[神经机器翻译理论与实作] 你只需要专注力(II): 建立更专注的seq2seq模型
前言
注意力机制让预测目标单词之前比较其与所有来源单词(在翻译任务中精确地来说是词向量)之间的语意关联性来提高翻译的准确度。今天就让我们来快速回顾注意力机制的原理,以及用 Keras API 建立带有 attention layer 的 LSTM seq2seq 模型。
回顾注意力机制
以下是注意力机制的基本原理:
输入值 query 会根据「记忆」计算出其与各个来源 value 之间根据其对应的 key 进行比对,得到 query 与各个 key 的相关性之後,汇整进而输入 attention layer 得到输出值。讲得有些饶口,以翻译器的神经网络来说明, query 就是当下时间点解码器的 hidden state (在 LSTM 架构中不含 cell state ),而 values 即是所有时间点的内部状态
(依序代表各个来源单词
) ,透过比较计算各别的出关联性分数
,透过 attention function 将每个
与相对应的权重
相加起来(加权平均),得到输出值 context vector
。
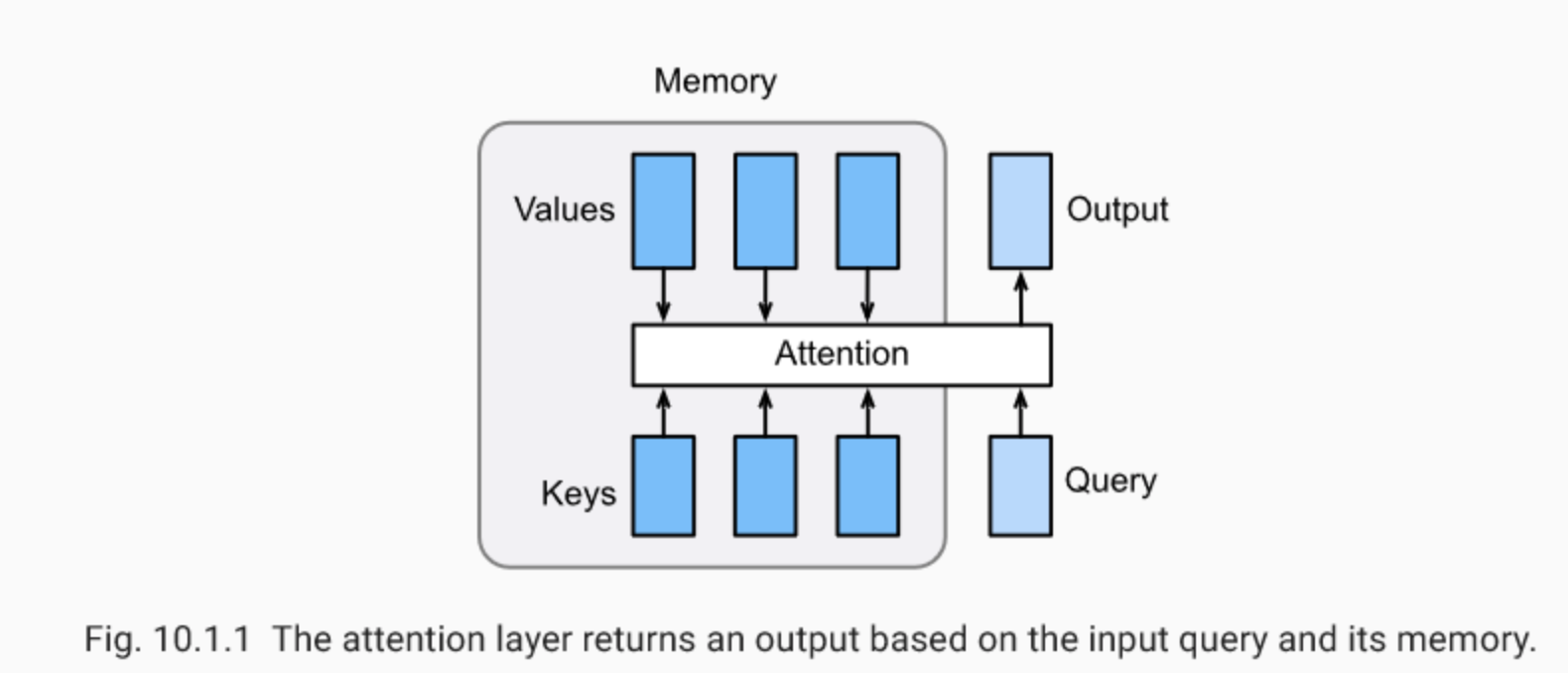
图片来源:Programming VIP
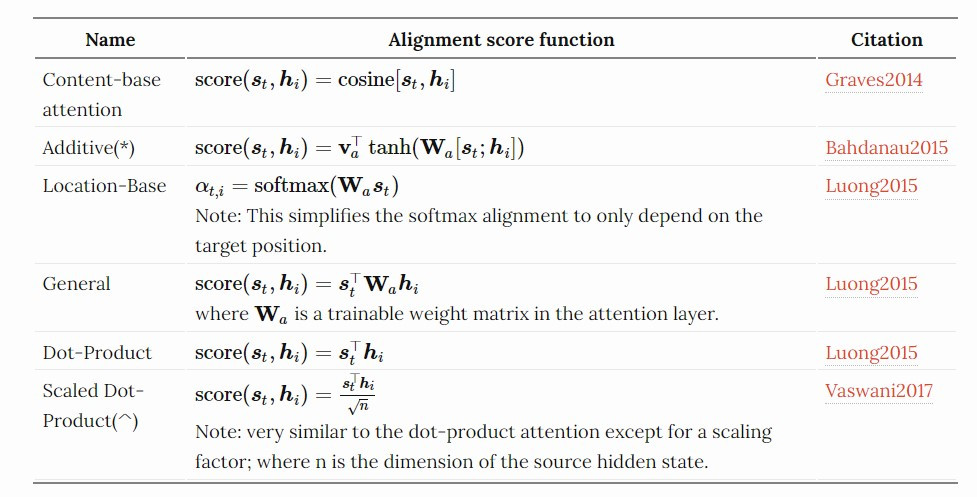
常见的关联性分数(又称 attention function )计算方式:
图片来源:lilianweng.github.io
用Keras建立注意力层神经元(上篇)
在导入注意力机制串接 encoder 与 decoder 之前,我们先建立双层的 LSTM seq2seq :
import tensorflow as tf
from tensorflow.keras import Sequential, Input
from tensorflow.keras.layers import Dense, LSTM, Embedding
from tensorflow.keras.models import Model
### preparing hyperparameters
## source language- Eng
src_wordEmbed_dim = 18 # one-hot encoding dim is used here, while generally is dimensionality of word embedding
src_max_seq_length = 4 # max length of a sentence
## target language- 100 (for example)
tgt_wordEmbed_dim = 27 # one-hot encoding dim is used here, while generally is dimensionality of word embedding
tgt_max_seq_length = 12 # max length of a sentence
# dimensionality of context vector
latent_dim = 256
# Building a 2-layer LSTM encoder
enc_layer_1 = LSTM(latent_dim, return_sequences = True, return_state = True, name = "1st_layer_enc_LSTM")
enc_layer_2 = LSTM(latent_dim, return_sequences = False, return_state = True, name = "2nd_layer_enc_LSTM")
enc_inputs = Input(shape = (src_max_seq_length, src_wordEmbed_dim))
enc_outputs_1, enc_h1, enc_c1 = enc_layer_1(enc_inputs)
enc_outputs_2, enc_h2, enc_c2 = enc_layer_2(enc_outputs_1)
enc_states = [enc_h1, enc_c1, enc_h2, enc_h2]
# Building a 2-layer LSTM decoder
dec_layer_1 = LSTM(latent_dim, return_sequences = True, return_state = True, name = "1st_layer_dec_LSTM")
dec_layer_2 = LSTM(latent_dim, return_sequences = True, return_state = True, name = "2nd_layer_dec_LSTM")
dec_dense = Dense(tgt_wordEmbed_dim, activation = "softmax")
dec_inputs = Input(shape = (tgt_max_seq_length, tgt_wordEmbed_dim))
dec_outputs_1, dec_h1, dec_c1 = dec_layer_1(dec_inputs, initial_state = [enc_h1, enc_c1])
dec_outputs_2, dec_h2, dec_c2 = dec_layer_2(dec_outputs_1, initial_state = [enc_h2, enc_c2])
dec_outputs_final = dec_dense(dec_outputs_2)
# Integrate seq2seq model
seq2seq_2_layers = Model([enc_inputs, dec_inputs], dec_outputs_2, name = "seq2seq_2_layers")
seq2seq_2_layers.summary()
plot_model(seq2seq_2_layers, to_file = "output/2-layer_seq2seq.png", dpi = 100, show_shapes = True, show_layer_names = True)
我们将刚建好的模型画出来:
from tensorflow.keras.utils import plot_model
plot_model(seq2seq_2_layers, to_file = "output/2-layer_seq2seq.png", dpi = 100, show_shapes = True, show_layer_names = True)
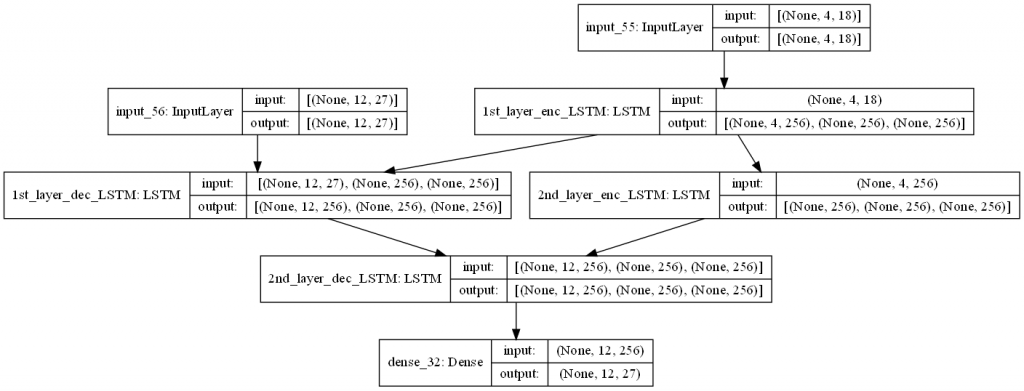
明天将会将 attention mechanism 加入以上的双层 LSTM seq2seq 模型当中。
结语
本来设定今天将要完成附带注意力机制的 Seq2Seq 模型建构,并比较单词之间的关联性,然而由於时间关系,必须先停在这里。明天接着完成!晚安!

阅读更多
<<: [第十六只羊] 迷雾森林舞会X 热线你和我 hotwire 导入
>>: DAY 18:Singleton Pattern,致独一无二的你
Day 11 ( 中级 ) 视差效果
视差效果 教学原文参考:视差效果 这篇文章会介绍,如何在 Scratch 3 里建立五个角色,透过重...
【Vue】串 API 前置作业|Axios 是什麽?
Axios 是一个 Promise based 的HTTP 请求工具。 那 Promise base...
【I Love Vue 】 Day 29 爱荷华博弈任务(十) - Demo
话不多说,赶紧把我们的作品Demo 给我们 铁人学院的业主吧!! Demo 进入主画面 我们可以透过...
更新Android Studio Arctic Fox | 2020.3.1与android X 与相关开发环境升级
缘由: 因新版的Android Studio一直弹出提示要更新,Android Gradle Plu...
[Day28] Esp32 + IFTTT + Google Sheet - (程序码讲解)
1.前言 OK,今天要来说说Code的部分,上一篇我们把资料储存在Google Sheet中,那今天...