAncestors.push(p!) } -
移动到的目标路径经由
Path.transform更新过後的所有祖先路径const newAncestors: Path[] = [] for (const ancestor of Path.ancestors(newPath)) { const p = Path.transform(ancestor, op) newAncestors.push(p!) } -
最後是移动结果的路径
const newParent = newAncestors[newAncestors.length - 1] const newIndex = newPath[newPath.length - 1] const resultPath = newParent.concat(newIndex)
将上述三组路径们包成一组阵列回传回去
return [...oldAncestors, ...newAncestors, resultPath]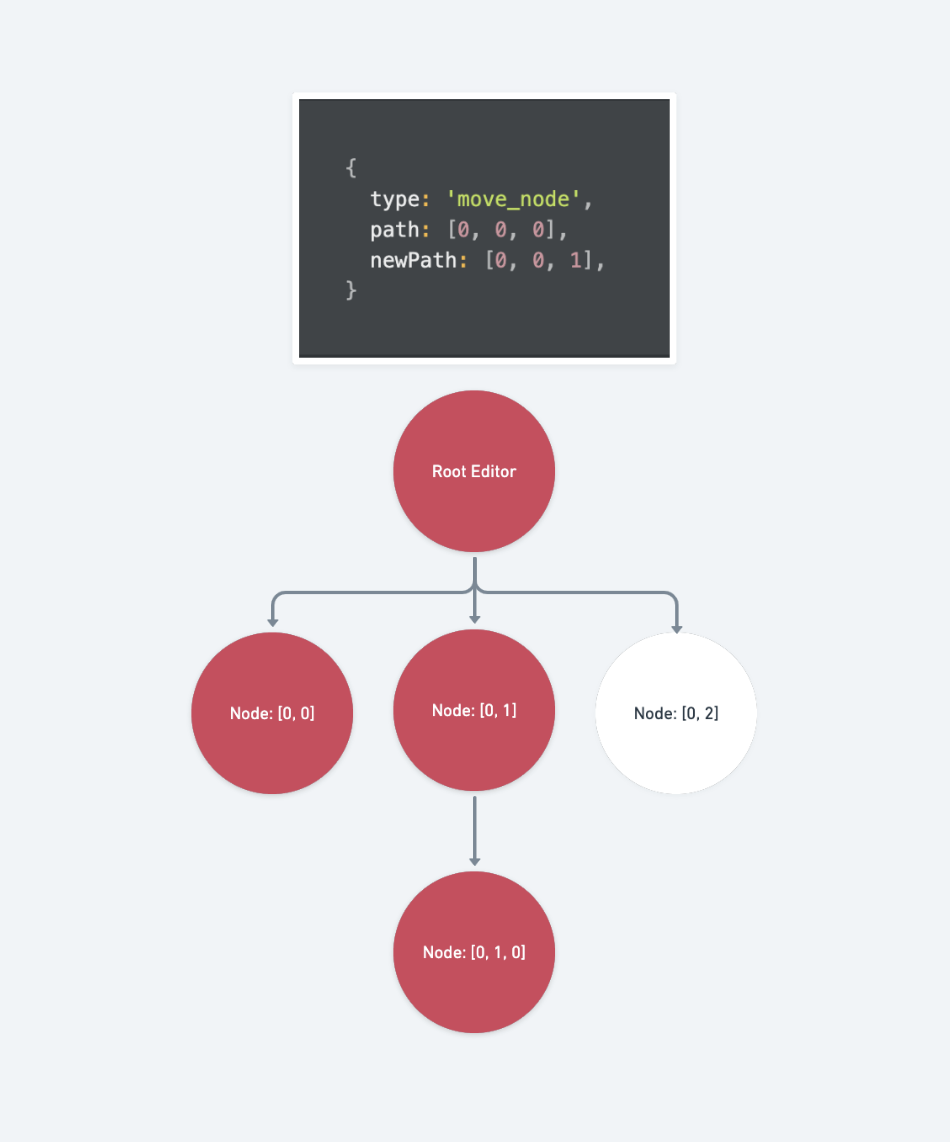
-
-
remove_node受到肮脏标记的路径为被移除之路径的祖先路径
case 'remove_node': { const { path } = op const ancestors = Path.ancestors(path) return [...ancestors] } -
split_node受到肮脏标记的路径包含:
op.path的祖先路径、path本身、与path同层的後一个 siblingcase 'split_node': { const { path } = op const levels = Path.levels(path) const nextPath = Path.next(path) return [...levels, nextPath] }
明天就到了本章节的最後一篇了,介绍完第一步骤的肮脏标记以後当然就轮到了实际执行正规化的第二步骤了。
要介绍的内容其实也算是整个 slate 里数一数二复杂的,为了因应正规化所会遭遇到的问题以及整体的设计与效能上的考量,作者将第二步骤拆成了好几层 function 彼此各司其职,当初笔者在研究时也是在各个函式之间穿梭,上滑下滑滑到怀疑人生 ...
那麽今天的文章就到这边为止,咱们明天再见罗~
铁人赛倒数 5 天
<<: #24-这个播放器也太潮!用Canvas放音乐!w/JS web audio API
Day 19动画的封装与简化
AnimatedWidget AnimatedWidget是一个有状态的StatefulWidget...
30天程序语言研究
今天是30天程序语言研究的第十二天,研究的语言一样是python,今天主要学习的是物件函式和继承 网...
【Day 24】Google Apps Script - API Blueprint 篇 - Google Docs 转换 API Blueprint 格式(2)
继续介绍昨天主流程里的副程序吧。 今日要点: 》Google Docs 转换 API Bluepr...
Day 27 : 案例分享(8.1) 讯息、邮件与线上会议 - 单据通知及公司内部讨论
功能说明 本来没有预期说明这段,但odoo15的线上会议太香了,让整体实用性大增 属於odoo的底层...
Day 07: 类别、系统、羽化
「在函式里,我们计算程序行数,来衡量函式的大小;在类别里,我们使用不同的量测方式,我们计算职责的数...