[常见的自然语言处理技术] 文本相似度(II): Cosine Similarity
前言
昨天我们使用了 Python 自然语言处理套件 spaCy 预训练好的 word embedding model 将英文单词转换成为高维度的向量。今天就让我们接着谈我们如何衡量单词在意义上的远近吧!
余弦相似性(Cosine Similarity)
我们与恶的距离
我们将单词表示成高维度的向量,根据 word embedding 的特性:两两愈是意义相近的单词,它们的向量距离就愈接近。因此我们可以纯然地从向量之间的距离大小,反推单词的语意亲疏程度。以下分别介绍用来测量向量距离常见的三种方式:
-
欧氏距离( Euclidean Distance ):
在中学时期我们学习过测量向量距离的方式-两向量箭头端点相连直线段的长度,这也是欧氏空间( Euclidean space )中最常被使用来距离测定的方式。在n维空间上的欧氏距离定义如下:
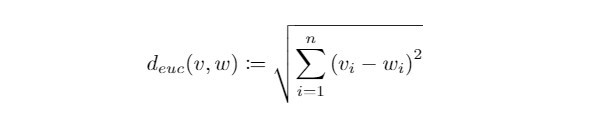
-
曼哈顿距离( Manhattan Distance ):
有别於我们最习惯的直线距离,曼哈顿距离考虑两点之间方格线长度的总和,因此又被称为方格线距离,在n维空间上的曼哈顿距离定义如下:
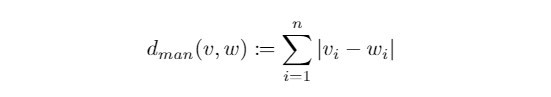
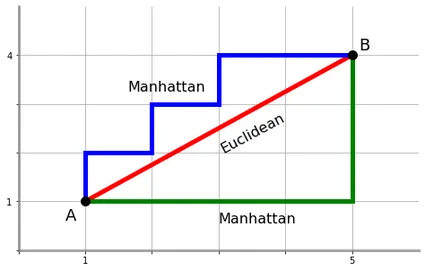
欧氏距离 v.s. 曼哈顿距离
- 余弦距离( Cosine Distance ):
我们知道藉由向量的内积运算可以找出两向量的夹角。对於长度特性并不重要的向量来说,可以计算两向量之间夹角来衡量两向量之间的距离。在夹角的讨论范围0°~180°之间,衡量角度等同於衡量角度的余弦值,也就是函数具有一对一的特性。两向量的夹角愈大, 它们的 cosine distance 就愈小,与常见的距离测量相反。这个衡量方式被称为余弦距离,其数学定义如下:
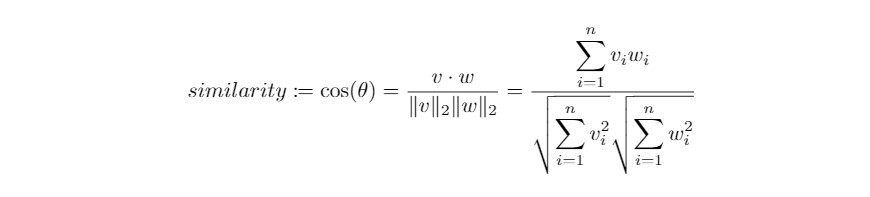

Word Embedding 最在乎的就是距离
word embedding 向量将语意资讯隐藏在各个维度的数值里。向量的方向有意义,而长度并不重要,因此用 cosine distance 来衡量 word embeddings 的距离再适合不过了!因着 cosine distance 可以衡量语意的相似程度,又被称为 cosine similarity 。在自然语言处理的实务上,使用cosine distance 来衡量距离有以下好处:
- 文本相似度往往与文本的长度无关,因此夹角的大小足以衡量距离的长短
- word embeddings 的维度通常很高,欧氏距离或曼哈顿距离的数值也会非常可观,而 cosine distance 只会落在-1到1之间
- 余弦值的计算复杂度较低,这项优势在处理稀疏向量( sparse vectors ,指的是大部分数值皆为0的向量,例如之前提过的 one-hot encoded vectors )上非常明显
夹角大小和语意相似度的关系
图片来源:www.bbsmax.com

在向量长度不重要的情境中,cosine similarity 可用来衡量向量之间的距离:
Cosine similarity is generally used as a metric for measuring distance when the magnitude of the vectors does not matter. This happens for example when working with text data represented by word counts. We could assume that when a word (e.g. science) occurs more frequent in document 1 than it does in document 2, that document 1 is more related to the topic of science. However, it could also be the case that we are working with documents of uneven lengths (Wikipedia articles for example). Then, science probably occurred more in document 1 just because it was way longer than document 2. Cosine similarity corrects for this.文字来源:cmry.github.io
使用spaCy比较语意相似度
我们使用 spaCy 套件中预先训练好的英文 word embedding model 。我们依旧使用最轻量的模型 en_core_web_sm ,若要向量化更广泛的单词,可以考虑下载其他模型: en_core_web_md、en_core_web_lg、en_core_web_trf 。
我们先将以下三个单词 like、love、hate 表示成向量,并且比较两两之间的相似程度:
import spacy
# import cosine distance metric
from scipy.spatial.distance import cosine
nlp = spacy.load("en_core_web_sm")
# vectorise words "like", "love", "hate"
word_1 = nlp("like").vector
word_2 = nlp("love").vector
word_3 = nlp("hate").vector
# compare semantic similarities
dist_1_2 = cosine(word_1, word_2)
dist_2_3 = cosine(word_2, word_3)
dist_3_1 = cosine(word_3, word_1)
print("similarity between 'like' and 'love': ", dist_1_2)
print("similarity between 'love'and 'hate': ", dist_2_3)
print("similarity between 'hate' and 'like': ", dist_3_1)
检视一下两两单词之间的 cosine similarity:

我们发现 like 与 love 非常相似,反之 love 与 hate 几乎无相关,这与我们的认知一致。
至於 like 与 hate 的相似度高达81%,说明它们经常出现在相同上下文当中。而这与模型训练的文件选择有关,下一集我们就来训练自己的 word embedding model!
今天的介绍就到这里,为期四天的中秋连假终於结束,明天又是上班日了!不知各位会不会有收假症候群呢?废话不多说,期待与各位在下一篇文章相见,晚安!
阅读更多
【DAY 6】沟通 0 距离 - Micorsoft Teams 的应用技巧
哈罗 ~ 大家好 ~ 欢迎回来 ~ 昨天提到 Power Automate 的自动化流程以及核准流程...
第44天~
这个得上一篇:https://ithelp.ithome.com.tw/articles/10258...
[Day 24] BDD - godog 小试身手
godog 简介 godog是Cucumber官方的Golang BDD(Behaviour-Dri...
Day20 - 在 XState 与 Side Effect 互动吧~ action API
1. Action 与 Side Effect 昨天,我们确认了状态能被储存起来,然而我们这个开门,...
事件监听的this:「这个」到底是哪一个?
欧阳克是谁杀的? 这个this是谁?要看凶手是谁而定! 前面有提到,这个e是在当事件发生时,事件处...