Day 20 : 动态爬虫-利用webdriver达到自动登入
动态爬虫的做法主要是用在动态网页以及一些需要登入的网页,藉由自动加载指定网页,就可以获得需要加载才能取得的资料。所以今天会来讲讲利用Webdriver自动化加载网页的方法来取得资源,既然要讲加载网页,那就直接讲登入好了,先从最基本的工具-Webdriver开始讲起。
Webdriver
WebDriver操作浏览器的一个介面,使用程序可以自动化操控WebDriver来进行登入帐号、自动输入或是卷动页面等,来达成静态爬虫无法做到的功能,简单来讲它就是个可以被程序控制的浏览器。
所以我们的目标就是写个程序控制WebDriver来开启指定网页,就能自动加载网页来取得我们要的资源。
要下载Webdriver很简单,我们可以先到各个浏览器的Webdriver网站上下载相对应的版本(版本记得要选跟自己浏览器相同的版本),像我是使用Chrome,我就可以到这个网站下载https://chromedriver.chromium.org/
点击Downloads就可以进入选择版本的页面

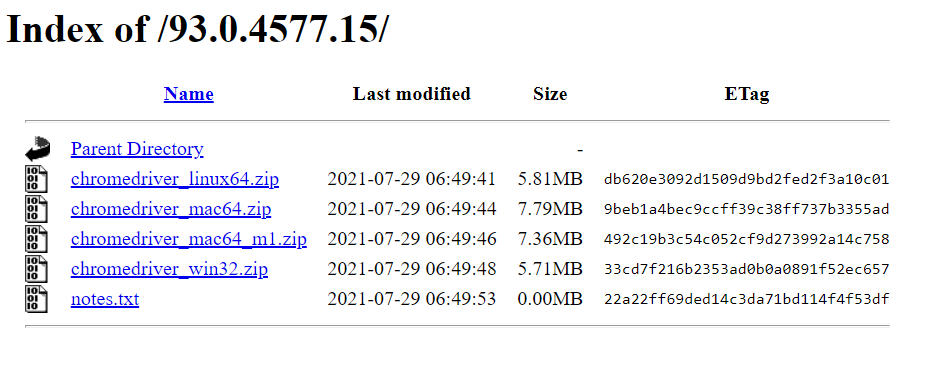
点击相对应版本就能进到这个下载页面,根据自己的作业系统下载解压缩就好了。
Selenium
Selenium是Python针对动态网页爬虫的一个套件,可以藉由控制webdriver来达成爬虫的目的,我们可以先藉由pip指令安装这个套件:
pip install Selenium
再来我们先来测试Webdriver吧,刚刚下载的zip档解压缩後应该会产生一个exe执行档,我们将它放到与程序码同一个资料夹下,并且输入以下程序码:
from selenium import webdriver
driver = webdriver.Chrome("./goolemapSpider/chromedriver.exe")
driver.get('https://www.google.com.tw/?gws_rd=ssl')
webdriver.Chrome用来连结你的webdriver,後面要放路径,然後用get方法去开启指定的网址。
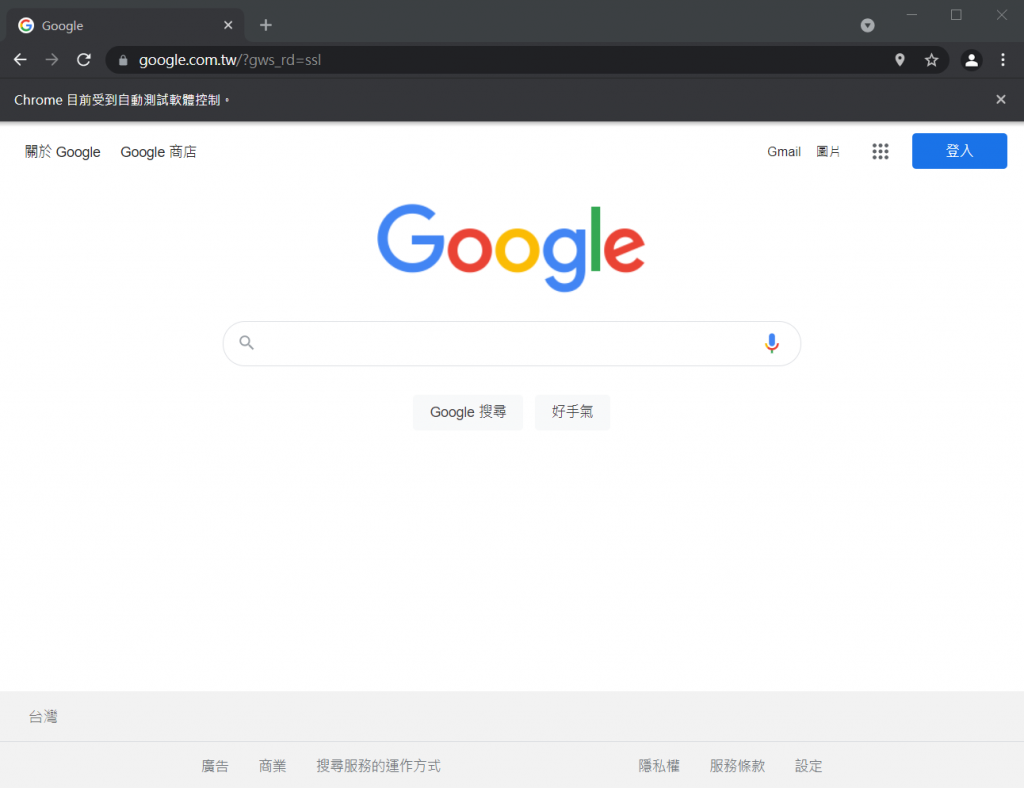
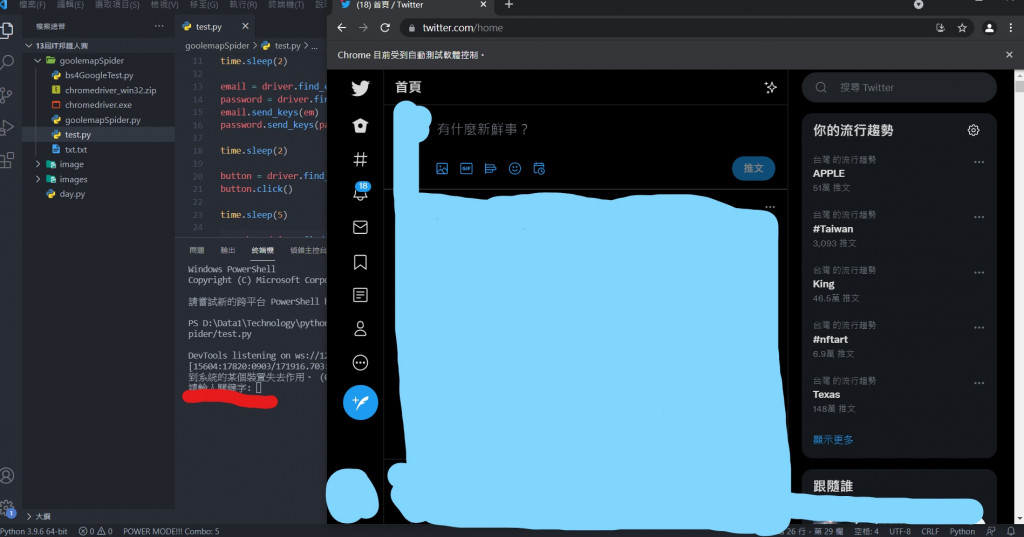
执行後就可以看到跳出了一个新的Chrome视窗,并且上方显示" Chrome目前受到自动测试软件控制。",并且开启了google页面,这样就代表你的Webdriver是正常运作的罗!
这次就来讲解如何自动化登入twitter吧!只要能自动化登twitter,产生静态网站,就能利用bs4爬取资料啦!
Twitter是需要帐号的,所以会用到Webdriver来自动输入帐号登入进行爬取资料。
那这边就从登入帐号开始吧!要使用爬虫登入帐号,我们当然要知道帐号输入的地方在哪,由於网站基本上都是用html以及css呈现给使用者的,所以Selenium提供了下列几种方法,分别使用不同的方法取得html标签位置:
- find_element_by_id : 利用id来选择
- find_element_by_name : 利用name来选择
- find_element_by_xpath : 利用xpath(节点位置)来选择
- find_element_by_link_text : 利用文字来选择
- find_element_by_partial_link_text : 利用部分文字来选择
- find_element_by_tag_name :利用标签元素来选择
- find_element_by_class_name : 利用class来选择
- find_element_by_css_selector : 利用css来选择
可以在Twitter登入画面输入帐号的地方以及输入密码的地方按下右键检查来看输入帐号的地方的html原码:
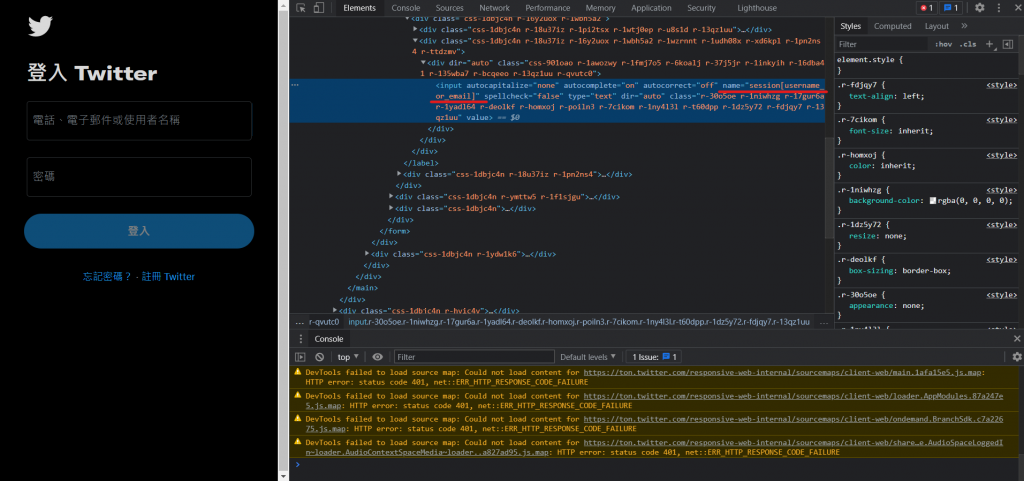
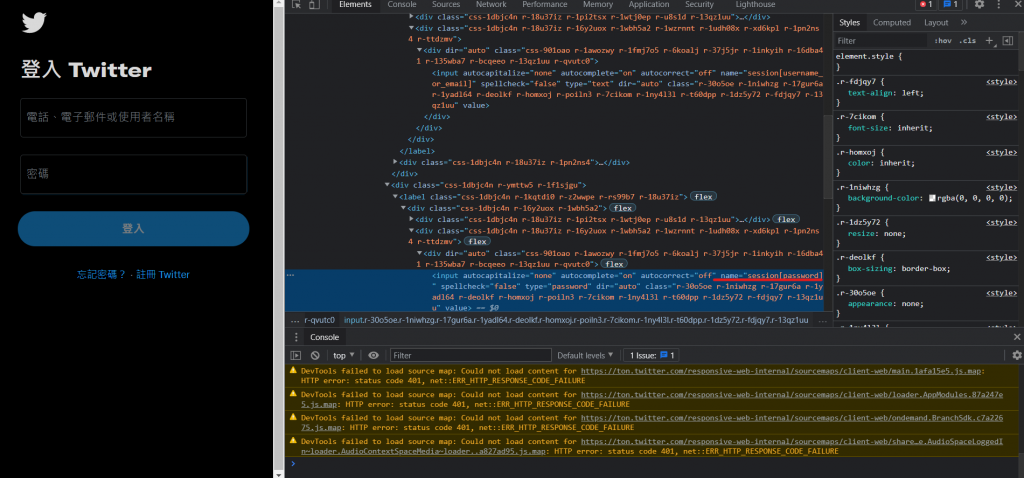
这边用find_element_by_tag_name来选择位置(因为字比较少(X)):
from selenium import webdriver
import time
driver = webdriver.Chrome("./goolemapSpider/chromedriver.exe")
driver.get('https://twitter.com/login')
time.sleep(2)
email = driver.find_element_by_name('session[username_or_email]')
password = driver.find_element_by_name('session[password]')
email.send_keys('[email protected]')
password.send_keys('aaaa')
先把启动网址连结到twitter登入页面,然後分别读取输入帐号以及密码的位置,并给予到一个变数中(email、password),再来会用到send_keys这个功能,它可以将指定的文字输入到这个位置中,所以我们将自己的twitter帐号跟密码打进去,执行程序码:
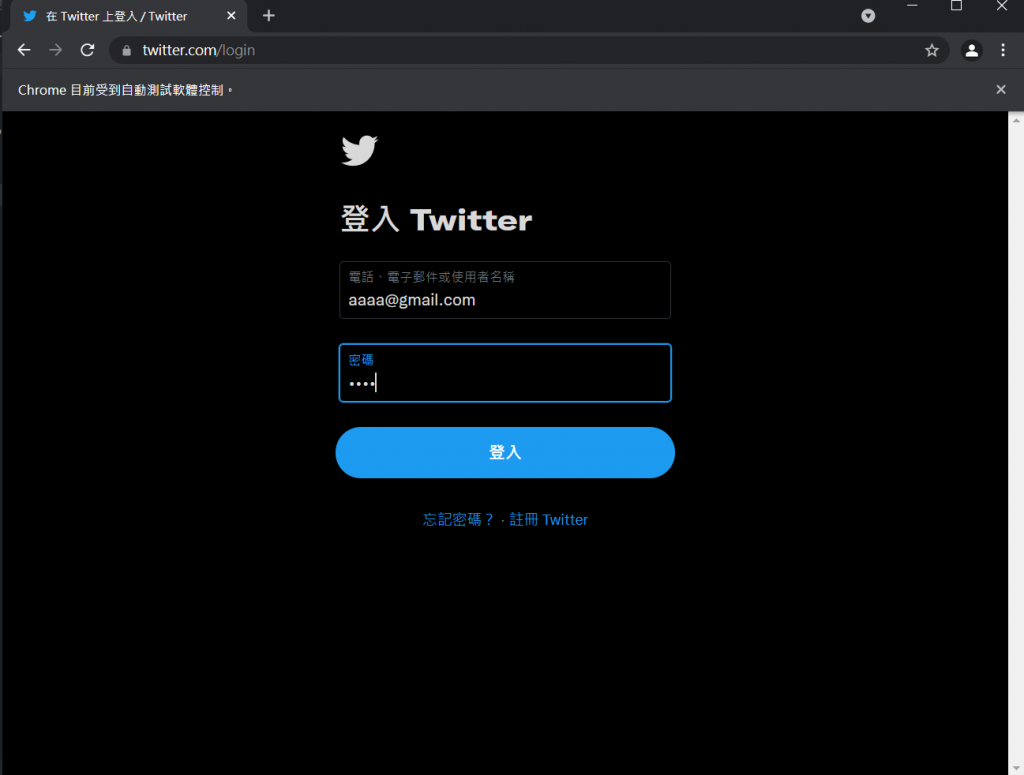
至於增加time.sleep的原因是实际在运作时可能会因为网速或是其他外在因素干扰而导致程序执行过快出问题,所以我会适当的利用time.sleep功能来增加延迟时间。
就会看到程序自动将我们的帐号密码输入进去了!接下来就是点击登入按钮,这时候会用到click(),顾名思义就是点击,找到登入按钮的html原码:
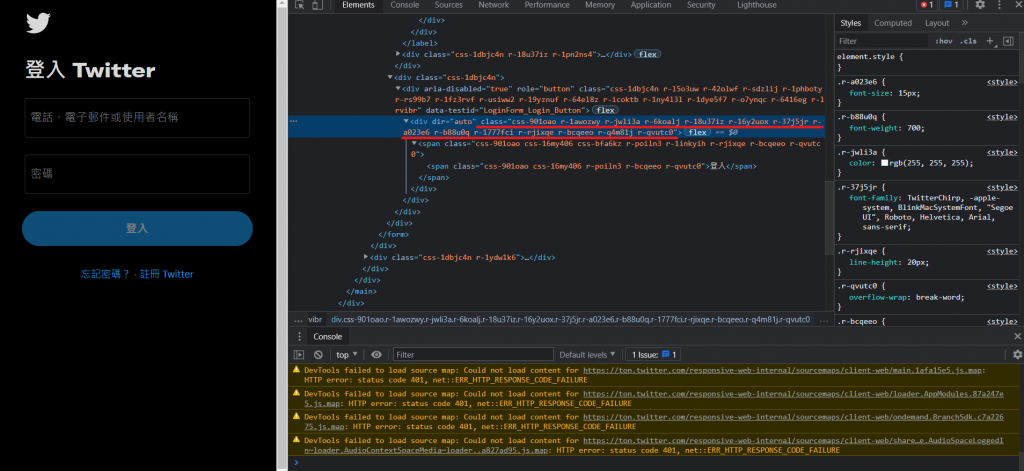
发现没有name标签,那我们就使用class标签。这边有个小细节就是空格,在实际撰写程序码时,空格没有办法被正常判断,解决办法为将空格的位置全部改成点,如下:
time.sleep(2)
button = driver.find_element_by_class_name('css-901oao.r-1awozwy.r-jwli3a.r-6koalj.r-18u37iz.r-16y2uox.r-37j5jr.r-a023e6.r-b88u0q.r-1777fci.r-rjixqe.r-bcqeeo.r-q4m81j.r-qvutc0')
button.click()
再执行一次就会发现已经可以自动登入自己的twitter帐号了!
登入後当然就可以爬到各个想要的资料了,这次我想做的是利用twitter左上角的搜寻功能来搜寻不同的文章资料,所以再来就要针对左上角的输入框,一样检查後会发现输入框的html原码,一样使用class来取的位置,再来我以为按下搜寻键就好了,没想到那个搜寻键根本不能按(((
这时候就要用到键盘输入的功能了,只要能模拟键盘按下enter键就好了,在Selenium中,我们可以先将key这个函式引用进来,再使用send_keys()方法来模拟键盘输入文字,如下:
from selenium.webdriver.common.keys import Keys #这行加在最前面
search = driver.find_element_by_class_name('r-30o5oe.r-1niwhzg.r-17gur6a.r-1yadl64.r-deolkf.r-homxoj.r-poiln3.r-7cikom.r-1ny4l3l.r-xyw6el.r-641cr4.r-1dz5y72.r-fdjqy7.r-13qz1uu')
searchWord = input("请输入关键字")
search.send_keys(searchWord)
search.send_keys(Keys.CONTROL,'\ue007')
time.sleep(4)
利用input来取得在终端机输入的文字,并且输入到搜寻功能的位置,并按下enter键(\ue007),若想知道其他按键要输入甚麽key值的话可以参考下面这个网站:
https://www.selenium.dev/selenium/docs/api/rb/Selenium/WebDriver/Keys.html
再执行一次程序,登入後会叫你输入关键字
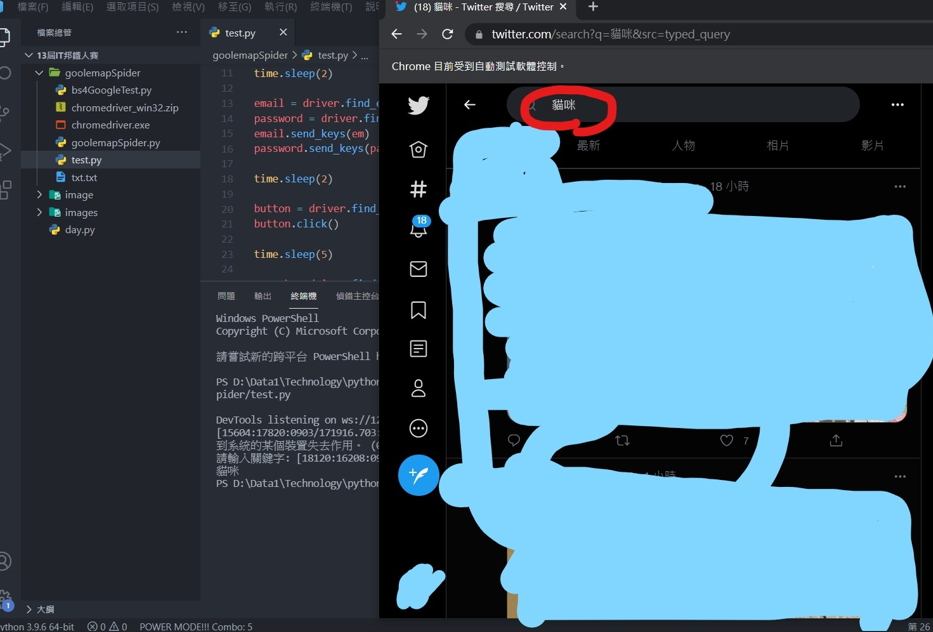
输入文字後webdriver就会将我输入的文字输入到twitter的查询功能。
其实这样网页还不算加载完成,因为在网页没有向下卷动时,其他的文章式不会加载进来的,所以我们需要让webdriver做向下滚动的功能,这边可以使用一个小回圈:
for x in range(1, 3):
chrome.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(3)
中间那行就是滚动页面的函式用法,每滚动一次就休息3秒,这样就可以加载多篇文章。
再来在网页加载完成後,就可以用爬虫了!这边当然可以用Selenium来爬虫,只要这样就好:
content = driver.find_element_by_class_name('css-901oao.r-1fmj7o5.r-37j5jr.r-a023e6.r-16dba41.r-rjixqe.r-bcqeeo.r-bnwqim.r-qvutc0')
print(content.text)
这是每篇文章内容的标签,只要用text就可以将它呈现出来,可是这样的方法只能取得第一篇文章的资料,这边会建议使用上一篇跟上上篇讲的BS4,也就是说利用webdriver以及Selenium动态爬虫技术产生静态网站,再用静态爬虫爬取资料,会是比较好的做法。
至於BS4的部分我就不实作了,上一篇跟上上篇都有完整的范例可以参考。
爬虫的套件讲解就到这边,再来应该会带大家认识pillow套件,帮助做一些简单的照片合成。
>>: JavaScript Day 24. DOM API 节点
[Day 3] 前後端技能这麽多,要选哪个呢?
本来打算一篇写完的,结果居然要分成三篇 XD 前端工具挑选 前端的部分可以搭配框架来建立 比较有名的...
Day 21 - Vue Router基本概念(1)
如同我们前面几天提到的,Vue的核心是用来处理状态、版面、以及元件的逻辑。 但是当整个网站逐渐发展成...
Golang 测试
Golang 测试 转换一下心情,来尝试看看单元测试好了 在golang上要跑测试的话,可以考虑先试...
【Day17】密码破解 ─ 工具实作篇(二)
哈罗~ 昨天介绍了L0phtCrack破密工具, 今天来介绍另一个ncrack的密码破解工具。 nc...
[02] 建立服务器
首先建立一个服务器方便之後 telegram 的 hook 来挂载 这边先从 github 建立一个...