[Day 22] Edge Impulse + BLE Sense实现唤醒词辨识(下)
=== 书接上回 [Day 21] Edge Impulse + BLE Sense实现唤醒词辨识(中) ===
重新训练
通常不满意模型训练出来的成果,可透过下列方式来调整。
- 新增资料集,增加多样性,并使各分类的样本数量平衡。
- 加入更强的背景杂讯(资料扩增手段),使模型更具强健性。
- 修改模型结构,使其更深、更广、更复杂、更有学习能力。
- 改变训练次数及学习率。目前学习率在「简易模式」操作画面时是采固定值,若想要动态调整则需进入「专家模式」自己修改优化函式(预设为Adam)及设定值。
- 其它「专家模式」参数。
变更调整後,可以於「Impulse design - NN Classifier」页面按下【Start Training】,或者在「Retrain model」页面按下【Train Model】重新训练模型即可。
模型测试
模型训练好了,当然要来验证一下。在前面章节资料有提到,除了训练集外,另有保留20%的测试集(4个分类各4笔, 共16笔资料),这些是没有参与训练过程的。接着进入「模型测试(Model Testing)」页面,按下【Classify all】就能自动把测试集全部内容进行推论,最後会得到每一笔资料的辨识结果和总体精确度,四个分类的混淆矩阵及特徵分布结果图,如图Fig. 22-1所示。系统预设是否分类正确的门槛值是0.6,如有需要可自行点击【Classify all】旁的点符号进入修改。如果不满意测试精确度,可参考「重新训练」小节的说明。
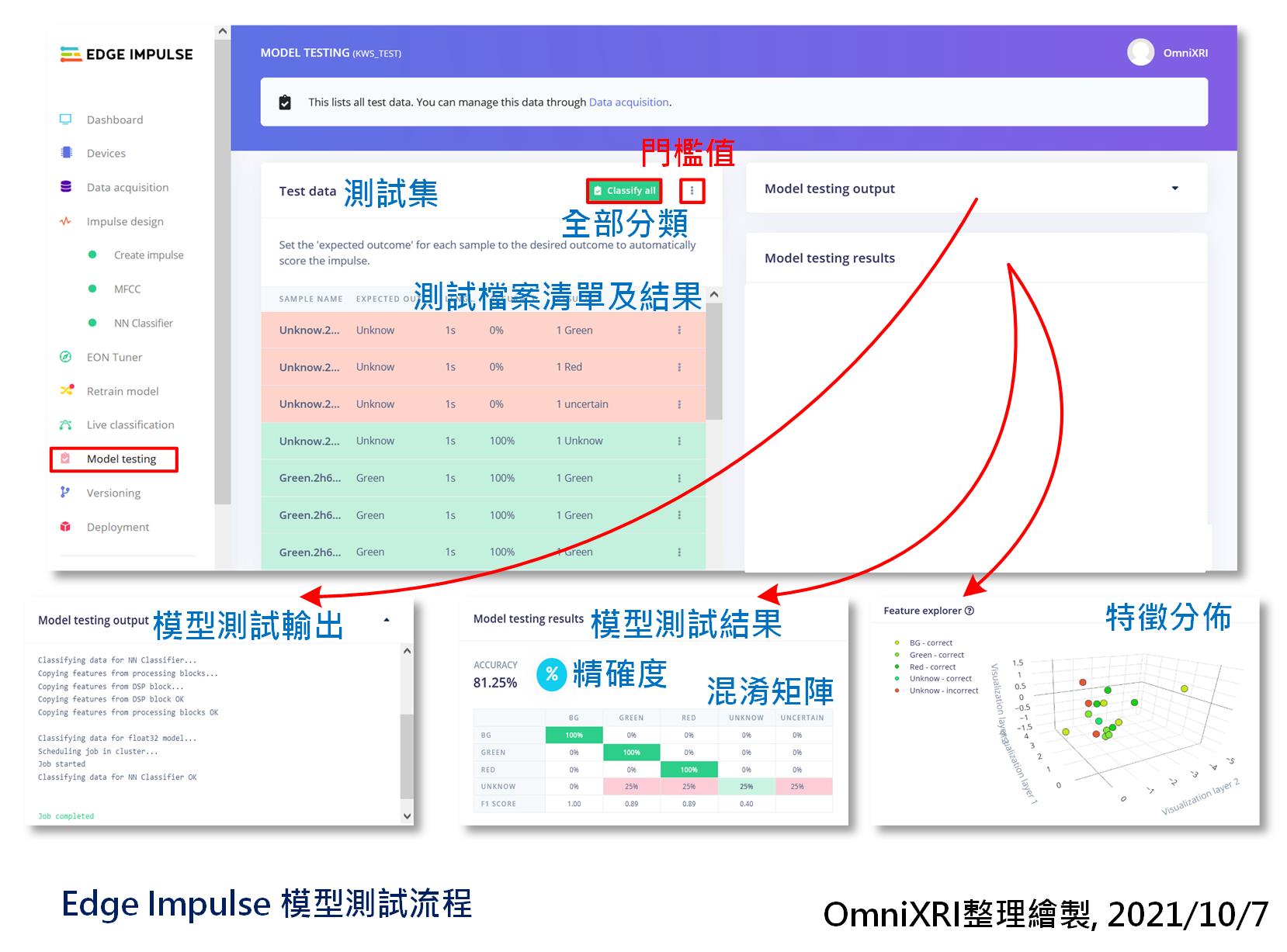
Fig. 22-1 Edge Impulse模型测试流程。(OmniXRI整理绘制, 2021/10/7)
即时分类
再来可即时收录一段声音来做测试。切换到「即时分类(Live Classification)」页面,设定取样时间长度及取样频率。通常可设长一点,10到20秒,可一次说出不同分类的单词内容(含不发声的背景声,单词间要有间歇),方便後面可一次测完不同分类。当按下【Start Sampling】等待数秒就会开始录制,完成後会自动上传到云端同时产出分类结果报告,包括各分类的统计数量、每笔资料每个分类的置信度(机率)。点击每资料还可观看对应的原始声音信号波形,按下三角形播放键时还可回听,方便检查分类是否正确。最後还会把所有分割出的内容特徵分布图展示出来。如图Fig. 22-2所示。
系统预设取样移动视窗为500ms,一次撷取1000ms来分类,这里不像前面资料撷取时有自动分割的功能,而是模仿在MCU上连续不停的取样分析,所以如果对於移动距离和检测门槛值不满意时可自行调整。
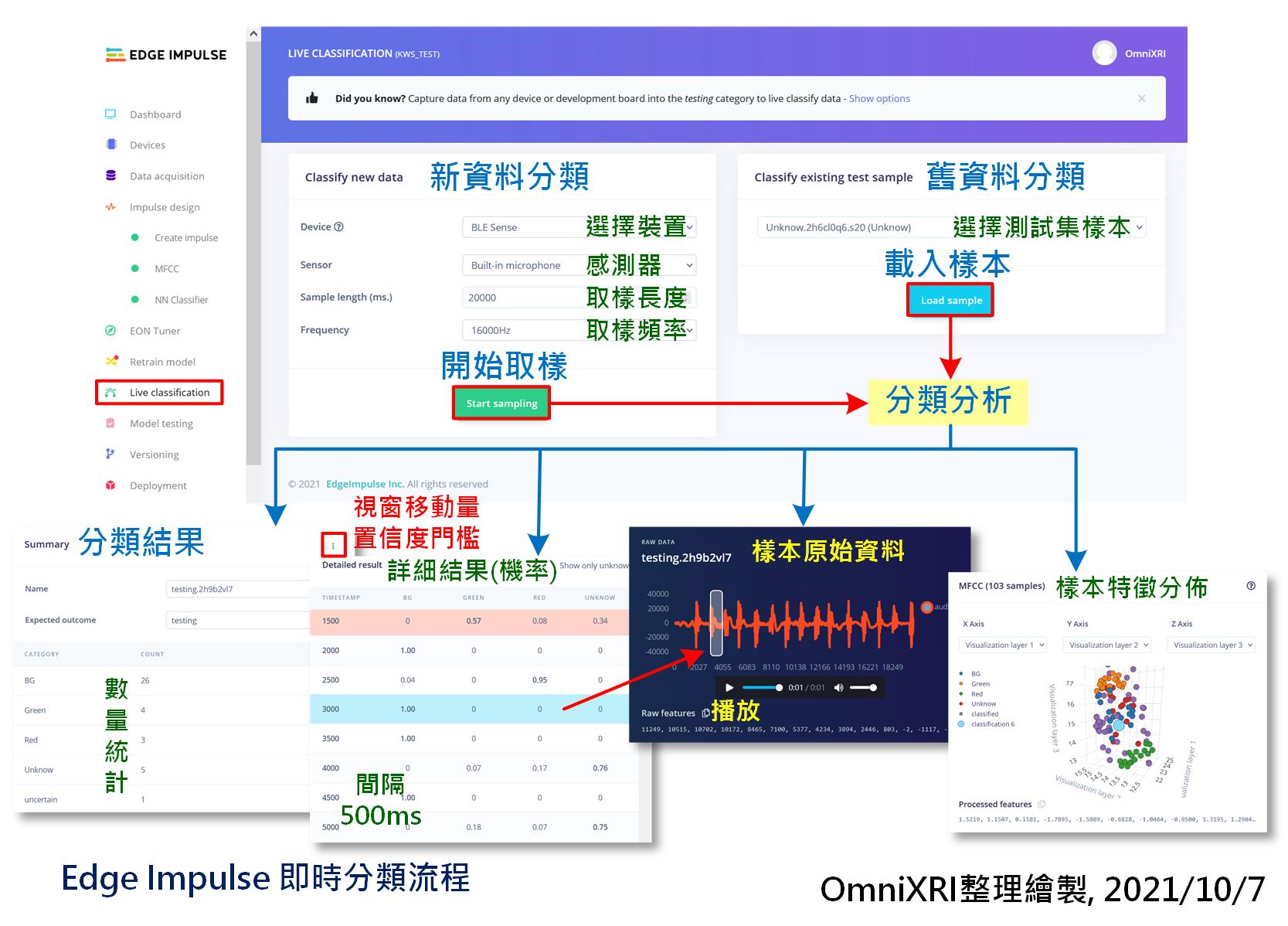
Fig. 22-2 Edge Impulse即时分类流程。(OmniXRI整理绘制, 2021/10/7)
参数调校(EON Tuner)
这是Edge Impulse 2021/9 才刚推出的新功能,可暂时忽略跳过这个步骤。EON全名Edge Optimized Neural Tuner。顾名思义这是一项AutoML的工具,可叫系统花点时间帮你找最佳的MCU AI模型。但现想很丰满,现实很骨感,其表现是否会比有经验工程师设计的模型来的表现更好,就有待观察,这里就暂时略过说明。有兴趣的朋友可先参考官方释出的Youtube说明影片。
版本管理
如果想要记录训练出的基本资料,Edge Impulse也有支援云端储存备份的功能,进到「版本管理(Versioning)」页面,按下左上角【Store your current project version】即可记录下目前版本的重要资讯,达到MLOps的基本能力,其主要动作如下显示。
/* Edge Impulse 版本管理主要动作 */
[1/9] Retrieving project and block configuration...
[2/9] Classifying test data...
Generating features for MFCC...
Classifying data for NN Classifier...
Classifying data for float32 model...
[3/9] Creating C++ library...
[4/9] Retrieving 81 data items...
[5/9] Writing data...
[6/9] Waiting for S3 mount to become available...
[7/9] Archiving files...
[8/9] Uploading version...
[9/9] Storing version x...
模型布署
好不容易训练、测试、调整好的模型,最後还是得布署到开发板上,让MCU直接运行才算是真的tinyML, Edge AI,相关流程如图Fig. 22-3所示。目前Edge Impulse提供两种方式布署,如下所示。
-
产生函式库:产生函式库源码及基本动作主程序,方便开发者再加入自己的程序码後,再以对应的IDE进行编辑组译。目前可支援下列类型。
- C++ (Windows, Linux, MacOS...)
- Arduino
- Cube.MX CMSIS-Pack (STM32)
- WebAssembly
- TensorRT (Nvidia)
-
产生烧录档:直接产生指定开发板的二进制烧录档案(*.bin, *.hex等),再以Edge Impulse提供的烧录程序把档案烧进开发板中。这样的好处是不用写半行MCU程序,而运行後会将辨识结果字串透过虚拟序列埠送出,电脑端接收到後再自行对应到其它程序及人机界面上。目前支援下列开发板。
- ST IoT Discovery Kit
- Arduino Nano 33 BLE Sense
- Eta Compute ECM3532 AI Sensor
- Eta Compute ECM3532 AI Vision
- SiLabs Thunderboard Sense 2
- Himax WE-I Plus (奇景光电)
- Nordic nRF52840 DK + IKS02A1
- Nordic nRF5340 DK + IKS02A1
- Nordic nRF9160 DK + IKS02A1
- Sony Spresense
- Linux boards
Edge Impulse云端这边,同时只能二选一输出,当选择好了,页面下方会出现RAM, Flash使用量、推论时间(Latency)、模型精确度及混淆矩阵。另外还可依使用资源及推论效果来选已量化成8位元整数(INT8),或者未量化前的32位元浮点数(Float32)的模型输出。最後按下【Build】就会开始建置,前者只是转出源码,所以速度较快,而後者要完整编译,所以要等比较久一点。当完成後,两者都会产生一个ZIP格式压缩档。
另外最近Edge Impulse刚推出EON编译器(和前面提到的EON Tuner工作内容不同),可再对模型进行深度优化,号称最高可达50%的简化,但从图表上的数字来看,这个模型太小,所以降幅也不大。可自行选是否要开启这项功能,没有强制性。或者输出两种,再自行比对其表现性。
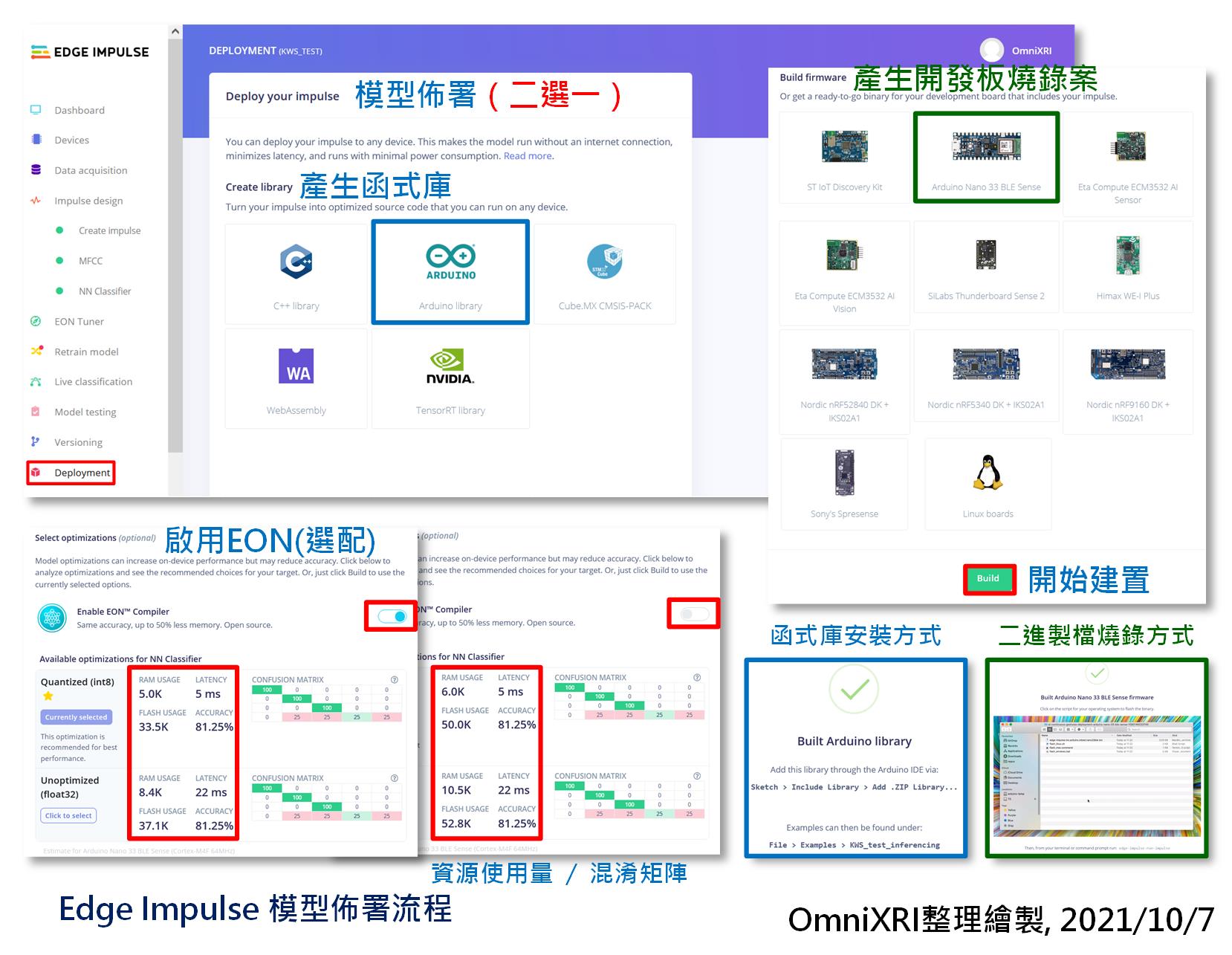
Fig. 22-3 Edge Impulse 模型布署流程。(OmniXRI整理绘制, 2021/10/7)
接着说明如何将程序烧录到开发板上,同样地也有两种模式,可以自行选择。
-
直接烧录:
以「Arduino Nano 33 BLE Sense」为例,解压缩kws_test-nano-33-ble-sense-v4.zip(kws_test为专案名称,会依实际专案名称而不同)後会得到二进制档(MCU韧体)firmware.ino.bin和烧录程序档flash_windows.bat(windows用),执行後者就能把程序烧进开发板中。 -
使用Arduino IDE编译上传:
开启Arduino IDE前,记得把「edge-impulse-daemon」的命令列视窗关闭,以免占住序列埠的使用权,导致後面编译好的程序无法上传。接着开启Arduino IDE,点选[主选单]-[草稿码]-[汇入程序库]-[加入ZIP程序库...],选择刚才Edge Impulse产出的ei-kws_test-arduino-1.0.3.zip(kws_test为专案名称,会依实际专案名称而不同)。接着点选[主选单]-[档案]-[范例]-[KWS_test_inferencing]下的[nano_ble33_sense_microphone_continuous]产生可执行麦克风连续收音的范例程序。按左上角快捷键箭头符号按键,进行MCU程序编译及上传。完成上传後,点选[主选单]-[工具]-[序列埠监控视窗]开启监控视窗(预设鲍率115,200bps),就能看到辨识结果的字串不断的更新。此时对着开发板的麦克风说「红」、「绿」或其它中文单词及不说话(背景音)来测试输出的字串及对应的置信度(机率)是否正确。完整的程序如图Fig. 22-4所示。
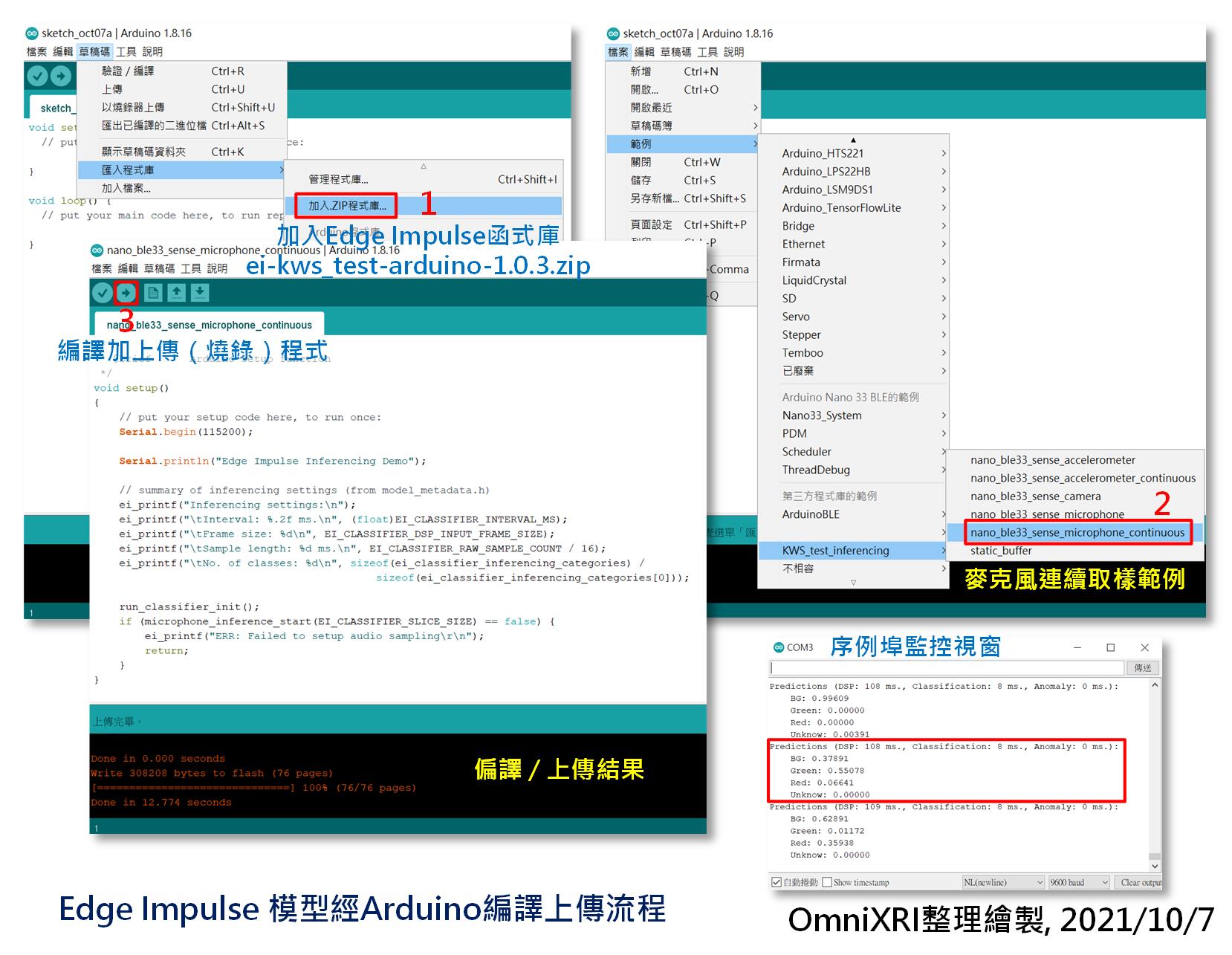
Fig. 22-4 Edge Impulse 模型经Arduino编译上传流程。(OmniXRI整理绘制, 2021/10/7)
小结
经过连续三天的介绍,恭禧大家终於完成第一个tinyML专案,自定义中文单词(唤醒词)辨识。有没有感觉透过这样一站式开发工具比起[Day 16]、[Day 17]介绍的方法节省了不少力气,尤其是开发环境建置和资料集建置。後续还有更多案例分享,敬请期待。
参考连结
Edge Impulse Tutorials - Responding to your voice 说明文件
AI Tech Talk from Edge Impulse: EON Tuner: AutoML for real-world embedded devices
Edge Impulse Tutorials - Running your impulse locally
#15 JS: if else statement
To make the operators meaningful for users, let’s ...
Day 3.环境预备备(一)-VSCode的加入
先来谈谈IDE是什麽吧! IDE,Integrated Development Environmen...
Day26 Flutter 的状态管理 Provider (五) Firebase Login
main,dart: import 'package:firebase_core/firebase_...
Spring Framework X Kotlin Day 8 REST Clients & OpenAPI
GitHub Repo https://github.com/b2etw/Spring-Kotlin...
[Day 30] Ktor Q&A 与 Side Project Roadmap
终於来到铁人赛最後一天,本来想回顾总结我实作 side project 的过程,但想到读者应该对於 ...