【21】不同的模型权重初始化 (Weight Initialization) 对应的使用方式
有关权重如何初始化也是个各派不同的训练方法,从 tf.keras 官方文档就看到一大堆的初始化方式,对於开始接触的人来说,还真是头痛。
我们知道如果权重分布变异数大,会容易导致梯度爆炸,相反地,如果权重分布的变异数小,容易导致梯度消失,模型很难更新,理想上的权重分布是平均为0,各层的标准差数值差不多,对模型的学习来说是最健康的。
而今天我挑了几个初始化方式来跟大家介绍,并且会个别训练模型看看会发生什麽事。
模型用昨天自己打造的 mobilenetV2,并设计了一个 func 方便将初始化方式导入。
def bottleneck(net, filters, out_ch, strides, weight_init, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same', kernel_initializer=weight_init)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding, depthwise_initializer=weight_init)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same', kernel_initializer=weight_init)(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_relu(shape, weight_init):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same', kernel_initializer=weight_init)(input_node)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same', depthwise_initializer=weight_init)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same', kernel_initializer=weight_init)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), weight_init, shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), weight_init, shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), weight_init, shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), weight_init, shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), weight_init, shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), weight_init, shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), weight_init, shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), weight_init, shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), weight_init, shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), weight_init, shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), weight_init, shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), weight_init, shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), weight_init, shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), weight_init, shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), weight_init, shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), weight_init, shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same', kernel_initializer=weight_init)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
return input_node, net
由於模型是从头开始训练的,资料集使用 cifar10,共有10种分类,但每个分类的张数很多,训练10个 epochs 就将尽需要花费一个小时。

实验一,RandomNormal
这个初始方式指定平均和标准差之後,便会在该数值间产生对应的常态分布。
WEIGHT_INIT='random_normal'
input_node, net = get_mobilenetV2_relu((224,224,3), WEIGHT_INIT)
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
rdn_history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 0.4510 - sparse_categorical_accuracy: 0.8434 - val_loss: 0.7016 - val_sparse_categorical_accuracy: 0.7788
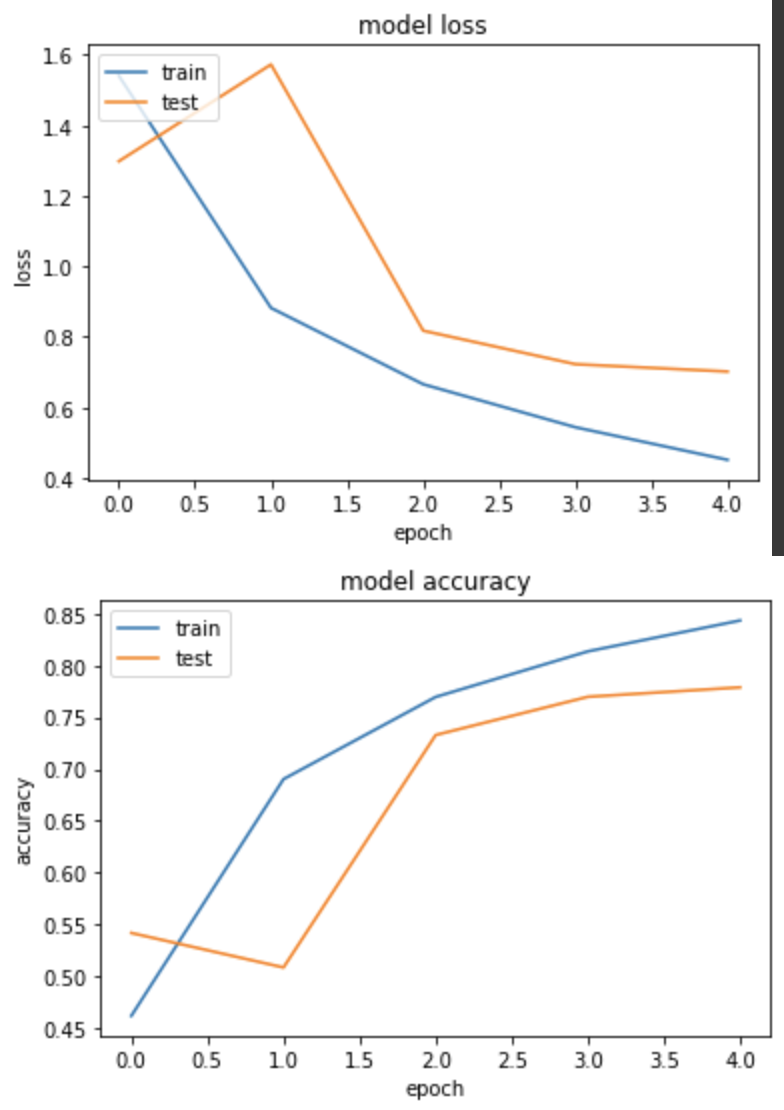
实验二,GlorotNormal (Xavier)
第一次看到这个名称有点陌生,但查了之後才知道其实就是 Xavier 初始化,这篇文章举了一个很棒的例子,正向传播时,假设我们的输入都是1,如果我们原本用 RandomNormal 产生了 mean=0, std=1 的乱数,那经过这层 layer 得到的输出为 z,这个 z 的 mean仍然会是0,但是std会大於1,为了压低变异数,我们会把原先的初始化范围再缩小 1/sqrt(n) 倍。
WEIGHT_INIT='glorot_normal'
input_node, net = get_mobilenetV2_relu((224,224,3), WEIGHT_INIT)
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
glorot_history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 0.4442 - sparse_categorical_accuracy: 0.8459 - val_loss: 0.5632 - val_sparse_categorical_accuracy: 0.8206
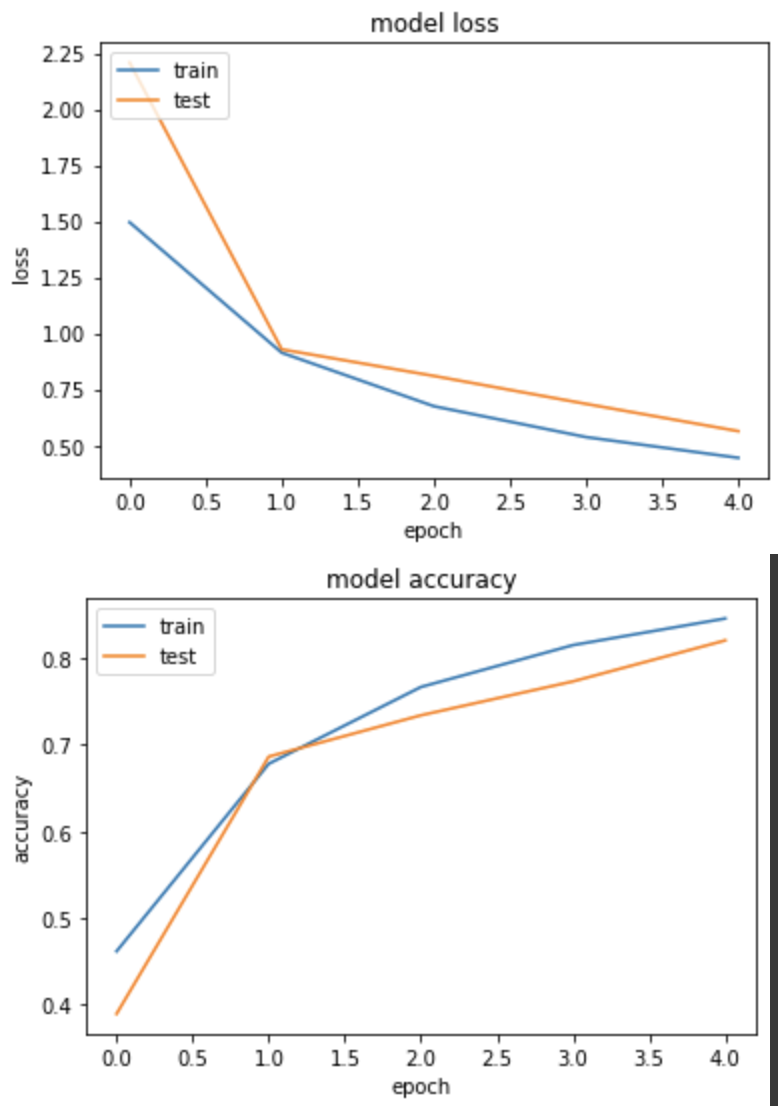
使用 Xavier 拿到比实验一略好的结果。
实验三,HeNormal
由於目前主流的 Act function 几乎都使用 ReLU,而 ReLU 的微分不是0就是一个正数,变异数是 Xavier 的2倍。
WEIGHT_INIT='he_normal'
input_node, net = get_mobilenetV2_relu((224,224,3), WEIGHT_INIT)
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
he_history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 0.4585 - sparse_categorical_accuracy: 0.8408 - val_loss: 0.8109 - val_sparse_categorical_accuracy: 0.7348
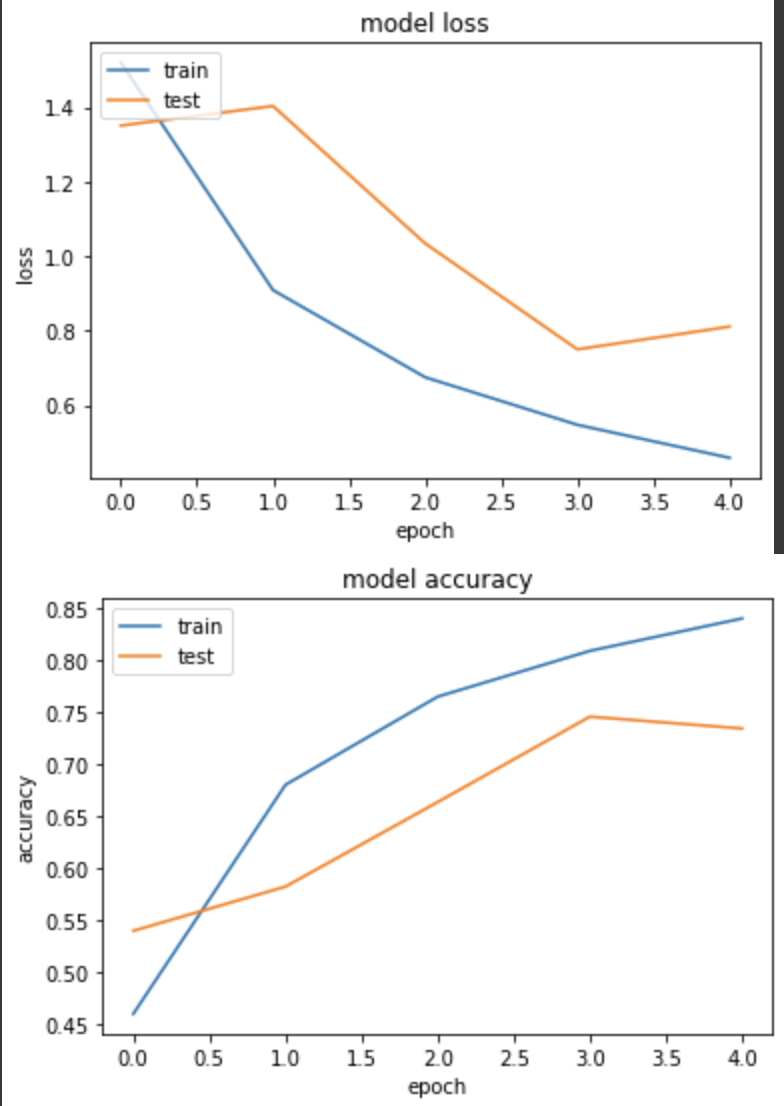
但结果仍输给 Xavier。
实验四,LecunNormal
在 ReLU 问世後,接着有其他各种变形的 ReLU 相继出现,其中 SELU 也是其一,而且发现使用 SELU 时,权重初始化搭配 LecunNormal 使用时,效果特别不错。
而为了 Demo,我将原先 mobilenetV2 的 Act func 替换成了 SELU 来测试。
def bottleneck(net, filters, out_ch, strides, weight_init, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same', kernel_initializer=weight_init)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.activations.selu(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding, depthwise_initializer=weight_init)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.activations.selu(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same', kernel_initializer=weight_init)(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_selu(shape, weight_init):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same', kernel_initializer=weight_init)(input_node)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.activations.selu(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same', depthwise_initializer=weight_init)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.activations.selu(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same', kernel_initializer=weight_init)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), weight_init, shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), weight_init, shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), weight_init, shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), weight_init, shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), weight_init, shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), weight_init, shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), weight_init, shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), weight_init, shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), weight_init, shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), weight_init, shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), weight_init, shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), weight_init, shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), weight_init, shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), weight_init, shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), weight_init, shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), weight_init, shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same', kernel_initializer=weight_init)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.activations.selu(net)
return input_node, net
训练
WEIGHT_INIT='lecun_normal'
input_node, net = get_mobilenetV2_selu((224,224,3), WEIGHT_INIT)
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
lecun_history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 0.7519 - sparse_categorical_accuracy: 0.7345 - val_loss: 1.1013 - val_sparse_categorical_accuracy: 0.6193
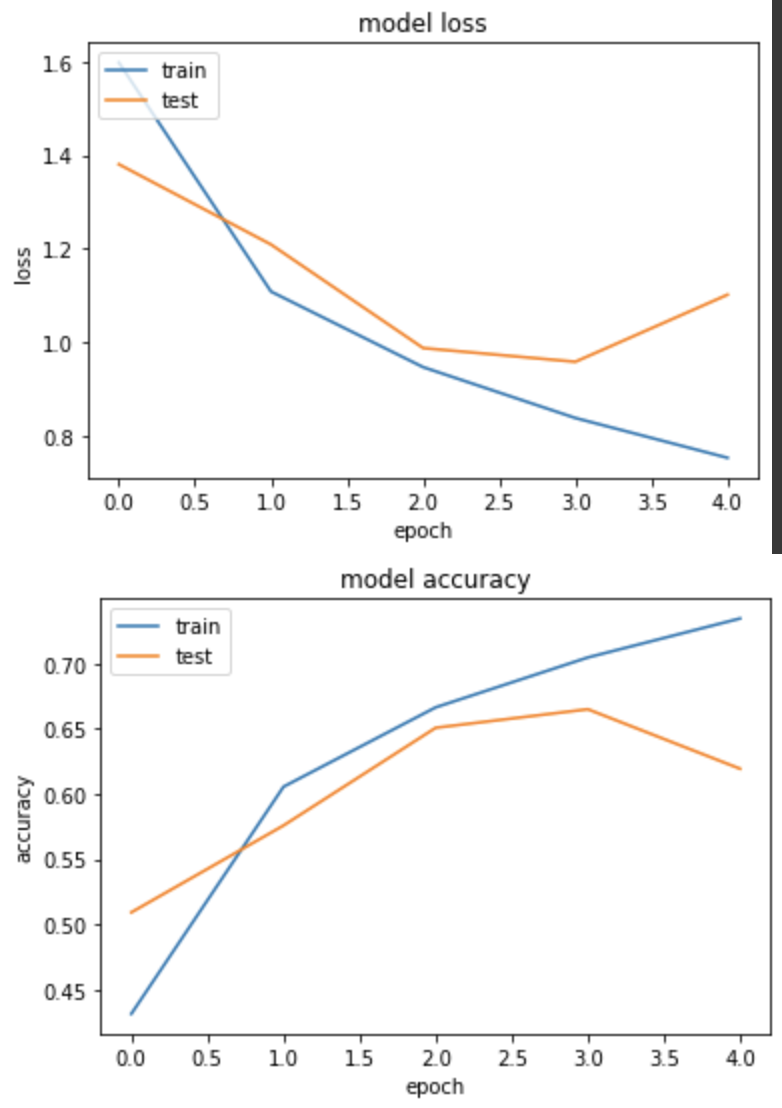
但结果没有训练出比较好的模型...
结论:
尽管上述每个实验的准确度差异有些大,蛮有可能是因为我 epoch 只设5个关系,但可以看到模型都有确实在收敛学习中。
最後整理一下理想的 Act func 对应的权重初始化方式:
- sigmoid, tanh, softmax -> 使用 Xavier/Glorot 初始化
- ReLU -> 使用 He 初始化
- SELU -> 使用 LeCun 初始化
<<: [13th][Day20] http request header(下)
Day 30 GUI
在JAVA程序设计中,如果要设计元件的话,要用GUI,也就是图形使用者介面,今天我们要使用GUI创建...
Day 06 CSS <复合选择器>
CSS的选择器分为基础选择器以及复合选择器 本日将将继续说明复合选择器 复合选择器可以更准确更高效的...
【Side Project】 订单清单 - 未完成清单(後台资料传前台&动态生成html)
我们这篇会一次从取得资料库的订单资料一直到动态生成html语法生成未完成清单的画面。 取得资料库资料...
Day04:自我增进技术能力与观念的小方法
一、前言 上一篇文章的结尾有提到大家可以在职场上定时自我检视的小习惯,这边分享我自己维持几个月後...
Day 22 : Linux - 如何让解析度随着视窗大小改变?又该如何让windows和Linux的复制贴上通用?
如标题,想必大家一定很困扰Linux的视窗问题,因为它的预设值是800X600,如果像上篇讲的改成1...