【Day 18】 实作 - 透过 AWS 服务 Glue Crawler 自动建立 VPC Log 资料表
大家午安 ~
昨天我们已经启用 VPC Flow Log 并且存放到 S3,今天我们会设定 AWS Glue Crawler 自动建立 VPC Log 资料表,以供 Athena 查询
注:如果想手动建立 VPC Log 资料表,可以参考[1]
那我们就开始吧 GO GO
步骤一、搜寻 Glue
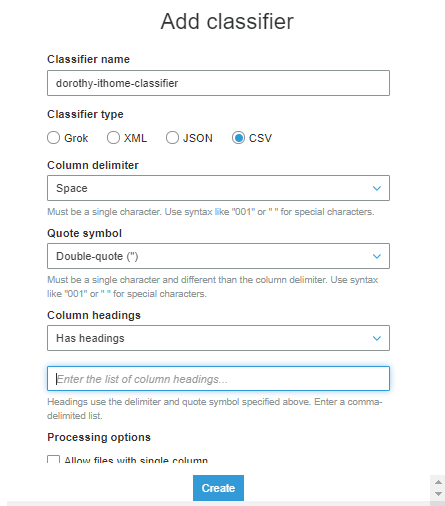
步骤二、点选左侧选单的 Classifiers 并按 Add Classifier
昨天观察 VPC Log 的资料,你会发现『每个栏位都是以空格去间隔』,但 Glue Crawler 预设是依据逗号作栏位间隔,故我们需要先增加 Classifiers 来自定义『欲抓取的资料』分隔符号、档案类型、栏位名称等设定
Classifier name:自行定义名称即可
Classifier type:CSV
Column delimiter:Space
Quote symbol:Doublue-quote(“)
Column headings:因我们观察原始资料是有表格栏位名称的,故选择 has headings
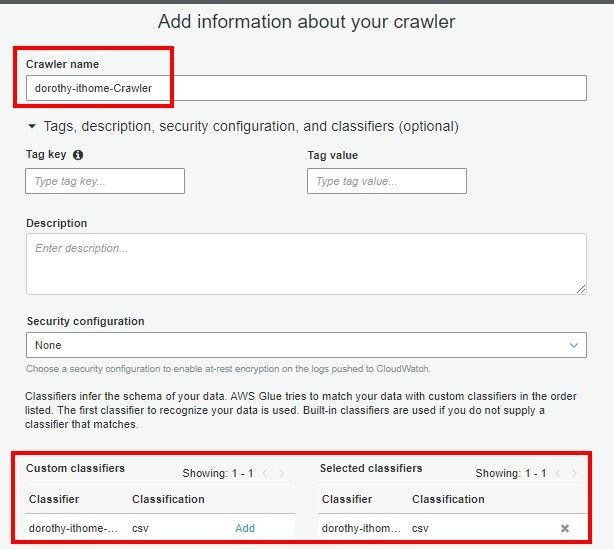
步骤三、点选左侧选单的 Crawler 并按 Add Crawler

步骤四、输入 Crawler 名称,以及 Add 刚刚创建的 Classifiers 後按下一步
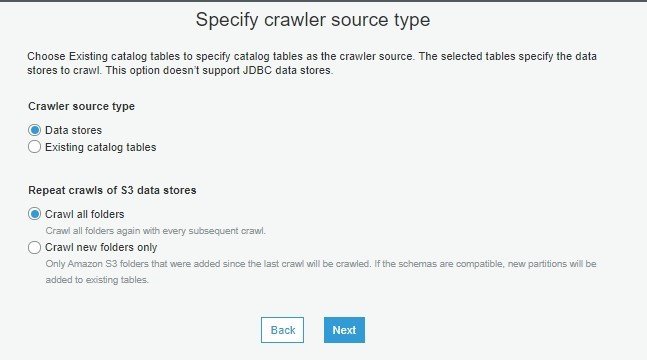
步骤五、设定来源资料类型以及每次爬的方式
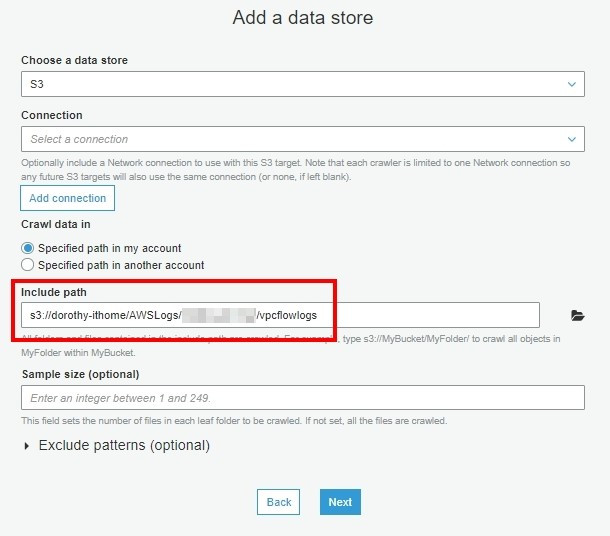
步骤六、选取 S3 并指定我们 VPC Log 资料夹
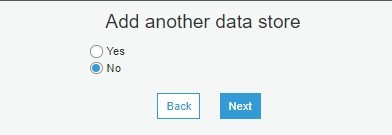
步骤七、是否要增加其他来源资料,这边我们选 NO
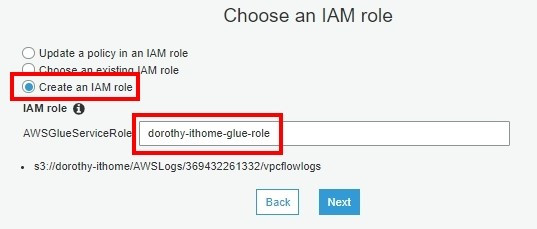
步骤八、创建一个新的 IAM Role
注意:若要使用已存在的 role,那要确认此 role 是否有适当的权限喔~
步骤九、设定排程
我们这边选择手动执行( Run on demand )即可
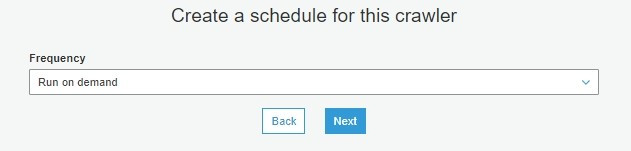
步骤十、选择资料库以及资料表的前缀词
(可以不增加前缀词,如果有重复名称,系统会自动加序号,避免资料表名称重复)
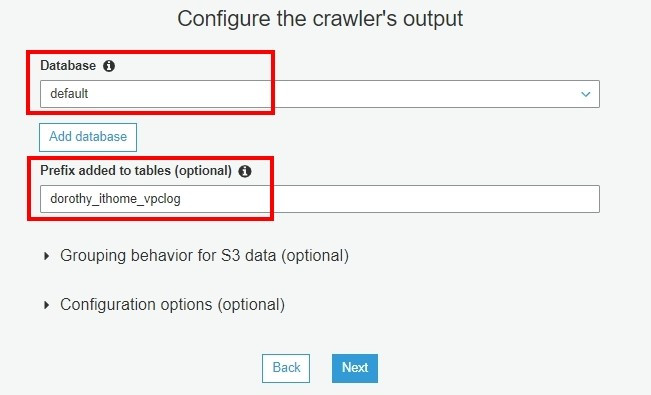
步骤十一、选择此 Crawlers 并执行 Run crawler
执行完後就可以看到有新增一个 Table
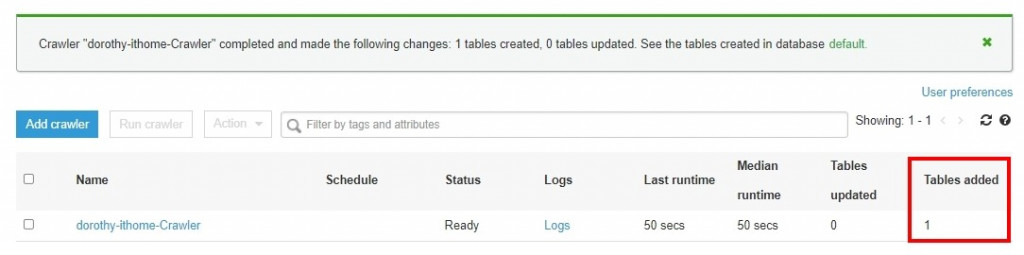
接着我们至左侧选单的 Tables,可以看到资料表的栏位以及对应格式,其中有看到几个栏位名称为 partition_x,这是什麽呢?
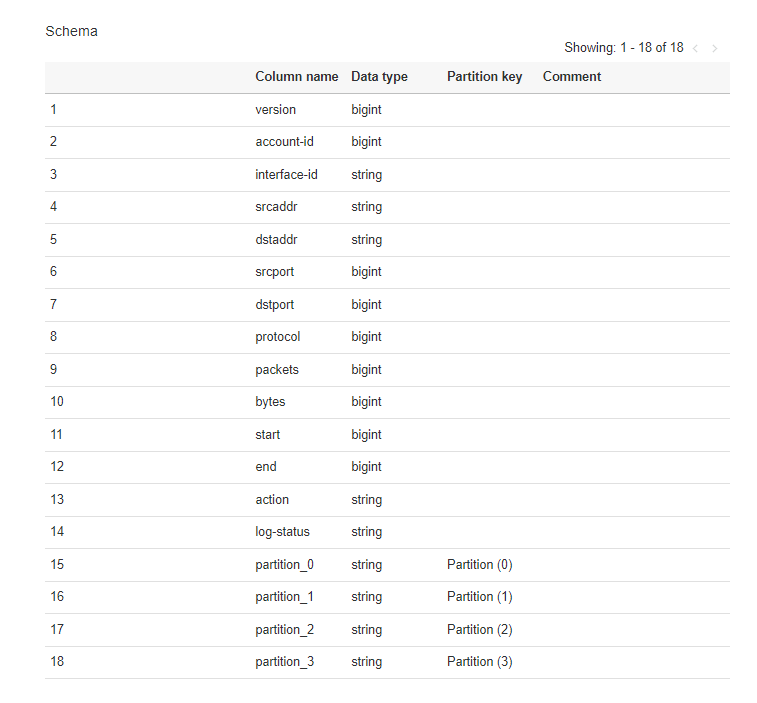
我们点击 View partitions 可以看到目前 partition 的结构,发现 Glue 自动帮我们将每一层资料夹切分成 partition

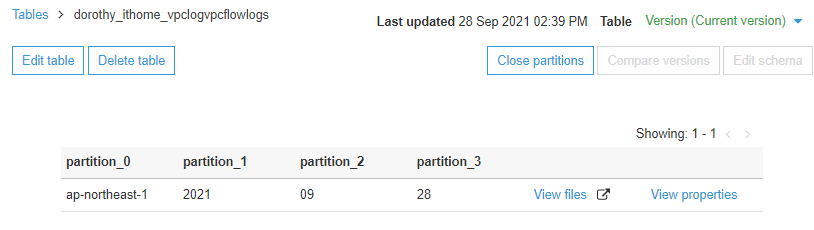
适当的 partition 有助於大量资料查询,举例来说:
假设今天我只要搜寻 09 月的资料,如果没有 partition 的情形下要捞出 09 月资料,Athena 会搜寻指定路径下每个资料夹,但如果有 partition 并且於 SQL 语法增加 where 筛选,这样 Athena 仅会搜寻指定的 partition 下资料,有 Partition 可以大大加快查询速度且费用也会大大减少
除了建立良好的 Partition 外,将资料转换成 Parquet 这种储存格式,也是加快查询速度很好的方式喔! 先前我们有教学用 Lambda 将 json 转换成 parquet,我们也可以透过 AWS Glue job 来完成这个转换并且依据个人需求切出你需要的 Partition 结构~
明天我们就会来实作 – 如何用 AWS Glue job 进行 Parquet 格式转换
明天见罗 : D ~
如果有任何指点与建议,也欢迎留言交流,一起漫步在 Data on AWS 中。
[1] 手动为 VPC 日志建立资料表
https://docs.aws.amazon.com/zh_tw/athena/latest/ug/vpc-flow-logs.html
Day 11 | UnityAR世界建立 - ARFoundation/ARCore介绍
上一篇文章介绍了Unity AR(Android)的建置环境,本篇文章会简单介绍开发此款手游的主要A...
[Day5] Vite 出小蜜蜂~ Component 元件!
Day5 写程序写到一定的阶段後,会开始发现,其实做出想要的功能并不困难。 真正难的,其实是如何写出...
Day 25 大数据下的三兄弟-从Kinesis到EMR与Redshift
承接昨天提到的Kinesis巨量资料传递,我们今天继续延伸巨量资料传递後的处理与储存。 1. Kin...
[Day 33] 再访碰撞侦测与解析(五) - Debug Ray vs Rect (二)
今日目标 继续Debug Ray vs Rect的部分 MISSION FAILED! QAQ 今天...
曝露系数(Exposure factor)
-简单的定量风险分析 曝露系数 (EF) 曝露系数 (EF) 是在实现特定威胁时对特定资产的主观、...