[Day 19] 自动化机器学习 - AutoML
AutoML
今日学习目标
- 了解何谓 AutoML
- 超参数调参方法
- Grid Search
- Random Search
- Bayesian Optimization
AutoML 的动机
大家还记得在 [Day 5] 机器学习大补帖 中有提到完整的机器学习流程大致分成八个步骤。然而模型的训练与超参数调整仅扮演其中的一环,选择一个好的模型是件重要的事情。想必大家在训练模型时一定会遇到一个棘手的问题,就是该如何正确选择模型以及调整超参数?随着越来越多的演算法不断地被开发出来,要从茫茫大海中挑选一个合适的模型是件耗时的事。因此自动化机器学习 (Automated Machine Learning ,AutoML) 可以帮助我们在有限的时间内找出一个满意的模型。在近年来有许多人开始研究这类的问题,笔者汇整了几个 Python 热门的 AutoML 开源套件:
- AutoGluon
- Auto-sklearn
- FLAML
- H2O AutoML
- LightAutoML
- Pycaret
- MLJAR
- TPOT
- MLBox
- Auto-PyTorch
- AutoKeras
- talos
AutoML 扮演的角色
自动化机器学习提供了一系列的方法和自动化的学习流程,以提高机器学习的效率并加速机器学习的研究。透过 AutoML 集结专家的先验知识,大幅降低了机器学习建模的困难度。虽然领域专家与 AI 工程师必然扮演重要的角色,但是近年来 No Code 无程序码开发平台形成一股潮流。AI 再也不是需要资讯背景的人才能做的事,目的是让大家不用透过写程序也能快速地进行资料探索与建立预测模型。然而近年来许多企业开发了各种需求的 AutoML 平台,如雨後春雨般的出现:
- Google: Cloud AutoML
- Microsoft: Azure Machine Learning
- Amazon: SageMaker Autopilot
- Landing AI: LandingLens
- Chimes AI: tukey
AutoML 能帮助多少事情
典型的机器学习流程是一个迭代的循环周期,从定义问题、资料收集与处理、模型设计到最终模型部署,每个步骤极为重要且缺一不可。此外一个好的机器学习的专案需要执行 MLOps 的流程,才能够让模型在实际应用场景越来越好真实地解决问题。MLOps 指的是从 AI 模型训练到部署上线的一套完整机器学习工作流程,近年来这一名词非常热门,它其实就是 ML (机器学习) 与 DevOps (开发与维运) 的结合。如下图所示从训练模型到正式部署中间还有许多事情要处理,而模型上线後还是要持续监控并收集新的场域资料。最後将资料收集到一定程度,又回到周期的第一步重新训练新模型。至於模型该如何重新训练并保持资料的隐私性就是另一门议题。这时候我们就能采用一个技术叫做 Federated Learning (联合学习) 想办法处理这类的事情。
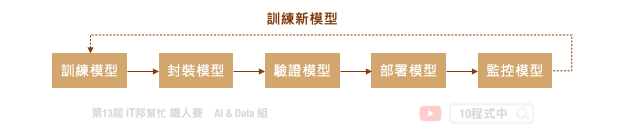
但是我们可以发现训练一个机器学习模型,在 MLOps 的周期中仅扮演小小的一块角色。下图是一个训练机器学习模型的基本流程,中间橘色的部分就是 AutoML 可以帮助我们的事。从资料前处理、训练模型到评估模型需要不断地的进行试验,并且尝试各种不同的模型演算法与模型超参数。除此之外还有资料前处理与特徵工程,都可以透过 AutoML 自动化的训练找到一个满意的模型。
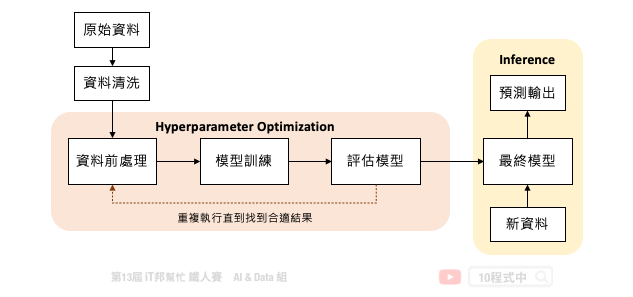
超参数调参方法
机器学习自动化的困难点在於资料清洗与特徵工程技巧。一个好的特徵表达可以让模型快速地抓到关键因子,并让模型预测能力提升。庆幸的是模型挑选和超参数调整已经有比较成熟的方法可以协助我们有效的搜寻。
- Grid Search 网格搜索/穷举搜索
- Random Search 随机搜索
- Bayesian Optimization 贝叶斯优化
Grid Search
Grid Search (网格搜索) 又称穷举搜索。它的搜索方式是在所有可能的参数中,透过排列组合尝试每一种可能性。并将表现最好的参数最为最终的超参数搜寻结果。他的缺点就是当有许多超参数要寻找时,他的排列组合就会变得非常多,导致搜索的时间变长花费的资源也变大。因此这种暴力式的搜索方法适合在小的资料集上被采用。然而在 Sklearn 套件中有提供 GridSearchCV 方法,使用者可以自己设定参数列表,并透过所有可能的参数组合一个一个尝试找到最合适的参数。
from sklearn import svm, datasets
from sklearn.model_selection import GridSearchCV
# 载入鸢尾花朵资料集
iris = datasets.load_iris()
# 设定想要的搜索参数并给予候选值
parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
# 建立 SVC 分类器
svc = svm.SVC()
# 网格搜索所有可能的组合(2*2)共四种
clf = GridSearchCV(svc, parameters)
# 拟合数据并回传最佳模型
clf.fit(iris.data, iris.target)
搜索结束後也能够过 cv_results_ 查看所有组合的超参数所对应的训练结果。
clf.cv_results_
Random Search
Random Search (随机搜索) 按照字面上的意思就是在所有可能的候选参数中随机挑选一个数值并尝试。如果需要调的参数较多的时候,使用随机搜索可以降低搜索时间,同时又能确保一定的模型准确性。在 Sklearn 套件中也有提供 RandomizedSearchCV 方法可以呼叫,与网格搜索的差别在於使用者可以将欲搜寻的超参数设定一个期望的范围。该方法会在此范围中随机抽一个数值并进行模型训练并验证模型。并找出所有随机组合中表现最好的一组超参数。
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform
# 载入鸢尾花朵资料集
iris = load_iris()
# 建立逻辑回归模型
logistic = LogisticRegression(solver='saga', tol=1e-2, max_iter=200, random_state=0)
# 设定欲搜寻的超参数并给予一个期望的范围
distributions = dict(C=uniform(loc=0, scale=4),
penalty=['l2', 'l1'])
# 随机搜索预设 n_iter=10
clf = RandomizedSearchCV(logistic, distributions, random_state=0, n_iter=10)
# 拟合数据并回传最佳模型
search = clf.fit(iris.data, iris.target)
search.best_params_
Bayesian Optimization
Bayesian Optimization (贝叶斯优化) 目标是要在最少的试验下寻找一组最佳的超参数使得错误率能够越低越好。由於我们所收集到的资料无从得知该模型的目标函数是长怎样,因此机器学习的目的就是要从这些资料中去拟合一个函数,目标是给予一笔输入 X 该函数的输出要与真实的答案越接近越好。透过代理优化 (surrogate optimization) 使用一个代理函数来估计目标函数。简单来说代理函数是指目标函数的一种近似,此外代理函数可基於取样得到的资料点被构建出来。
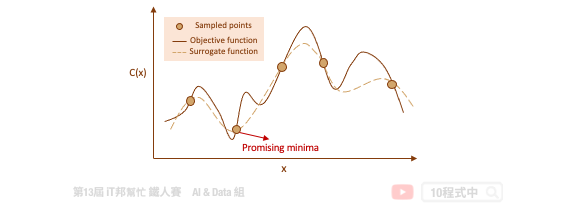
代理函数的目的是在给定一组特定的候选超参数的情况下快速估计实际模型的错误率。透过这种方式可以快速决定该组超参数是否可以被拿来实际训练模型。随着试验次数的增加,代理函数随着先前的试验结果而更新改进,并开始推荐更好的候选超参数。
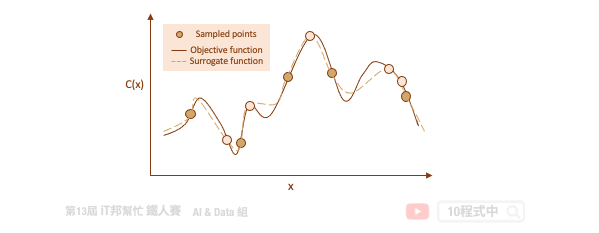
Auto-sklearn 就是一个透过贝叶斯优化来寻找最佳超参数的一个工具。同时它也能搜索在 Sklearn 中所有可能的算法,并为你推荐一个合适的模型与资料前处理方式。明天我们就来一探究竟该套件背後的神秘原理以及程序实作吧!
Reference
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: [Day16] TS:在 Mapped Type 中修改物件的 property modifiers:理解 Partial、Required 和 Readonly 的实作
【DAY 22】Algorithm - Insertion sort 插入排序法
前面我们提过了 Bubble sort,这次我们要来从题目来看另一种排序的演算法 —— Insert...
Day17 - 解析推文
今天先来初步的解析文章的推文。 首先送出"G"跳到文章的最後一页,之後的功能也预...
AE-LED流动效果3-Day21
接续昨天的练习~ 1.一开始所有图形会在同一个位置,不是我们想要的效果,所以把将时间轴往左移,让所有...
【6】为什麽 Batch size 通常都是设成2的n次方
Colab连结 有没有人发现几乎每个在开源的专案上,Batch size 都是2的N次方,像32, ...
资料库 组别
资料库 https://wolkesau.medium.com/资料库-ad3ec2a1344e 浅...