[神经机器翻译理论与实作] 你只需要专注力(I): Attention Mechanism
前言
Google 翻译团队在2016年发表了重要文章《Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation》,其中提出了深层 LSTM 翻译器网络 GNMT 。其由多层的 LSTM 建构编码器及解码器所构成,并在加入了注意力机制( attention mechanism ),大幅提升了长句翻译的效率。
2016年提出的GNMT翻译器架构加入了注意力机制:
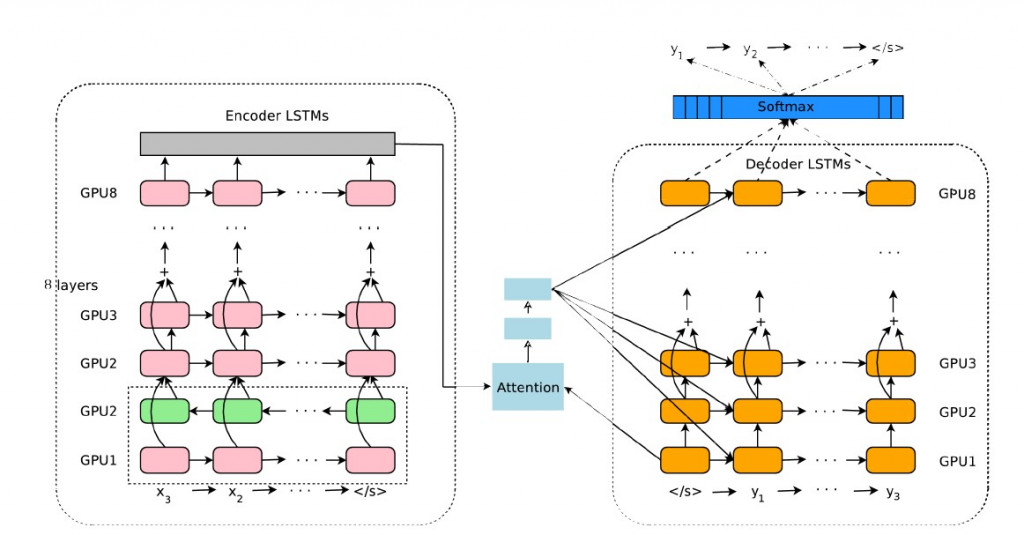
NMT is often accompanied by an attention mechanism which helps it cope effectively with long input sequences.
文字出处:GNMT (2016)

图片来源:Make a Meme.org
到底要专注什麽呢?
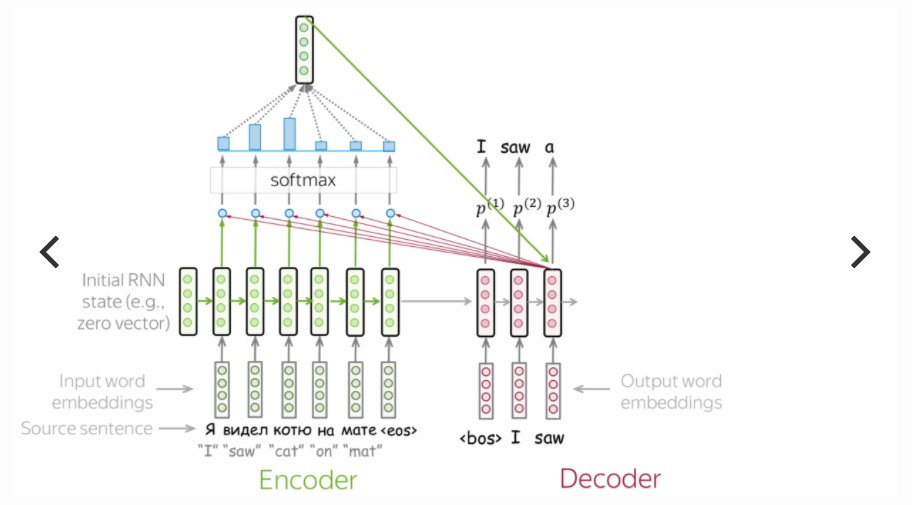
Seq2seq 模型先经由编码器来吃进所有输入的词向量( word embedding ),内部状态(例如 RNN 的 hidden state 或 LSTM 的 hidden state 和 cell state )的递嬗,暂时存在单一个 context vector 里,再传入解码器之间依照时间序吐出目标词向量,完成目标文句的预测。
传统encoder-decoder的翻译过程:
图片来源:jalammar.github.io
虽然 LSTM 增加了内部状态 cell state 来保存长期记忆,弥补了传统 RNN 长距离依赖的问题(白话来说 RNN 很健忘),传统基於 LSTM 架构的 seq2seq 模型依旧难以克服序列化计算所带来的低效率。改善方法就是在解码器生成新的词向量之前,由上帝视角来「注意」编码器当中所有时间点的内部状态,这便是注意力机制!
如何保持专注力?
在生成当下时间点的词向量之前,我们有以下几个步骤要做:
- 站在当下的内部状态
回望编码器各个时间点的内部状态

- 评估两两内部状态之间的关联性分数
,这是为了衡量目标单词与各个输入单词之间的关联性

- 根据关联性分数计算出目标单词在所有输入单词之中的注意力权重:

- 产生当下时间点的 context vector
:

- 将
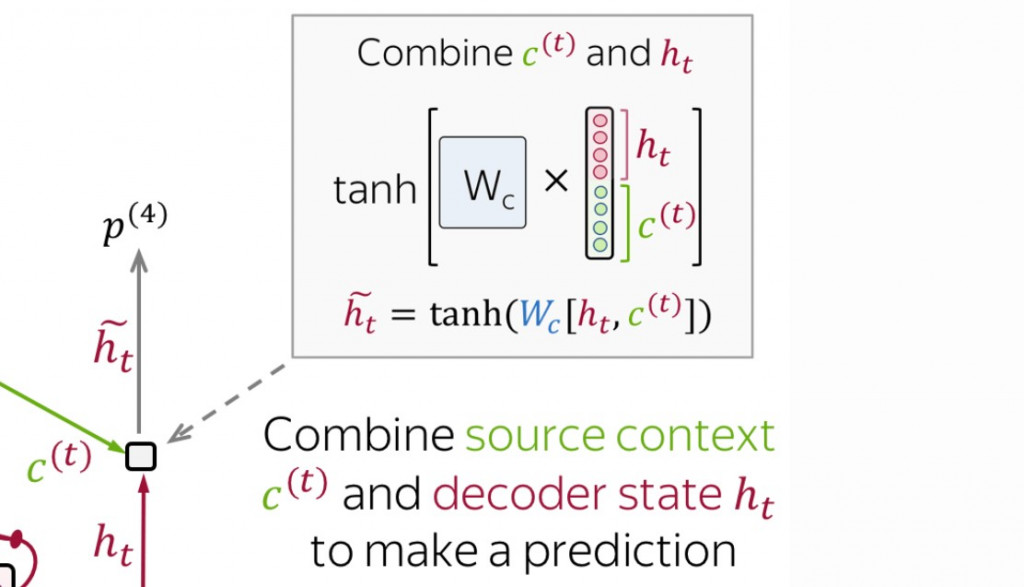
(以上步骤图片来源:Sequence to Sequence (seq2seq) and Attention)
经过了所有时间点之後,我们在编码器与解码器之间架起了多个 context vectors ,实现平行化计算( parallelism ),较传统的 seq2seq 翻译速度更快。
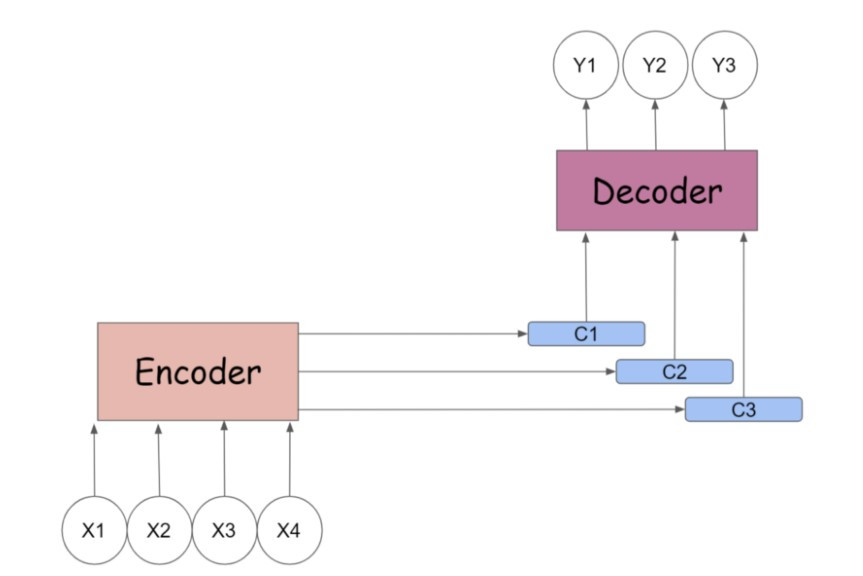
图片来源:medium.com
计算关联性分数
在上述的四个步骤中,我们如何求出关联性分数呢?
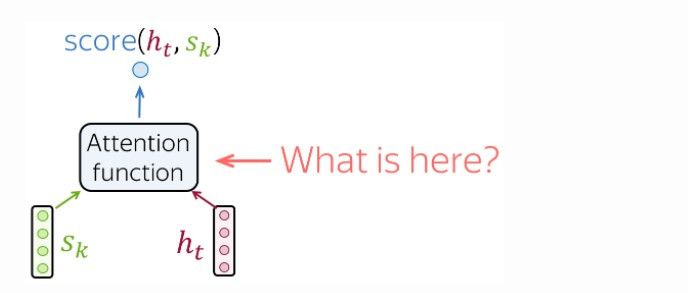
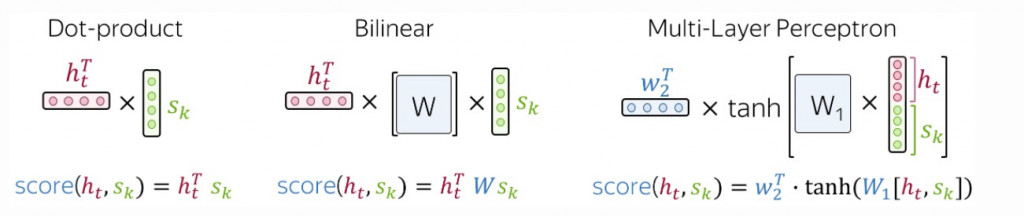
最常采用的三个计算方式有:
- 点积法( dot-product approach ):
点积便是我们在中学几何学中的标准向量内积,这是最简单的方法,其计算方式如下图 - 双线性法( bilinear approach ):
又称为 Luong attention ,计算权重方阵的双线性形式( bilinear form ),其计算方式如下图 - 多层感知器法( multi-layer perceptron ):
又称为 Bahdanau attention ,将内部状态并列起来,配上权重後输入激活函数,再求出加权平均,其计算方式如下图
我们可以将每个输入单词序列与目标单词序列之间的关联性分数以矩阵来呈现(输入与输出文句的长度通常并不一,因此并非方阵),其表示了各个输入单词与目标单词之间的关联性:

图片来源:Neural Machine Translation by Jointly Learning to Align and Translate (2016)
结语
附带注意力机制的 seq2seq 模型能够实现 encoder 与 decoder 之间的平行计算,以提升神经机器翻译的文字生成效率。最重要的是,注意力机制允许编码器中尚未传递完成的内部状态也输入解码器,藉由比较当下输出与各输入单词之间的相关性,能避免逐字翻译的窘境,增加了翻译的准确度。在2017年 Google 又在各层 LSTM 神经元之间加入了审视各层内部状态与下一层其他内部状态之间的注意力机制,被称之为自注意力机制( self-attention mechanism ),与今天所介绍的 encoder-decoder attention 相对。这种机制藉由找出文中与某单词最高度相关的其他单词,更加提升了语意的判读。今天的理论就介绍到这边,明天将进行在翻译器神经网络之间加入注意力的实作。期待与各位明天再会,晚安!
阅读更多
- Sequence to Sequence (seq2seq) and Attention
- Luong Attention: Effective Approaches to Attention-based Neural Machine Translation
- Bahdanau Attention: Neural Machine Translation by Jointly Learning to Align and Translate
追求JS小姊姊系列 Day18 -- 方函式的能力展现:第三型态 Constructor function 登场
前情提要 不论如何,似乎都有人能帮忙方函式收东西 方函式:好像还没提到我的第三型态 -- 建构式 我...
Day 09:Python基本介绍02 | 变数、资料型态
⚠行前通知 考量到有些人可能还没学过Python,然後我的主题又是定为从HTML到Python爬虫的...
Proxmox VE 安装容器:Rocky Linux 8.4 及其它应用 (WordPress, Nextcloud, Odoo)
前一章我们采用 Proxmox VE 所提供的现成范本档,方便快速的布建完成一部 Ubuntu 2...
[常见的自然语言处理技术] 文本相似度(II): Cosine Similarity
前言 昨天我们使用了 Python 自然语言处理套件 spaCy 预训练好的 word embedd...
DAY27 mongo aggregate
今天要教 mongo aggregate 中文叫做聚合 是一种将来自多个document的value...