Day 21 - [语料库模型] 09-回馈机制
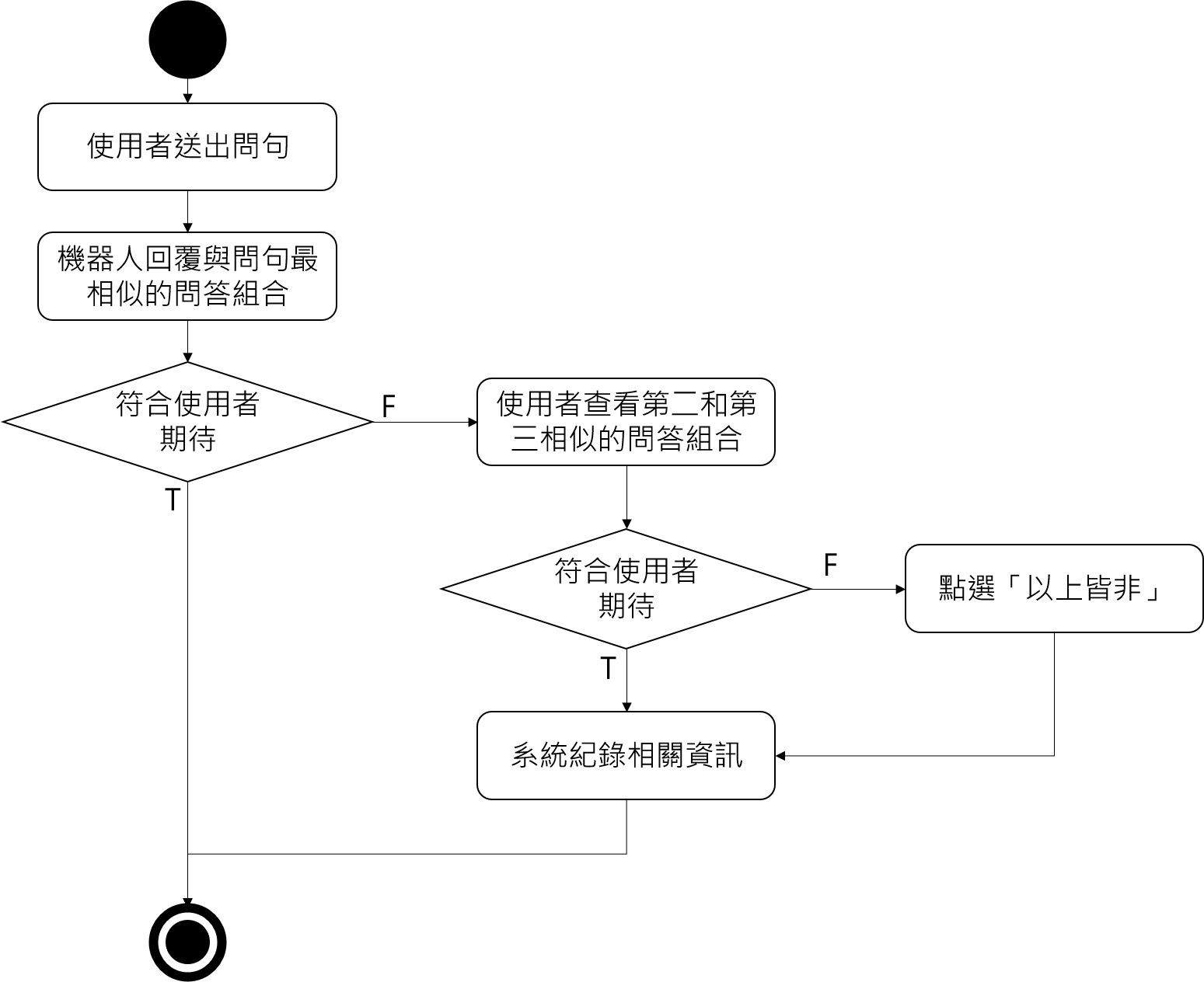
聊天机器人虽有问答集可以回覆大部分常见问题,但难免会有疏漏。因此本研究亦设计回馈机制,若使用者发现机器人的回覆内容不符合想预期,可以直接查看与问句第二和第三相似的问答组合,或是点选「以上皆非」选项,两种方式系统都会自动记录相关资讯。後续我们便可整理蒐集到的组合,持续优化聊天机器人与扩增问答集。
「[语料库模型] 07-程序码: 余弦相似性」这篇的程序码会回传相似度最高的 3 个问答组合。
回馈纪录使用与问答集相似的 CSV 格式储存,方便整理後移植到资料集中。
- 回馈纪录的 log
连结: https://gitlab.com/graduate_lab415/nlp/-/blob/master/output/adjustments.bk.csv

- 问答集(语料库)
连结: https://gitlab.com/graduate_lab415/nlp/-/blob/master/docs/fixed_file_1622789141_remove_duplicate_labeled_renumber.csv
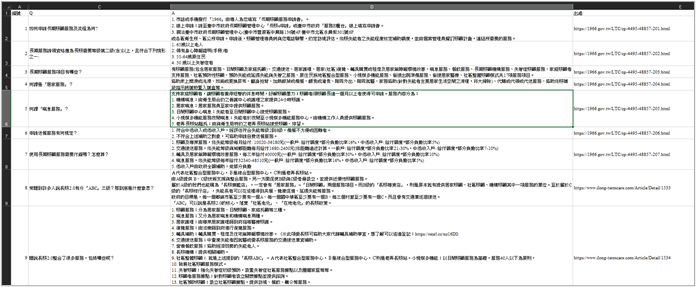
比较不同的是,回馈纪录的 Q 栏位代表的是使用者输入的语句,A 栏位则会根据使用者的选择而有不同,主要分为两种情况。
-
情况一,点选其他相符的选项
使用者输入「申请喘息服务」,而机器人一开始回覆的问答组合不符预期,所以使用者点选查看第三相符的问答组合「总则(给付八)_独居长辈是否能使用喘息服务」,因此可以判断「使用者输入的语句」与「第三相符问答组合的答案」较相符,并将此新的问答组合储存於回馈纪录中。
-
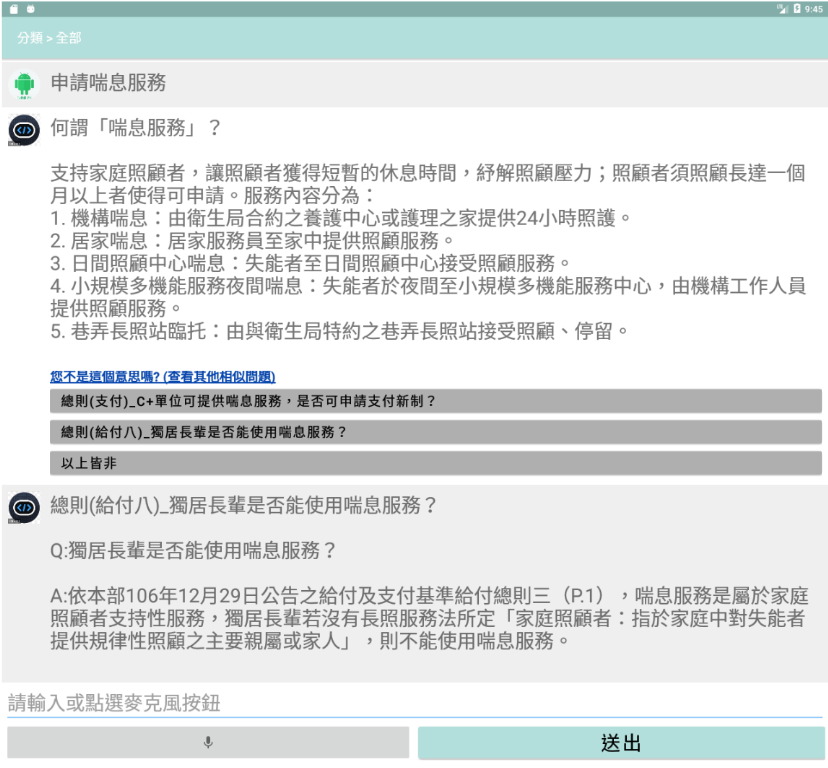
情况二,点选「以上皆非」
使用者输入「外籍看护来自哪一国」,而机器人回覆的内容都不符合使用者期待,所以他选择「以上皆非」,代表此问题对我们问答集来说是新问题,因此回馈纪录就会记录一笔新的问答组合。
程序码
程序码: https://gitlab.com/graduate_lab415/nlp/-/blob/master/add_adjustment.py
这部分的程序码,是为了让 API 可以将回馈纪录写进档案
接收参数
param = sys.argv
q = param[1] #使用者输入的问句
qa_id = param[2] #使用者认为较贴切的问句,若都不符合则传送 -1
category_id = param[3] #使用者当下选择的类别编号
可以接收像是这样的参数
python3 add_adjustment.py "申请喘息服务" 359 0
判断是否为新问题
新问题是指使用者选了「以上皆非」,也就是说使用者认为他的问句和我们提供的都不相似,我们把这种状况认为是新问题。
if qa_id == "-1":
result['new_question'] = True
answer = ""
remark = "New Question"
else:
result['new_question'] = False
qa = os.popen(
"/home/yr/PycharmProjects/nlp/venv/bin/python3 /home/yr/PycharmProjects/nlp/get_answer_by_id.py " + qa_id).read()
qa = json.loads(qa)
answer = qa['A']
remark = "Origin Question "+qa['Q']
result 是用来记录状况,印出最後的 JSON 档案的。
remark 就是备注,若是新问题,备注就会记录 "New Question";反之,则纪录使用者认为更贴近问题。
answer 是针对使用者的问句,若是新问题,就留空,待後续维护人员评估;反之,使用编号 359 查出问答组合,并把答案的部分存到 answer。

将记录写入档案
file_exist = os.path.isfile("/home/yr/PycharmProjects/nlp/output/adjustments.csv")
csv_file = open("/home/yr/PycharmProjects/nlp/output/adjustments.csv", "a+")
writer = csv.writer(csv_file, delimiter=',')
'''Add CSV Title'''
if not file_exist:
csv_file = open("/home/yr/PycharmProjects/nlp/output/adjustments.csv", "w")
writer = csv.writer(csv_file, delimiter=',')
writer.writerow(['id', 'Intent ID', 'Q', 'A', 'category', 'source', 'time', 'remark'])
'''Add Row'''
csv_file = open("/home/yr/PycharmProjects/nlp/output/adjustments.csv", "a+")
writer = csv.writer(csv_file, delimiter=',')
new_row = ['', '', q, answer, category_id, 'User Input', str(datetime.datetime.now()), remark]
首先检查 adjustments.csv 档案是否存在,若不存在,就开个新档,并把栏位名称写进去。
档案已存在,就把纪录直接写到档案的最後一笔。
w: 开新档 & 写入
a+: 用附加方式打开(资料会加在档案最後,不会把前面的内容洗掉) & 可读写
检查写档是否成功
success = writer.writerow(new_row)
if success > 6:
'''
new_row = ['', '', '', '', '']
because len(new_raw) is 6
'''
result['success'] = 1
else:
result['success'] = -1
这部分可能没写很好,未来可以再修正写法。
主要是想以 new_row 的长度来决定是否有新增成功,判断的时候又遇到一些问题,不太了解为何 len(['', '', '', '', '']) 的结果是 6,就先将错就错,若是长度有大於 5 个空字串的 list,就算他成功吧。
印出 JSON
print(json.dumps(result, ensure_ascii=False))
印出刚刚准备的 result,回馈机制的 API 就完成了!
{
"new_question": true,
"success": 1
}
<<: 【DAY 21】为什麽每天可以有这麽多问题?如果有机器人可以帮帮我就好了!— Microsoft Power Virtual Agents 智慧虚拟助理来罗~
[火锅吃到饱-14] 陈师傅麻辣火锅 #营业到半夜两点
先附上店家的Google Maps,跟消费方式: 双十国庆连假开始... 一个月没发片了,原本的预定...
EP 10 - [TDD] Message 加密及解密 (2/2)
Youtube 频道:https://www.youtube.com/c/kaochenlong ...
NIST SP 800-88 R1媒体消毒准则(Guidelines for Media Sanitization)
NIST SP 800-88 R1引入了三种消毒方法:清除(clear),清除(Purge)和销毁(...
ASP.NET MVC 从入门到放弃(Day8) -C# try catch常见异常和自定义异常 using 介绍
接着来讲讲try catch 部分.... 一般来说是要避免程序因为出现错误讯息挂掉的处理方式......
用 Python 畅玩 Line bot - 21:LIFF(一)
LIFF 是一种 Line 提供让 line bot 可以不跳脱 Line 去开启网页的 API。 ...