Day22 - 前处理: 资料平衡&Label 调整
在 Day20 介绍资料集时有提到过五类情绪有资料不平衡的问题,为了处理资料不平衡的问题,我们会在 loss function(crossentropy)上加入一与类别资料量呈反比的类别权重。对於每一笔资料样本 i ,假设 为实际的标注向量而
模型预测所输出的向量,则 loss function 会以下列的公式呈现:
其中C为类别数, 为每笔资料样本 i 的类别权重,N 为训练资料总量,
为样本 i 所属类别的训练资料量。round 运算表示将数字取四舍五入至小数点後第一位。主要的
想法为资料平衡,强调资料量少的类别其资料样本的错误和不强调资料量多的类别其资料样本的错误,经过计算後各类的类别权重如值表 1。
| / | Angry | Emphatic | Neutral | Positive | Rest |
|---|---|---|---|---|---|
| weight | 1.1 | 0.5 | 0.2 | 1.5 | 1.4 |
表1: 各类别权重
Label 调整的部份我们会先使用训练集训练一分类器(A)对训练集进行分类,透过 A 分类器每一笔训练样本都会得到一输出向量,将此向量作为新的 train label。因此原本以 one-hot vector 表示的 train label 会转变为包含五类机率的向量。接着我们使用新的 train label 训练另一分类器(称B)。训练流程如图 1。
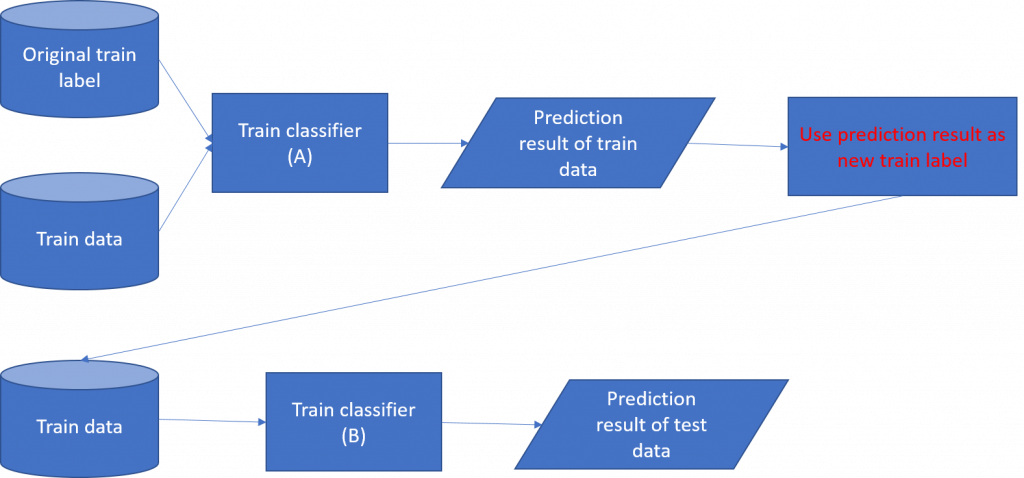
图 1: 处理 noisy label 训练流程图
使用此方式训练的目的在於处理语音情绪中 noisy label 的问题。我们所使用的语料库是由多名语言学家进行标记的,不同学家对於语音情绪的感知可能会不同。实际上,每一笔样本所被标记的类别可能不会被所有的语言学家同意,因此它可以被视为 noisy label。一般来说,机器学习的分类系统不希望出现 noisy label。藉由改变标记的方式,我们能够使模型对於本质上有 noisy label 具有更好的学习能力。
>>: [Day 20] - 『转职工作的Lessons learned』 - GraphQL (Hasura) - 身份级别权限设定
Day_20 DNS/DDNS/Port Forwards (一)
先前介绍的几个网路架构,多数提到的IP都是在区域网路之内设备上的部份,但如果连上外网,这些资讯封包就...
Day 11. Hashicorp Nomad: Sidecar task
Hashicorp Nomad: Sidecar task 在Day 9. Hashicorp No...
Extra05 - Docker - 容器化
此篇为番外,未收入在本篇的原因是 Docker 是个复杂的工具,因此需要更多的篇幅介绍此工具,但是...
[DAY 26]随机组队功能
公会成员平均在线成员人数有90位,但实际在discord频道活跃人数不到20位 为了让非活跃在线人数...
Day 17 : 案例分享(5.3) CRM与ERP整合 - 商机与报价 及相关整合介绍
案例说明及适用场景 每一个商机都有公司对他的期望值(金额) 商机不论成功或失败与否,长期的记录,能有...