Day27 - 动态模型 part2 (LSTM with attention)
回顾一下昨天提到的,我们希望透过将 attention 机制加到 LSTM 中藉此找出每段语音中重要的
部份。因此原本的 LSTM 架构就会修改成图 1
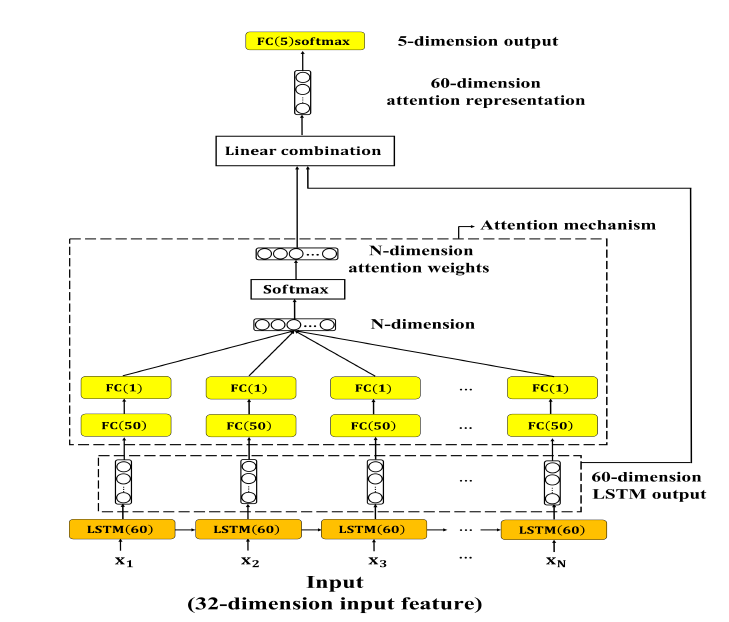
图1: LSTM with attention mechanism动态模型架构图
LSTM 由原本的两层改为一层(60 个神经元、activation function 为 tanh、ReLU),attention 的输入为LSTM 每一个时间点的输出 ,接下来使用两层的全连接层(FC, 第一层 50 个神经元,activation function 为 tanh、ReLU;第二层 1 个神经元,没有 activation function),第二层的输出以 softmax 转换成机率的形式,产生的向量即为每一个时间点
attention weights 。将
与前面 LSTM 每一个时间点的输出
相乘并将相乘结果加总,以
attention representation z 表示。Attention weights 与 LSTM 的输出相乘的结果即可解释为每一个时间点对於整段话语的贡献值。最後将 attention representation 传递至输出层。
其中 T 为输入序列中最大的时间点值而 、
为 attention 机制中两层全连接层的权重矩阵。
加入 attention module 後的模型程序如下:
dynamic_input = Input(shape=[max_length, args.dynamic_features], dtype='float32', name='dynamic_input')
lstm1 = LSTM(60, activation='tanh', return_sequences=True, recurrent_dropout=0.5, name='lstm1')(dynamic_input)
#attention mechanism module
attention_dense1 = Dense(args.attention_layer_units, activation='tanh', use_bias=False, name='attention_dense1')(lstm1)
attention_dense2 = Dense(1, use_bias=False, name='attention_dense2')(attention_dense1)
attention_flatten = Flatten()(attention_dense2)
attention_softmax = Activation('softmax', name='attention_weights')(attention_flatten)
attention_multiply = multiply([lstm1, attention_permute])
attention_representation = Lambda(lambda xin: K.sum(xin, axis=1), name='attention_representation')(attention_multiply)# 60
# classifier module
output = Dense(args.classes, activation='softmax', name='output')(attention_representation)
model = Model(inputs=dynamic_input, outputs=output)
model.summary()
分类结果如表 1。
| Model | UA recall (tanh) | UA recall (ReLU) |
|---|---|---|
| LSTM with attention | 47.2% | 20.0% |
表1: LSTM with attention 分类结果
加入 attention 後 UA recall 可以达到 47.2%,与 basic LSTM 相比有明显的提升。 另外,从 basic LSTM 与 LSTM with attention 中我们发现在动态模型中以 ReLU 为 activation function 的话 UA recall会很差只有 20.0%,原因应为使用 ReLU 为 activation function 的话,特徵值中所有负数的部份都会变为 0,使得 LSTM 会有多个时间点的输出皆为0,导致模型无法分类出此输入属於何种类别。
LSTM with attention 分类结果的混淆矩阵如下
| / | A | E | N | P | R | UA recall |
|---|---|---|---|---|---|---|
| A | 375 | 119 | 54 | 35 | 28 | 61.4% |
| E | 286 | 815 | 251 | 31 | 125 | 54.0% |
| N | 821 | 979 | 2,309 | 718 | 550 | 42.9% |
| P | 9 | 6 | 54 | 130 | 16 | 60.5% |
| R | 117 | 76 | 132 | 128 | 93 | 17.0% |
| Avg.recall | - | - | - | - | - | 47.2% |
表2: LSTM with attention 分类结果混淆矩阵
为了更进一步探讨 attention 机制的影响,我们将 attention weights 标准化至相同的时间范围(max_slot=100)後所得到分布图如图 2 (a), (b)。从图中我们可以观察到,平均而言,话语中间的部份通常比两边边缘的部份有着更大的 attention weights。这说明了情感表达通常都集中在语音中间的区段。
昨天的内容中有提到说为了让每一笔输入语音档长度相同我们会做 padding 补 0 的动作,因此在将 attention weights 视觉化的过程中需要将额外补 0 的部分排除 (delete_padding_part())
# attention_visualize.py
def delete_padding_part(data, seq_length):
no_padding_data = []
for i in range(data.shape[0]):
no_padding_start_pos = 2453 - seq_length[i]
temp = data[i][no_padding_start_pos:]
no_padding_data.append(temp)
no_padding_data = np.asarray(no_padding_data)
return no_padding_data
def avg_distribution(data, max_slot=100):
seq_slot_value = []
for i in range(data.shape[0]):# each sequence
interval = len(data[i])/max_slot
temp = []
slot_count = 0
j = 0.0
while slot_count < max_slot:# each slot
slot_sum = np.zeros(60)
count = 0
if math.floor(j) != math.floor(j+interval):
for k in range(math.floor(j), math.floor(j+interval)):
if k >= len(data[i]):
break
count += 1
slot_sum += data[i][k]
else:
slot_sum = np.zeros(60)
temp.append(slot_sum)
slot_count += 1
j += interval
seq_slot_value.append(temp)
seq_slot_value = np.asarray(seq_slot_value)
# calculate the average by each column
seq_slot_avg = []
for i in range(seq_slot_value.shape[1]):
col_sum = np.sum(seq_slot_value[:, i], axis=0)
col_sum_avg = col_sum / (seq_slot_value.shape[0])
seq_slot_avg.append(col_sum_avg)
seq_slot_avg = np.asarray(seq_slot_avg)
return seq_slot_avg
最後,从图 2 (c), (d) 的各类别 t-SNE 分布图中我们可以看出,不同类别资料的分布情形明显的重叠一起。
可透过 sklearn.manifold.TSNE 来实作
from sklearn.manifold import TSNE
def tsne(X, n_components):
model = TSNE(n_components=2, perplexity=40)
return model.fit_transform(X)
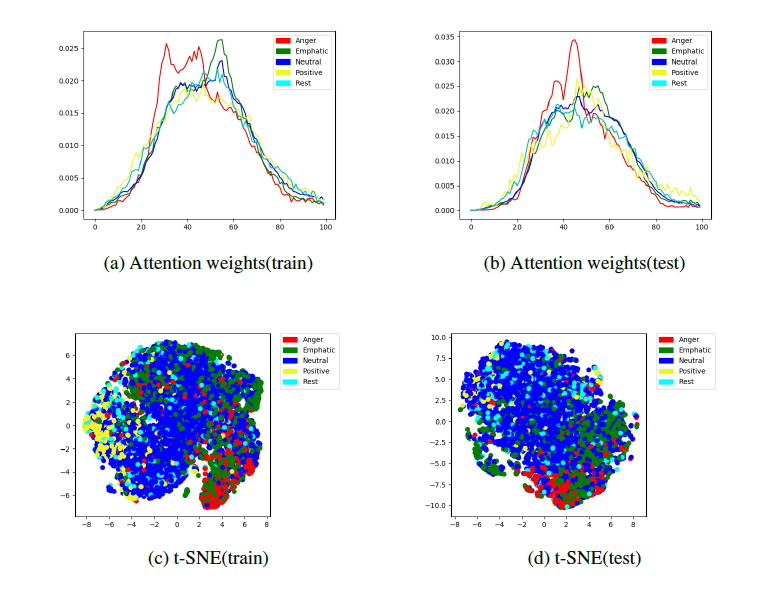
图 2: 训练集与测试集各类别 attention weights、t-SNE 分布图。红色:angry,绿
色:emphatic,蓝色:neutral,黄色:positive,青色:rest
介绍完了静态模型跟动态模型,明天我们将会使用藉由不同模型间的结合来提高模型效能的方法 - 集成学习 (ensemble learning)。
<<: 30天学习笔记 -day 24-Dagger (下篇)
>>: [Day 28] 第二主餐 pt.4-程序不求人,runserver背景执行及crontab自动执行
利用Redlock演算法实现自己的分布式锁
前言 我之前有写透过 lock or CAS 来防治,Racing condition 问题,但如果...
Thunkable学习笔记 5 - 使用者登入记录(Realtime Database读取与写入)
记录使用者最近五次的登入时间, 资料结构规划如下 1.记录使用者的email, 也是登入的帐号 2....
Day 22 (Js)
1.宣告a 赋值 null var a = null 赋值:数字、"字串"、nu...
数值系统与补数
本文目标 了解计算机如何储存资料 了解计算机如何处理负数以及减法 练习进制间的转换 进制系统 进位制...
Day8 GraphQL 介绍、在WordPress 上安装 WPGraphQL plugin
我们的系统架构很单纯,分为托管在 Vercel 上的 Next.js 前端,以及托管在 BlueHo...