从 JavaScript 角度学 Python(29) - BeautifulSoup
前言
已经准备进入铁人赛的尾巴,所以这一篇就来介绍一个很常见的套件,也就是 BeautifulSoup,而这套件也是爬虫很常使用的套件,所以接下来就让我们来学习使用 BeautifulSoup 吧。
BeautifulSoup
Python 很常被用於网路爬虫,其中最多人用的就是 BeautifulSoup 套件,那...BeautifulSoup 套件是什麽东西呢?
这边就让我们直接看维基百科对於 BeautifulSoup 的说明:
Beautiful Soup是一个Python包,功能包括解析HTML、XML文件、修复含有未闭合标签等错误的文件(此种文件常被称为tag soup)。这个扩充包为待解析的页面建立一棵树,以便提取其中的资料,这在网路资料采集时非常有用。
透过上面解释我们可以粗略知道 BeautifulSoup 主要是帮我们解析下载回来的 HTML 档案套件,使用这个套件可以大大方便我们在撷取特定片段资料的方便性。
oh!对了,如果你有去查过 BeautifulSoup 的话,你会发现它的封面图会是一个中世纪风格的图片,而且你会发现它的图片很特别:

而 BeautifulSoup 这个名字是来自爱丽丝梦游仙境的一首诗所命名的,所以有些翻译文档甚至会说这是一份「爱丽丝的文件」,这也就是为什麽 BeautifulSoup 套件封面图片都会是中世纪的风格,毕竟爱丽丝梦游仙境当时的背景设定是在中世纪欧洲(如果没记错的话)。
那前面这边一开始只是简单小聊一下 BeautifulSoup 套件有趣的地方,接下来就让我们准备开始安装 BeautifulSoup 吧!
安装 BeautifulSoup
BeautifulSoup 在安装上跟 Requests 套件较不同,比较不用担心在 Python2 或是 Python3 版本上的套件名称不同,因为在安装 BeautifulSoup 的过程,都是相同的名称。
Python2:
pip install beautifulsoup4
Python3:
pip3 install beautifulsoup4
BeautifulSoup 基本使用
当你安装完毕之後,你可以先引入 BeautifulSoup 套件到你的 Python 专案中,但是这边有一个很特别地方,BeautifulSoup 在安装的时候,模组名称会是 bs4 ,所以通常我们在引入 BeautifulSoup 时都会重新命名一下:
from bs4 import BeautifulSoup # 这绝对不是你想像中的 Bootstrap4
还是在提醒一次,这边的 bs4 绝对不是 Bootstrap4 而是 BeautifulSoup4!(很重要)

接下来你可以尝试贴入官方所提供的范例程序码,而这又称之为爱丽丝文件:
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>
"""
那麽我们可以看到上面的 HTML 是被压缩过的,因此是非常难以阅读的,但是 BeautifulSoup 它可以将压缩过的 HTML 结构转换成标准的 HTML 缩排形式,也就是身为前端工程师可以读懂的格式,而用法也非常简单,只需要这样写就可以罗
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.prettify())
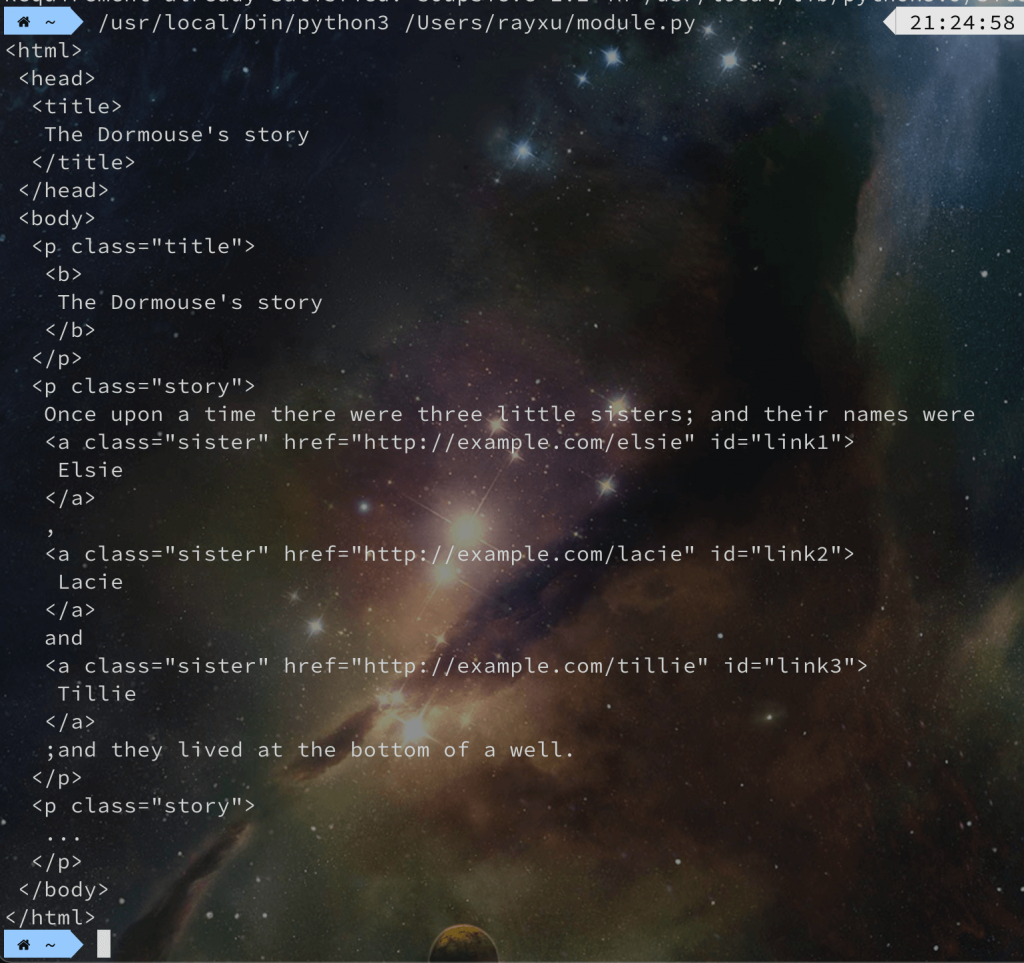
那这边我们可以看到其中一行是 soup = BeautifulSoup(html_doc, 'html.parser') 这一行的第二个参数其实是告诉 BeautifulSoup 要使用哪一种解析器来解析 HTML,基本上在官方网站上都有说明建议你使用哪一种解析器,以官方建议来讲,会建议你使用 lxml 的解析器,如果你要使用这个解析器的话就必须额外安装:
pip3 install lxml
安装完毕之後记得调整一下解析器:
soup = BeautifulSoup(html_doc, 'lxml')
最後你可以看到 print() 输出一个非常标准且整理过的 HTML,或许终端机你会觉得很难阅读,所以你也可以使用前面所学到的档案写入这个技巧来生成一个 HTML 档案:
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
f = open('index.html', 'w')
f.write(soup.prettify())
f.close()
届时你再去打开 index.html 就会很好阅读了,毕竟你是一名前端工程师对吧?

那麽基本上我们所有的操作都会跟 BeautifulSoup(html_doc, 'html.parser') 处理後的 soup 操作有关,举例你想取得 HTML 结构中的 title:
print(soup.title) # <title>The Dormouse's story</title>
那麽 BeautifulSoup 还有哪些东西呢?这边就让我们继续了解它吧!
搜寻 HTML 元素
BeautifulSoup 提供相当多的方法可以针对 HTML 标签去搜寻,那这边也让我们每一个都尝试看看。
find_all()
find_all() 可以用於搜寻复数的 HTML 元素:
print(soup.find_all('a')) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
其中 find_all 也可以针对 HTML 的属性来搜寻:
print(soup.find_all('a', { 'id': 'link3' })) # [<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
select()
那麽有特别针对 HTML 元素搜寻的方式,也就会有特别针对 CSS 选择器的方式搜寻 HTML 元素,首先是针对 ID 的方式:
print(soup.select('#link1')) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
另一种则是针对 class 搜寻:
print(soup.select('.story')) # [<p class="story">Once upon a time there were three little sisters; and their names were<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;and they lived at the bottom of a well.</p>, <p class="story">...</p>]
oh!题外话一下,select 也可以直接针对 HTMl 标签搜寻唷
print(soup.select('b')) # [<b>The Dormouse's story</b>]
find()
find() 虽然跟 find 感觉很像,但是它主要是回传一个符合条件的元素:
print(soup.find_all('a')) # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
select_one()
select_one() 从名称来讲也很明显的知道跟 find 很像,只会回传第一个符合的元素:
print(soup.select('.story')) # print(soup.select_one('.story')) # <p class="story">Once upon a time there were three little sisters; and their names were<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;and they lived at the bottom of a well.</p>
取出 HTML 内容
前面我们知道如何取得我们要的元素之後,那该怎麽取出 HTML 元素中的东西呢?例如取出 HTML 元素中的文字,举例来讲 <b>The Dormouse's story</b> 中的 The Dormouse's story 这一段文字。
那这边将会使用前面的这一段范例:
print(soup.find_all('a')) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
text
这个语法非常简单,可以直接取出 HTML 的文字:
print(soup.find_all('a')[0].text) # Elsie
attrs
接下来是如果你想要取出 HTML 的属性的话,可以使用这个方法,但是要注意它会回传一个字典:
print(soup.find_all('a')[0].attrs) # {'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
target
当然如果你不想要回传那麽一个物件的话,可以直接指定属性回传:
print(soup.find_all('a')[0]['href']) # http://example.com/elsie
题外话一下,如果你是使用 get 方法的话,若这个属性不存在则也是可以的唷~
print(soup.find_all('a')[0].get('title', '我不存在')) # 我不存在
那这边这边就只列出我常用的 BeautifulSoup 方法,实际上如果想看更详细的会建议可以看官方文件唷~
作者的话
这几天跟朋友聊天聊到自己以前做版本控制的做法...
日期+版本号这种方式,结果结案的时候变成...
20130307_v1.zip
20130307_v2.zip
20130307_v3.zip
20130307_v4.zip
20130307_v5.zip
...
真庆幸自己学会使用 Git 之後这种状况就没有出现了。
关於兔兔们
- Tailwind CSS 台湾官网
- Tailwind CSS 台湾 (脸书粉丝专页)
- 兔兔教 × Tailwind CSS Taiwan (脸书社群)
- 兔兔教大本营

[NestJS 带你飞!] DAY16 - Configuration
前一篇我们运用 Dynamic Module 与 dotenv 设计了一个简单的环境变数管理模组,但...
自动化 End-End 测试 Nightwatch.js 之踩雷笔记:select option
相信 E2E 一定有做过遇到这种需要选择的部分,结构大致上会长这样 <select class...
【JavaScript】几个语法糖
【前言】 本系列为个人前端学习之路的学习笔记,在过往的学习过程中累积了很多笔记,如今想藉着IT邦帮忙...
Day27 跟着官方文件学习Laravel-Request 生命周期
Laravel 文件中有跟我们介绍一个 request 的生命周期,也就是诞生到结束在 Larave...
day28 等一下啦,会坏掉的/// Coroutine并发操作的重复请求
没有要开车,参赛规定有写不能污言秽语,等我有空再去其他平台写个开车系列的coroutine 这里给个...