[Day 27] 应用二:口罩下的人脸
前几天在谈到人脸识别有提到:大部分使用神经网路的模型都可以侦测与识别口罩下的人脸。
纳今天如果我们只是想要知道有没有戴口罩呢?
其实,我们只需要有一些训练资料,
跟简单的几个步骤,
就可以完成这个需求。
就让我们来实际训练一个简单的口罩辨识模型吧!
本文开始
这里我们切成几个部分来看:
准备训练资料
- 从这里下载repo,解压缩
- 将
observations/experiements/data整个目录复制到你的电脑上,里面应该包含- with_mask目录:690张图片
- without_mask目录:686张图片
随意浏览with_mask图片你可以发现,实际上这些戴口罩的照片是"人工"合成的,但并不影响我们训练模型 (实际辨识效果也不差)
但要特别注意的是,with_mask与without_mask里面的照片不可以用同一个人,不然你的模型很难用在其他不在训练资料集的图片上,辨识的效果会很差。
建立专案
- 你可以开启之前的专案,或是自行新建一个,然後将你的目录结构与下面相同:
- application - mask_detector - train.py - detect_webcam.py - dataset - mask_person - with_mask - without_mask - 在你的Python环境中确认已安装
- tensorflow == 2.0.4
- imutils
- matplotlib
目录结构与档案应该很好懂,我们继续下一部份
训练模型
- 开启
train.py档案,撰写以下程序码 (说明在程序码内注解):import argparse import ntpath import os import matplotlib.pyplot as plt import numpy as np from imutils import paths from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelBinarizer from tensorflow.keras.applications import MobileNetV2 from tensorflow.keras.applications.mobilenet_v2 import preprocess_input from tensorflow.keras.layers import AveragePooling2D from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Dropout from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Input from tensorflow.keras.models import Model from tensorflow.keras.optimizers import Adam from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.preprocessing.image import img_to_array from tensorflow.keras.preprocessing.image import load_img from tensorflow.keras.utils import to_categorical def main(): # 初始化Arguments ap = argparse.ArgumentParser() ap.add_argument("-d", "--dataset", required=True, help="path to input dataset") ap.add_argument("-p", "--plot", type=str, default="plot.png", help="path to output loss/accuracy plot") ap.add_argument("-m", "--model", type=str, default="mask_detector.model", help="path to output face mask detector model") args = vars(ap.parse_args()) # 初始化训练用参数与Batch Size INIT_LR = 1e-4 EPOCHS = 20 BS = 32 # 载入图片 print("[INFO] loading images...") imagePaths = list(paths.list_images(args["dataset"])) data = [] labels = [] # 将训练图片进行前处理与建立训练data for imagePath in imagePaths: label = ntpath.normpath(imagePath).split(os.path.sep)[-2] # 注意这里将图片转成224 x 224,与MobileNetV2模型需要的Input一样大小 image = load_img(imagePath, target_size=(224, 224)) image = img_to_array(image) image = preprocess_input(image) data.append(image) labels.append(label) data = np.array(data, dtype="float32") labels = np.array(labels) # 将类别encoding成数值方便训练 lb = LabelBinarizer() labels = lb.fit_transform(labels) labels = to_categorical(labels) # 切分训练资料与测试资料 (trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.20, stratify=labels, random_state=9527) # 做Data Argumentation,强化模型的辨识能力 aug = ImageDataGenerator( rotation_range=20, zoom_range=0.15, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15, horizontal_flip=True, fill_mode="nearest") # 载入模型,去除模型最後一层 (等等要改为我们要辨识的"两种类别") baseModel = MobileNetV2(weights="imagenet", include_top=False, input_tensor=Input(shape=(224, 224, 3))) # 组合自定义的最後层 headModel = baseModel.output headModel = AveragePooling2D(pool_size=(7, 7))(headModel) headModel = Flatten(name="flatten")(headModel) headModel = Dense(128, activation="relu")(headModel) headModel = Dropout(0.5)(headModel) headModel = Dense(2, activation="softmax")(headModel) # 建立模型 model = Model(inputs=baseModel.input, outputs=headModel) # 确认模型只有我们新增的最後层可以训练 (transfer learning) for layer in baseModel.layers: layer.trainable = False # 编译模型 print("[INFO] compiling model...") opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS) model.compile(loss="binary_crossentropy", optimizer=opt, metrics=["accuracy"]) # 开始训练 print("[INFO] training head...") H = model.fit( aug.flow(trainX, trainY, batch_size=BS), steps_per_epoch=len(trainX) // BS, validation_data=(testX, testY), validation_steps=len(testX) // BS, epochs=EPOCHS) # 使用测试资料验证模型准确率 print("[INFO] evaluating network...") predIdxs = model.predict(testX, batch_size=BS) predIdxs = np.argmax(predIdxs, axis=1) # 印出测试结果 print(classification_report(testY.argmax(axis=1), predIdxs, target_names=lb.classes_)) # 储存模型 print("[INFO] saving mask detector model...") model.save(args["model"], save_format="h5") # 划出训练结果 N = EPOCHS plt.style.use("ggplot") plt.figure() plt.plot(np.arange(0, N), H.history["loss"], label="train_loss") plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss") plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc") plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc") plt.title("Training Loss and Accuracy") plt.xlabel("Epoch #") plt.ylabel("Loss/Accuracy") plt.legend(loc="lower left") plt.savefig(args["plot"]) if __name__ == '__main__': main() - 开启terminal,切换到
train.py档案的目录下,执行python train.py -d {你的mask_person资料集目录} - 等待训练 (tensorflow在CPU上跑可能会需要一点时间;我在GPU上执行大约10分钟左右就完成),最後会产出下面的结果:
模型的准确率,有99%
[INFO] evaluating network...
precision recall f1-score support
with_mask 0.99 0.99 0.99 138
without_mask 0.99 0.99 0.99 138
accuracy 0.99 276
macro avg 0.99 0.99 0.99 276
weighted avg 0.99 0.99 0.99 276
训练模型的accuracy与loss的趋势,可以看出模型真的有学习到东西,并且没有过度训练
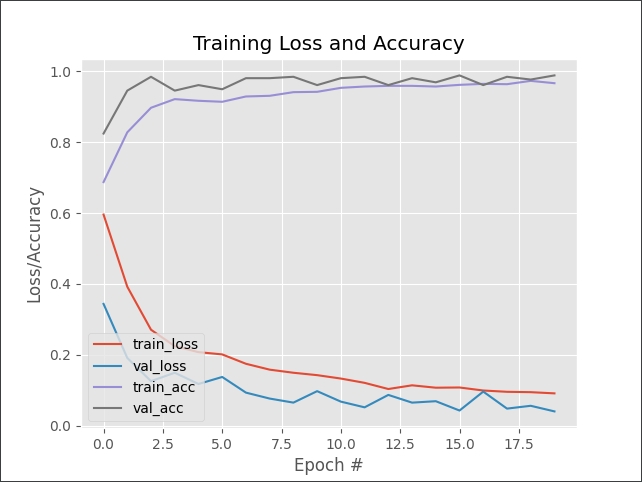
最後在你当前的目录下会产生一个mask_detector.model的档案,训练完成!
实时辨识
- 开启
detect_webcam.py,撰写以下程序码 (说明在程序码内注解):import argparse import time import cv2 import imutils import mtcnn import numpy as np from imutils.video import WebcamVideoStream from tensorflow.keras.applications.mobilenet_v2 import preprocess_input from tensorflow.keras.models import load_model from tensorflow.keras.preprocessing.image import img_to_array # 初始化脸部侦测模型 detector = mtcnn.MTCNN() # 辨识人脸与侦测是否有戴口罩 def detect_and_predict_mask(frame, mask_net): faces = [] locs = [] preds = [] rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) img_h, img_w = rgb.shape[:2] bboxes = detector.detect_faces(rgb) for bbox in bboxes: (x, y, w, h) = bbox['box'] padding = 35 (crop_x0, crop_x1) = (x - padding if x > padding else 0, x + w + padding if x + w + padding < img_w else img_w) (crop_y0, crop_y1) = (y - padding if y > padding else 0, y + h + padding if y + h + padding < img_h else img_h) face = rgb[crop_y0:crop_y1, crop_x0:crop_x1] face = cv2.resize(face, (224, 224)) face = img_to_array(face) face = preprocess_input(face) faces.append(face) locs.append((x, y, x + w, y + h)) if len(faces) > 0: faces = np.array(faces, dtype="float32") preds = mask_net.predict(faces, batch_size=32) return (locs, preds) def main(): # 初始化Arguments ap = argparse.ArgumentParser() ap.add_argument("-m", "--model", default="mask_detector.model", help="path to the trained mask model") args = vars(ap.parse_args()) maskNet = load_model(args["model"]) # 启动WebCam vs = WebcamVideoStream().start() time.sleep(2.0) while True: frame = vs.read() frame = imutils.resize(frame, width=400) (locs, preds) = detect_and_predict_mask(frame, maskNet) for (box, pred) in zip(locs, preds): (startX, startY, endX, endY) = box (mask, withoutMask) = pred (label, color) = ("Mask", (0, 255, 0)) if mask > withoutMask else ("No Mask", (0, 0, 255)) label = "{}: {:.2f}%".format(label, max(mask, withoutMask) * 100) cv2.putText(frame, label, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2) cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2) cv2.imshow("Frame", frame) key = cv2.waitKey(1) & 0xFF if key == ord("q"): break cv2.destroyAllWindows() vs.stop() if __name__ == '__main__': main()
这个程序码如果理解前面系列文章,大部分的内容大同小异,几个重点说明一下:
- 第25行,这里我们使用前面文章用来侦测人脸关键点的MTCNN,主要原因是因为
- 我们模型没办法在"侦测不到人脸"的情况下判断是否有戴口罩
- MTCNN在有脸部遮蔽物的情况下依然能够很好的侦测人脸
- MTCNN有提供侦测人脸的bounding box位置
- 第28 ~ 30行,MTCNN侦测人脸的区域比较"贴近"脸部轮廓,我们需要将口罩在人脸外的区域也包括进来
- 第32 ~ 35行,模型训练经过什麽样的前处理 (preprocess_input, img_to_array),模型预测就要使用一样的前处理
最後执行的结果如下
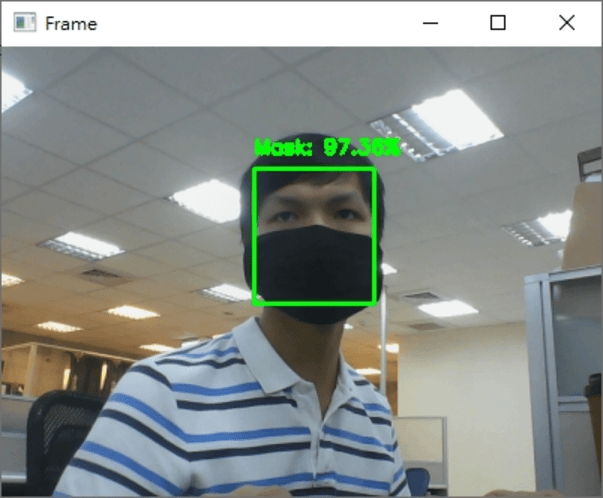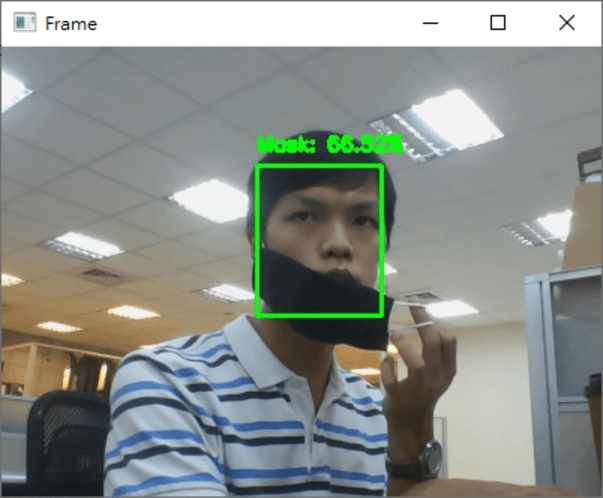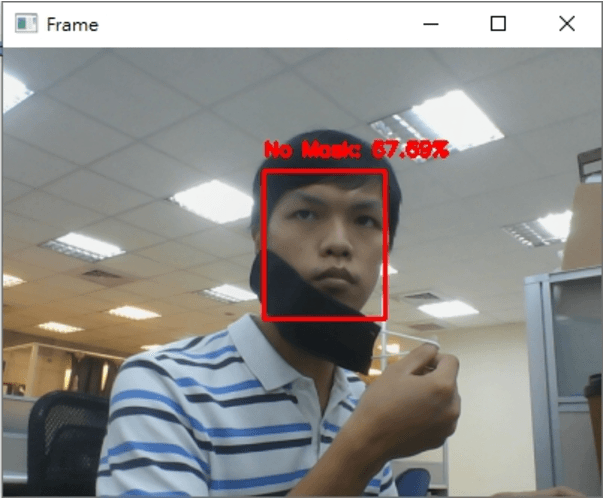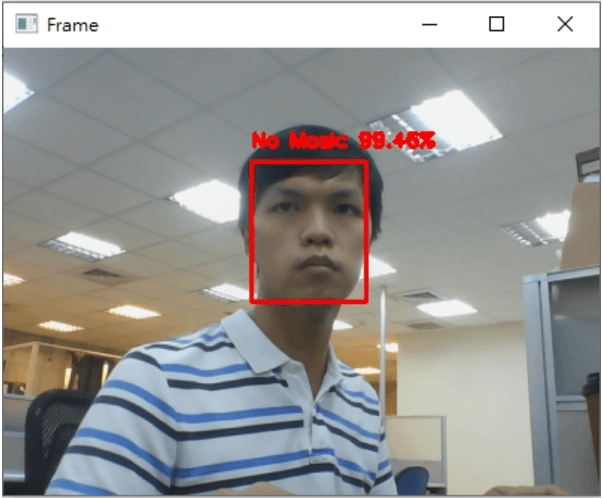
希望你还喜欢今天的应用,明天见!
今日传送门
>>: [NestJS 带你飞!] DAY25 - Authorization & RBAC
Day 14: Structural patterns - Decorator
目的 使用包覆(Wrapper)的方式,可以动态地给物件增添新的功能,或是重新定义既有的功能,达到扩...
[Golang]效能测试(Benchmark)简介-心智图总结
1. Benchmark,是GO语言用来做函数的效能测试。 2. Go语言对效能测试函数的名称与函数...
Day 13:Python基本介绍06 | 函数、读写档案、引用
早安安! 今天是Python基本介绍的最後一天了~ 6天真的太短了,有好多东西想讲但都讲不完 ಥ⌣ಥ...
[Day11] 团队管理:团队共识与团队思考
团队目标的建立 提供对应的元素,催化IT团队与事业体相呼应的目标 身为产品经理,需要清楚知道公司目标...
NNI安装在本机(Windows版)
说了好几天的概念,再不动手真的会睡着。让我们先来本机炸一炸,加深我们的学习动机。 安装前,先注意两大...