Python 演算法 Day 17 - Neural Network 神经网路
Chap.III 深度学习与模型优化
Part 1:Neural Network 神经网路
即使用程序码模拟生物神经传导系统,教导机器如何学习人类思考模式并做出决策。
1-1. Basic 基本介绍
生物体内的神经网路运作流程:
外部刺激 → 神经元 → 中枢 → 大脑分析 → 下决策
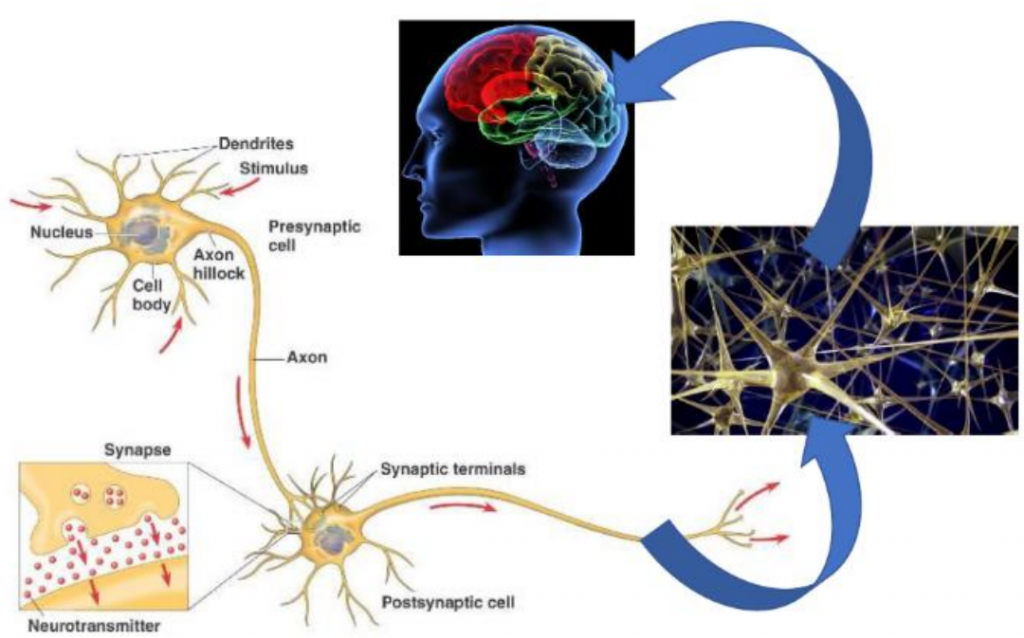
然而,实际上程序码结构如下:
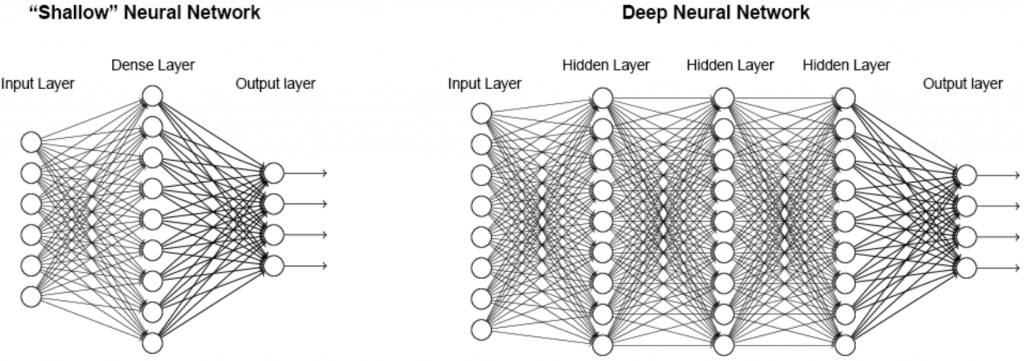
经过层层回归後,最终让机器判断结果。
1-2. Linear regression 线性回归
概括而论,我们训练演算法、建立模型的过程,其实就是在求以下方程序的 w & b
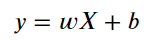
通常会用矩阵计算找出 Weight 权重与 bias 偏差值。

正向与反向传导
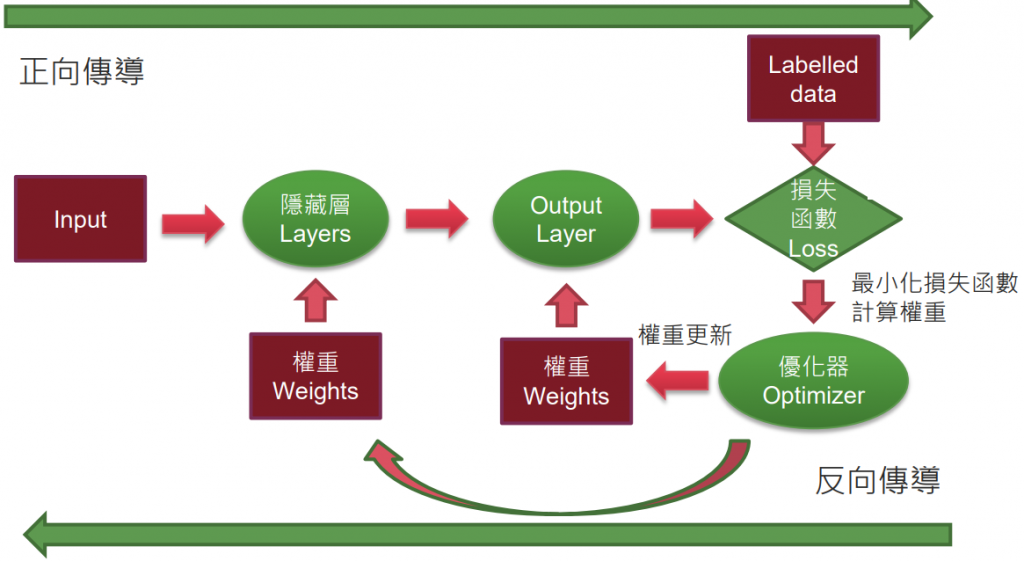
- 正向传导:input 藉由隐藏层求得 output,计算出损失函数(MSE)的过程。
- 反向传导:透过优化器,不断更新权重,最终找到最小的 MSE,的过程。
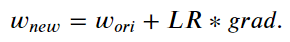
Loss function 损失函数
可以理解成准确度最高,损失函数就越少。故所有模型皆在力求损失函数最小化。
1. 回归的损失函数:Mean-Square-Error (MSE) 均方误差
是一种评估回归线预测准度的指标。
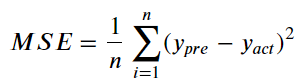
- y_pre:模型训练资料的预测值
- y_act:训练资料的实际值
2. 分类的损失函数:Cross-entropy 交叉熵
即是在Decision Tree 决策树 有提过的 Entropy 及 information gain 概念。
Weight calculate 权重计算
- 最小平方法(证明见补充1.)
- 最大概似法(证明见)
不论哪种,其结果均为:
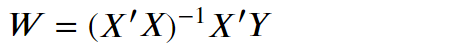
*注意:企业中使用的神经网路常具备多层,须用微分的连锁率实现一次计算所有权重。
1-3. Activation Function 激励函数
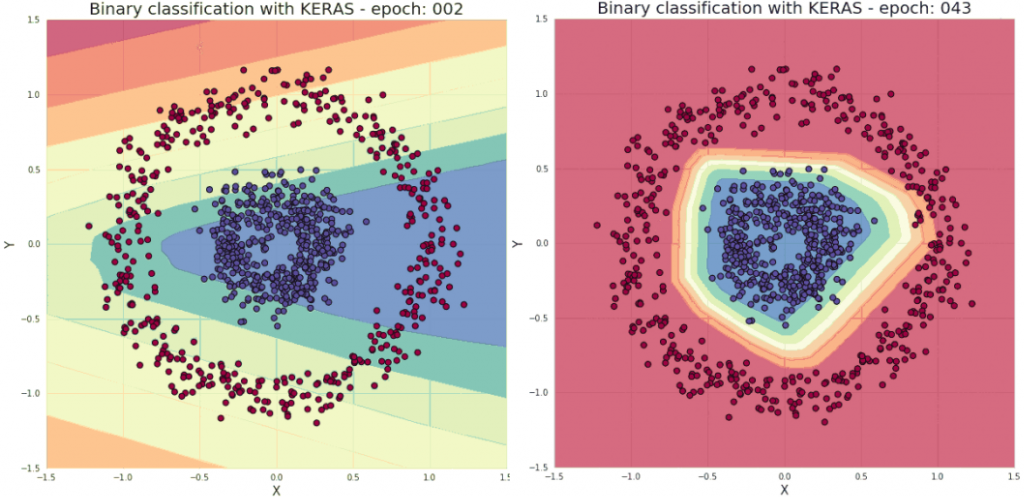
在深度学习中,会遇到许多「非线性」求解的问题。比如说这个漩涡的收敛:
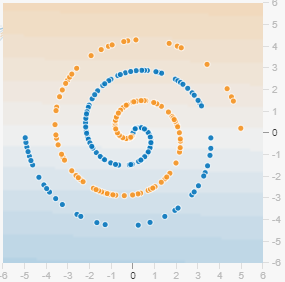
此图明显不是线性收敛能完成的,这时就需要 Activation function 激励函数来转换 output。
它的概念是:
将 x1, x2, x3...的回归结果 y,透过方程序 g(y) 进行转换,进而产出全新的 output z。
我们就称 g(z) 即是 x 的激励函数。
常见的有以下三种:
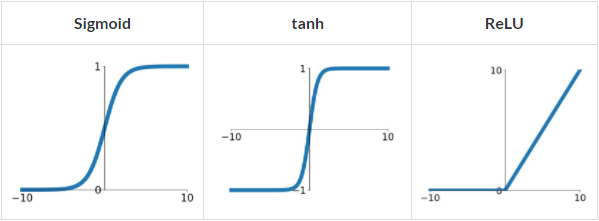
最好理解的就是 relu,即「y 大於 0 保留,y 小於 0 舍弃」,最容易计算,速度最快。
反而是 sigmoid 和 tanh 都会有梯度爆炸和梯度消失问题。
-
没有激励函数的收敛情况,基本等於没收敛:
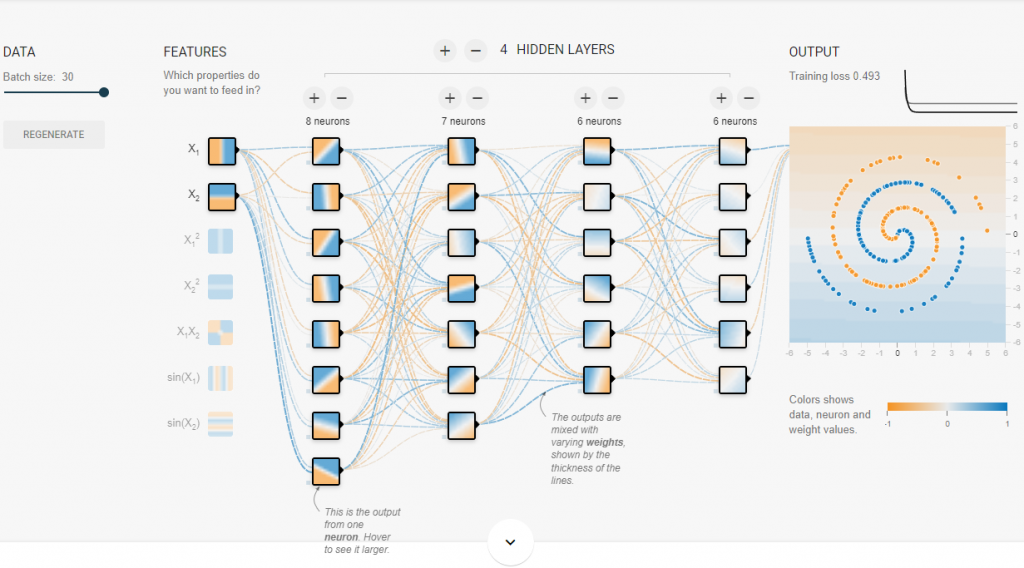
-
使用 relu 激励函数的收敛情况,约1000 Epoch 就收敛的不错:
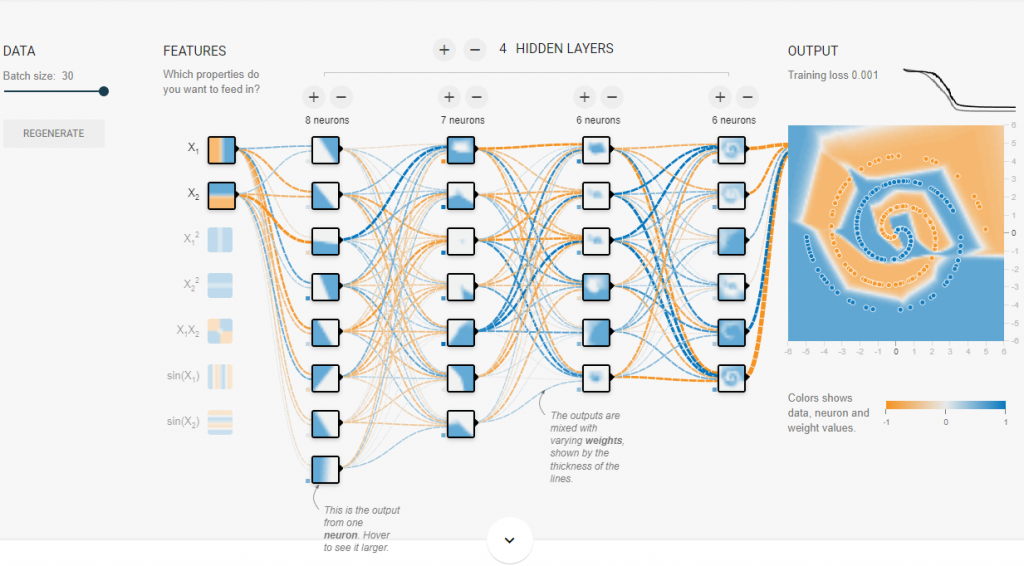
梯度消失 & 梯度爆炸?
在更新模型 w 时要取梯度,当然也会对激励函数做梯度下降。
以 sigmoid 来说,对其微分後,只有在 [0-1] 的范围内有梯度更新,其余都是0。
所以在y > 1 or y < 0的区段是「没有梯度的」,这就是 梯度消失。
梯度消失使後层(靠近输出层) w 更新快,而前层(靠近输入层)由於梯度传递不过去而得不到更新。
导致前层 w 几乎不变,接近於初始化的 w。
在网络很深的时候,学习的速度将会非常慢,甚至无法学习。
反之,若是在 [0-1] 之间梯度会持续被放大,对於一个较深的模型,
在越深的地方就会收到连续的放大倍数,梯度会变很大,此称为梯度爆炸 。
梯度爆炸让梯度从後往前传时不断增大,w 更新过大,使函数在最优点之间不断波动。
当然,仍然有其他的激励函数,
但目前中间层较常用的是 Relu,分类层则较常用 Softmax。
1-4. Optimizer 优化器
根据不同的演算优化器,计算效率也不同,如下图:
(今後会较常使用的优化器叫 Adam)
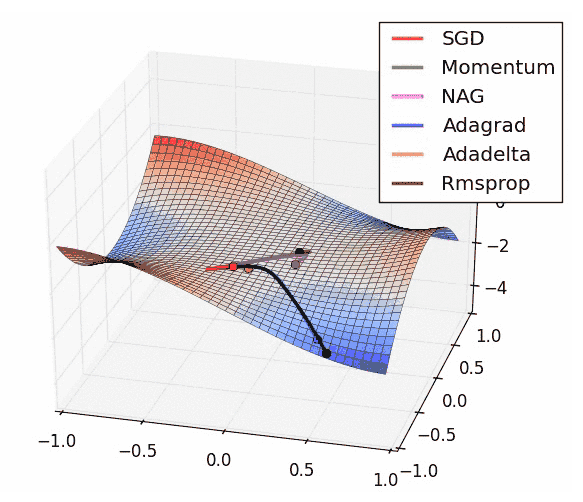
梯度下降也是一种优化方式。
训练过程中,准确率与损失率最终会趋近平缓。
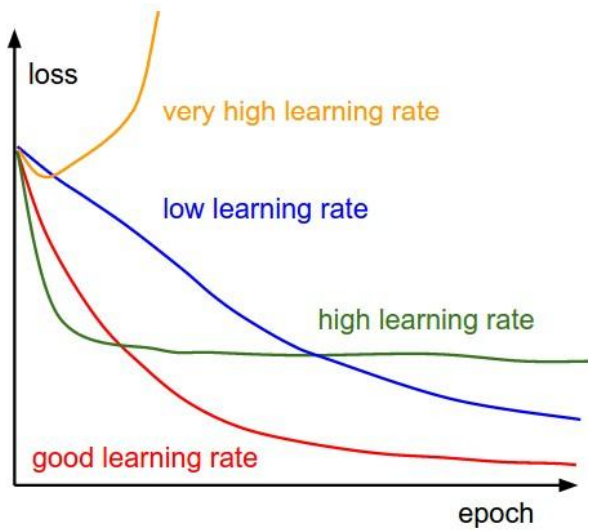
通常来说,找到一个适合的 learning rate 是优化关键。
如下图,太高的 lr 可能导致找不到最佳解,太低的 lr 则让优化效率过低。
1-5. 梯度下降
首先我们必须记住以下公式:
- Error
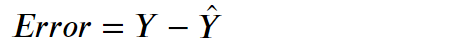
- 梯度公式(证明见补充2.)
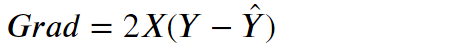
- 权重更新
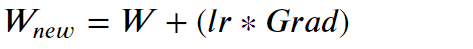
根据梯度下降的过程,又分为三种:
A. Batch Gradient Descent (BGD) 批量梯度下降法
采用「所有」样本,作为一次 epoch。容易走到最小值,但较耗时。
B. Stochastic Gradient Descent (SGD) 随机梯度下降法
采用「一个」样本,作为一次 epoch。过程取决抽样的样本好坏,较省时。
C. Mini-batch Gradient Descent 小批量梯度下降法
采用「多个」样本,作为一次 epoch。为上述两者的平衡。通常也会称为 SGD
Part 2:Deep learning framework 深度学习套件

2-1. theano:
2007 年由蒙特娄大学的蒙特娄学习算法研究所(MILA)开发,但因其本身为学术界开发且使用,在 FB、Google
等企业渐渐主导市场後,已於 2020 年 7 月起宣布不再更新版本。

2-2. Coffe/Coffe2 & PyTorch:
Coffe 是 2013 由加利福尼亚大学柏克莱分校的贾扬清开发,2017 年时 FB 发布 Coffe2,後又於 2018 宣布整
并入 PyTorch。

2-3. Keras & Tensorflow:
Keras 是 2015 由 弗朗索瓦·肖莱开发,於 2017 年由 Google 主导,将 Keras 与 Tensorflow 2.0 功能整
合後,Keras 便於 2.4v 後宣布停止更新与开发。
优势比较:
PyTorch 语法简洁易懂、采用动态计算图、拥有完善的 doc,且语法设计上与 NumPy 是一致的熟悉 Python/NumPy 的深度学习初学者很容易上手。
Keras (Tensorflow 2.0) 则容易撰写、社区支持佳,可轻松搭建深度学习模型。然其艰涩的语法和太底层的接口是其致命伤。
整体来说, PyTorch 适合研究(称霸学术界),而 Tensorflow 适合产品的开发(推出较早被业界泛用)。
而此处将着重於 Tensorflow。
Part 3: Tensorflow
Tensorflow 官方网站 提供一段辨识数字的程序码,
以下我们将逐行分析它的功能:
A. 官方网站版
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10)
model.evaluate(x_test, y_test)
>> loss: 0.0746 - accuracy: 0.9788
Tensorflow 的演算流程仅用了 10 行,且准确率达 97.8%!
B. 逐步讲解版
- Dataset
import tensorflow as tf
mnist = tf.keras.datasets.mnist
-
Clean Data
此处不需要。 -
Split Data
(x_train, y_train),(x_test, y_test) = mnist.load_data()
*可以用矩阵画出资料的内容物(也可用 matplotlib 画,见补充3.):
data_one = x_train[0].copy() # 第一笔训练资料取出
data_one[data_one>0]=1 # 将非 0 数据换成 1,方便辨识
for i in range(28): # 把每一行印出来
print(str(data_one[i]))

隐约看到数字"5",接着对答案:
print(y_train[0])
>> 5
答案的确是"5"
- Feture Engineering
通常为了运算效率,会在此处多一步骤将资料常态化:
x_train_n, x_test_n = x_train / 255.0, x_test / 255.0
- 建立 Model
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
# 分类基本上都会加入一层 'softmax' 的 activation function,让它机率和为 1
tf.keras.layers.Dense(10, activation='softmax')
])
# 选用优化器(此处为 'adam')
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
各神经层作用如下:
5-1. Flatten Layer:扁平化。将宽、高 28*28 个像素的 2-D 图转成 1-D 784 个特徵。
5-2. Dense Layer:全连接层。等同添加一个 output 为 128 条回归线(神经元)的层。
5-3. Dropout Layer:训练周期中,随机拿掉部分神经元(此处为 20%),减少对权重依赖,防止过拟合。(示意图见补充4.)
5-4. Dense Layer:全连接层。等同添加一个 output 为 10 个神经元(对应数字0~9)的层。
经 softmax 将其转成 0~9 的机率,以最大机率者为预测值。
- Training Model
若将测试资料再拆分20%作为训练过程中的验证:
his = model.fit(x_train_n, y_train, epochs=5, validation_split=0.2)
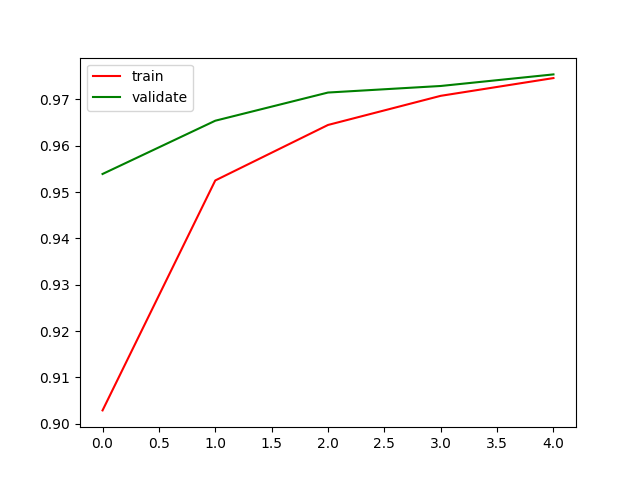
准确率与损失函数的图画出,两条线应该会逐渐靠拢:
# 准确率
plt.plot(his.history['accuracy'], 'r', label='train')
plt.plot(his.history['val_accuracy'], 'c', label='validate')
plt.show()
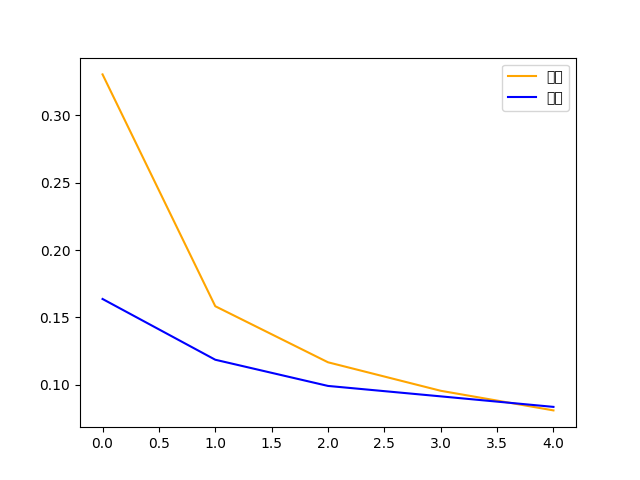
# 损失函数
plt.plot(his.history['loss'], 'm', label='train')
plt.plot(his.history['val_loss'], 'b', label='validate')
plt.show()
- Score Model
score = model.evaluate(x_test, y_test)
print(score)
>> loss: 0.0746 - accuracy: 0.9788
- Test Model
import numpy as np
pre = np.argmax(model.predict(x_test_n), axis=1) # 预测资料,并且每一列取最大值(最有可能的数字)
print("Predict:", pre[0:20])
>> Predict: [7 2 1 0 4 1 4 9 6 9 0 6 9 0 1 5 9 7 3 4]
print("Actual:", y_test[0:20])
>> Actual: [7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5 9 7 3 4]
此时发现第八笔资料有错误,将其预测值机率调出:
pre_prob = model.predict(x_test_n)
np.around(pre_prob[8], 1)
>> array([0. , 0. , 0. , 0. , 0.2, 0.1, 0.7, 0. , 0. , 0. ], dtype=float32)
发现预测机率最高的确是数字"6",只好调出真实图片:
X_8 = x_test_n[8,:,:]
plt.imshow(X_8.reshape(28,28), cmap='gray')
plt.axis('off')
plt.show()
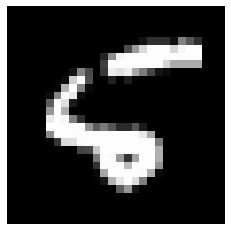
......确实长得很丑XD
- Save Model
最後当然是把这个模型存起来,下次调用时就不用重新建模。
model.save('Model_NumberReg.h5')
- Reload & Testing Model
我们用小画家随意地画出一个数字:

接着叫出训练好的模型,对它做预测:
model = tf.keras.models.load_model('Model_NumberReg.h5')
# 输入图档
uploaded = './myDigits/9.png'
image1 = io.imread(uploaded, as_gray=True)
# 压缩图档画素
image_resize = resize(image1, (28, 28), anti_aliasing=True)
X1 = image_resize.reshape(1, 28, 28)
# 反转颜色(颜色 0 为白,RGB (0, 0, 0) 为黑)
X1 = np.abs(1-X1)
# 使用 Model 预测
pre = np.argmax(model.predict(X1))
print(pre)
>> 9
这样就完成了 Tensorflow 的机器学习初体验啦~
*後续思考:
1. 最後一层参数总数算法?(GPT-3 已经高达 1750 亿个参数!)
2. Dense 的参数?
3. Activate function 要选用哪个?
4. Ragularization 的作用?
5. Dropout 是甚麽? 该摆放在哪一层? 比例又该如何选择?
6. 损失函数有哪些? 个别有甚麽影响?
.
.
.
.
.
*补充1.:最小平方法
为了求得 SSE(没有除以 n 项的 MSE)最小化,我们首先要定义 Error:
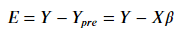
矩阵内容如下:
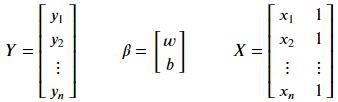
因为要让 E 为正值,将其平方:
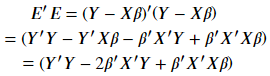
(此处 Y'X\beta 与 \beta'X'Y 因为皆为常数且值相等,故简化成一项次)
为了求得 SSE 最小,将其对 \beta' 微分求导,且结果为 0:
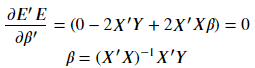
*补充2.:梯度公式
SSE 的定义如下:
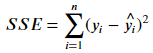
其中 y_i 表示预测值;\hat{y_i} 表示平均值,而因为 y_i = (wx_i + b)
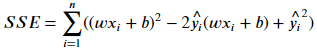
而梯度的定义为下:
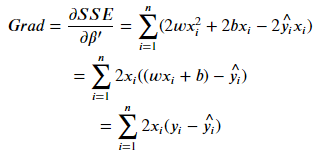
*补充3.:用 matplotlib 画出资料的内容物
#
import matplotlib.pyplot as plt
data_one = x_train[0]
plt.imshow(data_one.reshape(28, 28), cmap='gray')
plt.axis('off')
plt.show()

*补充4.:Dropout Layer 示意图
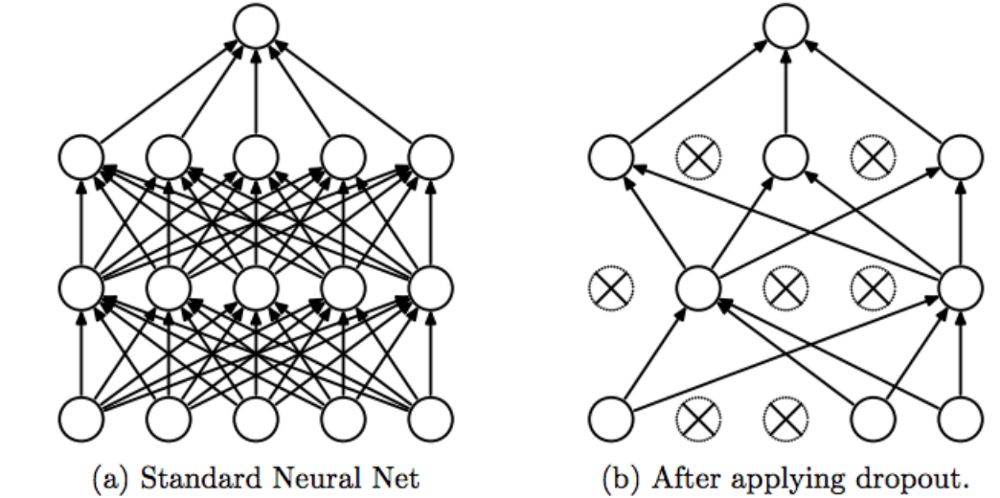
.
.
.
.
.
Homework:
请使用网站的资料(日文辨识),作为机器学习的对象。
Powershell 远程连接
使用过 Linux 的都知道,Linux 的 shell 不但可以本地运行,也可以通过远程的方式连接...
流程与制度 - 打造一个「人」的系统
谈过故事、人、与文化,我们要到最後的一个元素 — 流程与制度。最後来谈流程与制度,并不是因为他们不...
D6 第三周 (回忆篇)
这礼拜进度比较快写到 week4 的作业。看了一下 fetch API 的东西,$.ajax(), ...
Day 25-制作购物车之设计购物车画面
设计的部分就不多做分析,主要呈现实作成果。 因为太长了,所以分一点过来。 以下内容有参考教学影片,底...
Day31. 单例模式
本文同步更新於blog Singleton Pattern 确保一个类只有一个实例,并提供一个全局...