[神经机器翻译理论与实作] 从头建立英中文翻译器 (V)
前言
今天继续训练阶段中的模型评估。
翻译器建立实作
模型评估
给定一个资料集(英、中文平行语句),为了 LSTM seq2seq 模型在该资料集上的翻译能力表现,我们依序进行下列任务:
- 指定原始资料集 seq_pairs_input ,其收录英文原文以及中文译文(事先给定的原始文本资料)
- 给定相对应该资料集的特徵资料 X_input ,其为经过 label encoding 的 [enc_inputs, dec_inputs]
- 针对资料集中的每一组成对的文句(语意相同英文与中文),让训练好的神经网络预测该句对(仅有一个样本的[enc_inputs, dec_inputs])
translated_sentence = pred_seq(model, single_seq_pair, reverse_tgt_vocab_dict)
- 比对真实文句( ground truth )以及模型翻译之文句( predicted )
for i in range(n_samples):
# extract true pair of sentences
src_sentence, tgt_sentence = seq_pairs_input[i]
# lists translation results of first five sentences
if i < 5:
print("source: {}\ntarget: {}\ntranslated: {}".format(src_sentence, tgt_sentence, translated_sentence))
- 计算整份文本资料的 corpus BLEU 分数以预测的 N-grams 占真实 N-grams 的比例
corpus_bleu(true, predicted, weights = (w1, w2, w3, w4))
将整个流程整理起来以定义下列函式:
def eval_NMT(model, X_input, seq_pairs_input, reverse_tgt_vocab_dict):
"""
Evaluates trained NMT model on a given dataset
------------------------------------------------
X_input:
[a few enc_inputs, a few dec_inputs]
date type: numpy array of shape: [(n_sentences, src_max_seq_length), (n_sentences, tgt_max_seq_length)]
seq_pairs_input:
source and target sentences
data type: list of list of strings
"""
# Step 0: Check shape and specify max_seq_length
print("shape of src_seqs: [{}, {}]".format(X_input[0].shape, X_input[1].shape)) # [(8000, 13), (8000, 22)]
true, predicted = [], []
src_max_seq_length = X_input[0].shape[1]
tgt_max_seq_length = X_input[1].shape[1]
# Step 1: Translate each sentence
for i in range(X_input[0].shape[0]): # 8000
# Step 2: Prepare training data of one sample (current sentence)
single_seq_pair = [X_input[0][i].reshape(1, src_max_seq_length), X_input[1][i].reshape(1, tgt_max_seq_length)]
# src_seq shape: [(?, 13), (?, 22)]
# Step 3: Predict a single sample and creates a string of tokens
translated_sentence = pred_seq(model, single_seq_pair, reverse_tgt_vocab_dict)
# Step 4: Collect ground truth sentences and predicted sentences
src_sentence, tgt_sentence = seq_pairs_input[i]
# lists translation results of first five sentences
if i < 5:
print("source: {}\ntarget: {}\ntranslated: {}".format(src_sentence, tgt_sentence, translated_sentence))
true.append([tgt_sentence.split()])
predicted.append(translated_sentence.split())
# Step 5: Calculate corpus BLEU scores on the dataset X_input
## Individual n-gram scores
print("Individual 1-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (1, 0, 0, 0))))
print("Individual 2-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (0, 1, 0, 0))))
print("Individual 3-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (1, 1, 1, 0))))
print("Individual 4-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (1, 0, 0, 1))))
## Cumulative n-gram scores
print("Cumulative 1-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (1, 0, 0, 0))))
print("Cumulative 2-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (.5, .5, 0, 0))))
print("Cumulative 3-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (.33, .33, .33, 0))))
print("Cumulative 4-gram score: {:.6f}".format(corpus_bleu(true, predicted, weights = (.25, .25, .25, .25))))
# evaluate model on training dataset
eval_NMT(eng_cn_translator, X_train, seq_pairs, reverse_tgt_vocab_dict)
# evaluate model on training dataset
eval_NMT(eng_cn_translator, X_test, seq_pairs, reverse_tgt_vocab_dict)
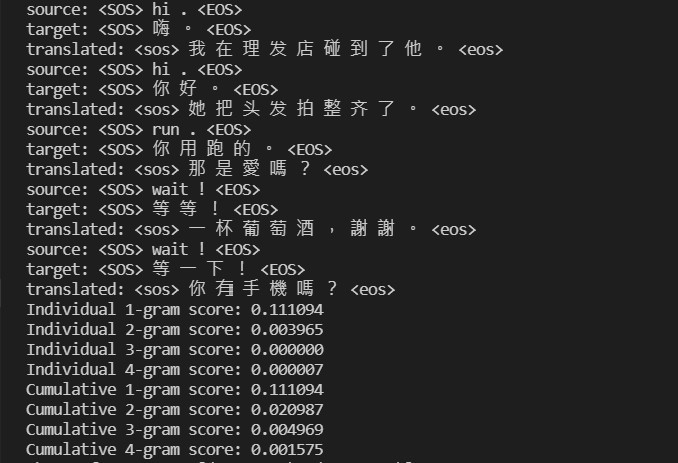
我们透过在训练资料集上检视模型的 BLEU 分数来评估其翻译能力:
接着在测试资料集上评估结果:
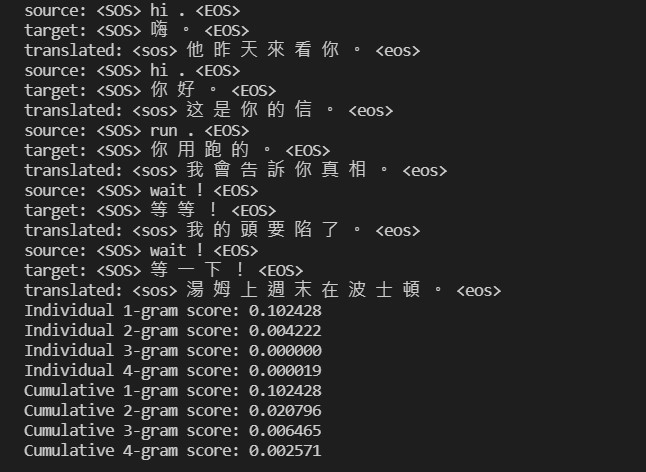
浏览了一下发现各个 N-grams 的 corpus BLEU 分数很低,让我不禁怀疑模型准确度是否极低下。
比对真实文句与翻译文句
给定模型与资料集,以下函式将会从资料集中随机抽出一笔样本进行翻译,来检视英文原文并比对中文原文以及中文译文:
import random
def translate_rand_sentence(model, X_input, reverse_tgt_vocab_dict):
"""
Translates a sentence at random in a specified dataset
"""
src_max_seq_length = X_input[0].shape[1]
tgt_max_seq_length = X_input[1].shape[1]
i = random.randint(0, X_input[0].shape[0] - 1)
# ground truth sentences
print("actual source sentence: {}".format(' '.join([reverse_src_vocab_dict[id] for id in X_input[0][i] if id not in [0, 1, 2]])))
print("actual target sentence: {}".format(''.join([reverse_tgt_vocab_dict[id] for id in X_input[1][i] if id not in [0, 1, 2]])))
# translated sentence
one_seq_pair = [X_input[0][i].reshape(1, src_max_seq_length), X_input[1][i].reshape(1, tgt_max_seq_length)]
print("predicted of NMT model: ", (''.join(pred_seq(model, one_seq_pair, reverse_tgt_vocab_dict).split()).lstrip("<sos>")).rstrip("<eos>"))
纵使 BLEU 分数不高,我们还是实际让模型在测试资料上随机抽选样本进行翻译,并检视翻译文句与真实文句之间的差异程度:
translate_rand_sentence(eng_cn_translator, X_test, reverse_tgt_vocab_dict)
前两次翻译皆有一字之差:


这次终於完全翻译正确了(泪

结语
後来我发现了 corpus BLEU 低下的原因在於我选定的文本特徵 X_input 与原始句对 seq_pairs_input 并不匹配,真是个天大的乌龙。因此明天会接着继续 debug ,各位晚安。
阅读更多
>>: 【领域展开 24 式】 WordPress 外挂目录中排名第一的 YoastSEO
Day 8 网路宝石:【Lab】VPC外网 Public Subnet to the Internet (IGW) (下)
今天我们继续完成【Lab】VPC外网 的下半部实作! 建立 EC2 instance 在此单元,我...
Day03 - 端到端(end-to-end)语音辨识
在前一天的最後有提到说透过类神经网路(DNN)使得从输入端到输出端只透过一个模型就完成语音辨识,像这...
Day 18 self-attention的实作准备(四) keras的compile和fit
前言 昨天讲到要如何建立model,今天来讲要如何训练以及预测 编译模型 建立完模型之後,必须呼叫c...
课堂笔记 - 深度学习 Deep Learning (9)
Mean Squared Error例题 Training examples (x, y): (1...
Day 21 民生公共物联网资料应用竞赛 线稿转精稿
(靠腰昨天网路好像挂掉,文没发出去) 来找设计师一起 side project,前後端 / UIUX...