Day 18 : 模型前的资料处理 (2)
接着昨天的资料处理继续说明,今天来看看类别资料转换、资料降维、资料切割、交叉验证以及不不均衡的对应方法。
OS:资料预处理真的很重要啊啊!!
5.类别资料转换
由於机器学习无法了解每个类别所代表的意思,必须将输入的资料转换成为数值,因此我们必须将类别变数转换成数值。常用的有 LabelEncoder 和 OneHotEncoder。

LabelEncoder
将类别资料转换成数值顺序,将该栏类别映射到整数,不会新增栏位。像是衣服的size有分,假设某一份资料有 S、M、L、XL,依照 LabelEncoder 可以分成 0、1、2、3。而此时衣服大小有程度上的差异时,就会比较适合使用 LabelEncoder,让机器学习该栏位(因子)的大小关系。
from sklearn.preprocessing import LabelEncoder
# LabelEncoder
labelencoder = LabelEncoder()
train['Sex'] = labelencoder.fit_transform(train['Sex'])
train.head()

或是 pandas
train['Sex'].astype('category').cat.codes
OneHotEncoder
然而,将类别转换成数值形式会有大小之分。如果该栏位没有程度上的差异(例如性别),可能就比较不适合 LabelEncoder,会改用 OneHotEncoder。
OneHotEncoder (更常听到 One-Hot Encoding(独热编码)),描述将一个栏位有 N 种状态,改为 N 种栏位。需要注意的是,如果该栏位的 N 过大,往往会造成维度灾难(一下子会变超多栏位要预测),这时候可以再搭配降维(PCA)的操作,让资料维度进行缩减避免特徵空间过於庞大。因此要是 OneHotEncoder 的类别数目不太多,可以建议优先考虑之。
然而,有些演算法不需要,像是 tree based (像是 Random Forest 等等) 类型的演算法,不太需要使用 One-Hot Encoding,使用它会增加树的深度。
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder()
onehot = onehotencoder.fit_transform(train[['Sex']]).toarray()
pd.DataFrame(onehot)

或是 pandas
data_dum = pd.get_dummies(train['Sex'])
pd.DataFrame(data_dum)
直接回圈进行类别处理
比较偷懒的方式,对每个栏位使用 LabelEncoder。做机器学习做初步的尝试时,可以不进行任何资料特徵处理丢到机器学习,先得到第一次(或数次)的模型评估评估成效当作基准(baseline),有了 baseline 就可以超过它为目标,做其他不同尝试。(一个先找到低标的概念,之後94超越它)
# 用回圈的方式来做更快
for _ , col in enumerate(train.columns.tolist()):
if train[col].dtype == 'object':
train[col] = train[col].astype('category').cat.codes
6. 资料降维 (Dimension Reduction)
通常降维我们会采用 「主成分分析」(Principal Component Analysis, PCA),是一种特徵撷取(Feature Extraction)的方法。该方法希望将高维度的资料减少,但又不会影响资料原本的特性。其用意就是将复杂的问题简单化,萃取资料的精华再给机器学习演算法。
n_components 可选择降到多少维度
from sklearn.decomposition import PCA
X = train.drop(['Survived'], axis=1)
X = PCA(n_components=2).fit_transform(X)
7. 资料切割 (train-test-split)
拿到资料的时候,我们应该会有 training data ,testing data 不一定会有(因为有可能是未来的资料)。而在进行监督式的机器学习,我们通常会将 training data 进行资料切割,为了让模型在学模仿未来的环境。让模型去学习训练集的资料,让模型去对验证集的答案,藉此让我们了解在没看过的资料下的表现。
通常拿到一包资料可以分类 trainin data 和 testing data (testing data 不会当作训练资料)
- training data: 又可以分为训练集和测试集,这包资料的切分比例通常有 8:2 或 9:1
- testing data: 测试集

from sklearn.model_selection import train_test_split
X = train.drop(['Survived'], axis=1)
# 看是否需要降维
# X = PCA(n_components=2).fit_transform(X)
y = train.Survived
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
这里提醒一下,testing data 是测试集,是不可以拿去进行资料切割(如果你拿了,那演算法会看到答案等於作弊XD)。X_train, y_train 这边是指训练集;X_test, y_test 则是验证集
8. 交叉验证
在资料进行预测之前,通常会将资料分割。但是我们很可能会遇到极端的状况是,我们刚好切出来的验证集资料跟训练集很有相关,为了避免这种状况发生,我们可以进行交叉验证。所谓的交叉验证是将训练资料进行多次不同的切割,轮流当验证集,最後计算的时候取平均,比较能了解资料在不同情况下的成效。

9. 不均衡(Imbalanced data) 的对应方法
在现实生活中,往往可能会遇到资料极度不均衡的现象
- 信用卡交易异常
- 贷款找出违约
- 工厂的次级品
通常我们想要预测的 y 都非常稀少(跟日本的制作压缩机一样),因此机器学习可能都会猜 0 ,导致模型正确率超高啊
但却一点用都没有的模型(我们就是要知道违约的那个人是谁啊,结果你都猜都交易正常)
在资料探索的时候,如果我们发现资料有这种现象的话,我们不能只用 准确率当作唯一标准,可以拿上一节说的 F1 score
但还有呢? 可以让机器学得更好吗?当然有!
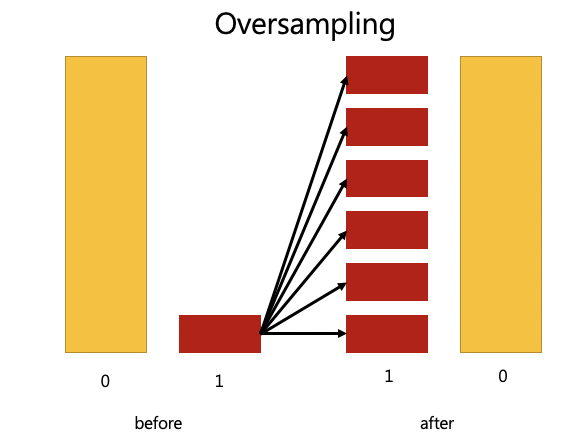
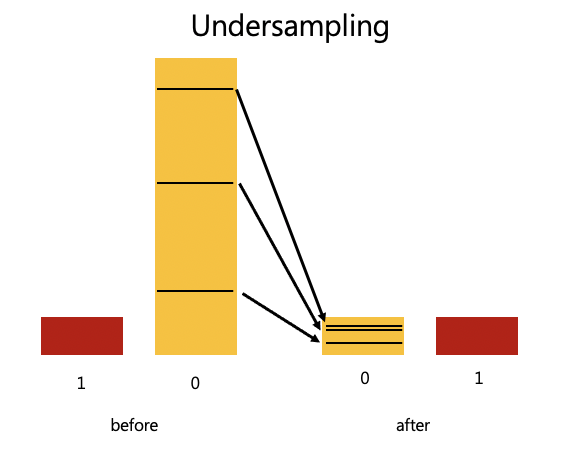
面对不均衡资料,我们也有解决之道,可以用 Resampiing,让多的变少,少的变多
-
over-sampling: 让 1 的资料倍增
-
under-sampling: 让 0 的资料缩小
Day26 - 区块链社会学读後感(上) 误解、信任
Likecoin 创办人高重建先生,最近写了一本《区块链社会学》。作者秉持「人文为主、科技为辅」,从...
Day17 [实作] RTCPeerConnection: 本机端模拟 P2P 的过程
上一篇我们通过简单的例子了解 Offer / Answer 的机制,今天我们要加上视讯: Bob 通...
[ JS个人笔记 ] Promise —DAY9
Promise 是用来优化非同步的语法。 Promise 物件状态 pending: 初始状态 fu...
协作图
UML 有四种表达 Entity 之间互动的图,分别是: 状态图、时序图、协作图、活动图,这次要介绍...
Day18 vue.js新增文章
延续昨日 今天我们来新增专案 首先需要先新增一个Addproject.vue 新增path 以及修改...