[Day 21] Facial Recognition: 只需要OpenCV就可以达成即时人脸辨识
昨天的内容还可以吸收吗?
也许有人会问:
这些神经网路模型还有GPU、CUDA什麽的我都不懂,能不能有一个最简单的方式做即时人脸辨识?
也许Google ML Kit比较适合你
OpenCV除了之前提到的,专门处理影像相关功能之外,
它提供了一系列的接口让你可以载入各种模型 (只要有办法转成OpenCV支援的模型格式)
-
cv2.dnn.readNet -
cv2.dnn.readNetFromCaffe -
cv2.dnn.readNetFromONNX -
cv2.dnn.readNetFromTorch -
cv2.dnn.readNetFromDarknet -
cv2.dnn.readNetFromModelOptimizer -
cv2.dnn.readNetFromTensorflow
对,基本上想得到的想不到的模型格式它都支援了,
而OpenCV会自动载入模型结构,
你要做的就是给它输入跟得到输出而已。
由於今天的目的是用最简洁的方式来应用人脸侦测
我们只会使用OpenCV来做人脸侦测与人脸辨识的工作,
当然,还是需要有资料。
我们就开始吧!
本文开始
- 开启之前的专案,参考这一篇准备资料:
- 在专案的
face_recognition下新增一个档案opencv_realtime.py - 程序码与相关说明:
import ntpath import sys # resolve module import error in PyCharm sys.path.append(ntpath.dirname(ntpath.dirname(ntpath.abspath(__file__)))) import argparse import numpy as np import os import time from urllib.request import urlretrieve import cv2 from imutils.video import WebcamVideoStream from imutils.video import FPS from sklearn.preprocessing import LabelEncoder from sklearn.svm import SVC from dataset.load_dataset import load_images from face_detection.opencv_dnns import detect # 下载模型相关档案 embedder_model_url = "https://storage.cmusatyalab.org/openface-models/nn4.small2.v1.t7" embedder_model = "nn4.small2.v1.t7" if not os.path.exists(embedder_model_url): urlretrieve(embedder_model_url, embedder_model) def main(): # 初始化arguments ap = argparse.ArgumentParser() ap.add_argument("-i", "--input", type=str, required=True, help="the input dataset path") args = vars(ap.parse_args()) # 初始化要使用到的模型 embedder = cv2.dnn.readNetFromTorch(embedder_model) print("[INFO] loading dataset....") # 筛选掉张数小於10的人脸 (faces, names) = load_images(args["input"], min_size=10) print(f"[INFO] {len(faces)} images in dataset") # 初始化结果 known_embeddings = [] known_names = [] # 建立我们的人脸embeddings资料库 print("[INFO] serializing embeddings...") start = time.time() for (img, name) in zip(faces, names): rects = detect(img) for rect in rects: (x, y, w, h) = rect["box"] roi = img[y:y + h, x:x + w] faceBlob = cv2.dnn.blobFromImage(roi, 1.0 / 255, (96, 96), (0, 0, 0), swapRB=True, crop=False) embedder.setInput(faceBlob) vec = embedder.forward() known_embeddings.append(vec.flatten()) known_names.append(name) end = time.time() print(f"[INFO] serializing embeddings done, tooks {round(end - start, 3)} seconds") # 使用SVM来"训练"我们的模型可以辨别人脸 le = LabelEncoder() labels = le.fit_transform(known_names) print("[INFO] training model...") recognizer = SVC(C=1.0, kernel="linear", probability=True) recognizer.fit(known_embeddings, labels) # 启动WebCam vs = WebcamVideoStream().start() time.sleep(2.0) fps = FPS().start() while True: frame = vs.read() # 侦测人脸与将人脸转为128-d embeddings rects = detect(frame) for rect in rects: (x, y, w, h) = rect["box"] roi = frame[y:y + h, x:x + w] faceBlob = cv2.dnn.blobFromImage(roi, 1.0 / 255, (96, 96), (0, 0, 0), swapRB=True, crop=False) embedder.setInput(faceBlob) vec = embedder.forward() # 辨识人脸 preds = recognizer.predict_proba(vec)[0] i = np.argmax(preds) proba = preds[i] name = le.classes_[i] text = "{}: {:.2f}%".format(name, proba * 100) _y = y - 10 if y - 10 > 10 else y + 10 cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 0, 255), 2) cv2.putText(frame, text, (x, _y), cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2) fps.update() cv2.imshow("Frame", frame) key = cv2.waitKey(1) & 0xFF if key == ord("q"): break fps.stop() print("[INFO] Approximate FPS: {:.2f}".format(fps.fps())) # 清除用不到的物件 cv2.destroyAllWindows() vs.stop() if __name__ == '__main__': main() - 在terminal中输入
python face_recognition/opencv_realtime.py -i dataset/caltech_faces,等待资料库建立後,辨识看看你自己的脸吧!
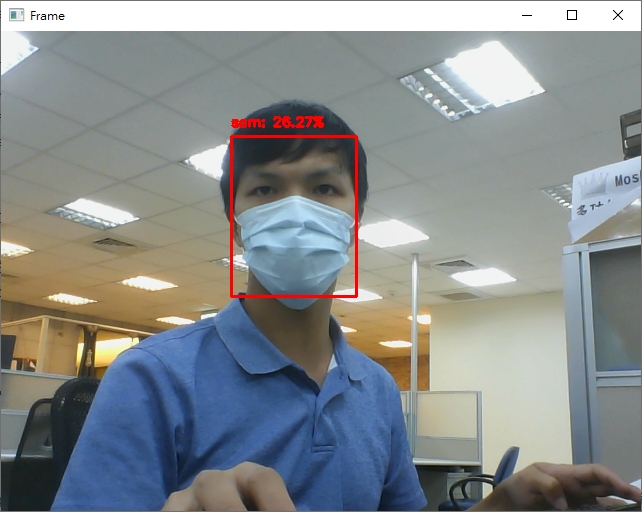
程序码主要处理流程与昨天基本相同:
- 初始化模型
- 把已知的人脸图片ROI转成embeddings资料库
- 训练 / 分类embeddings资料库
- 启动摄影机,逐帧与资料库的人脸比对
- 将最相似的人脸名称取出,显示结果
可以看到虽然辨识率不高 (主要原因为资料库中都是未戴口罩的照片,但实际测试是戴上口罩),不过还是可以成功辨识出是谁。
今天的程序码中是使用与Google FaceNet相同架构的OpenFace预训练模型,
明天我们将谈谈FaceNet这个网路。
-- 今日程序码传送门
<<: [Python 爬虫这样学,一定是大拇指拉!] DAY19 - Python:Requests 基本应用 (2)
>>: Day 19 - 实测盘中订阅 tick 与 bidask 资料是否有先後顺序 (上)
【Day 28】函式(上)
我们在用程序解决问题时,会遇到可能某一块程序码的功能需要重复使用,如果每次要用到就要复制、贴上,其实...
DAY11-JAVA的类别(5)
在建构元中也有所谓公有(public)和私有(private)之分。截至目前为止,所提到的都是公有(...
第二十九天:UI切版 & 元件-视觉效果(载入中、转场、动画)
今天的内容 一、载入中 二、转场 三、动画 四、总结 一、载入中 当我们在处理非同步的需求,中间会有...
[Day8]-元组(tuple)
基本元组 元组的结构跟串列是一样的,但元组可以更安全的保护资料,因为它的资料不会被改变,而且元组的...
成员 19 人:
撰写中 在求发展的道路上,又过了一日...... 这时,成员 19 人。 ...