[Day29] 不敢把聊天纪录上传到分析网站? 自己用Python分析LINE聊天纪录!
大家会不会很好奇跟朋友在LINE上最常讲的话是什麽? 或是跟朋友讲了几通电话呢?
前阵子很流行把LINE聊天纪录传到分析网站去分析各种数据,
但需要把聊天纪录传到该网站><
虽然开发者说不会有个资外泄问题,但是不怕一万只怕万一,还是自己写程序分析最安全~
使用环境
- Python
- jieba (中文分词套件)
- cutecharts (可爱手绘风可视化图表库)
步骤解析
-
先到LINE下载和想分析对象的对话纪录(txt档)
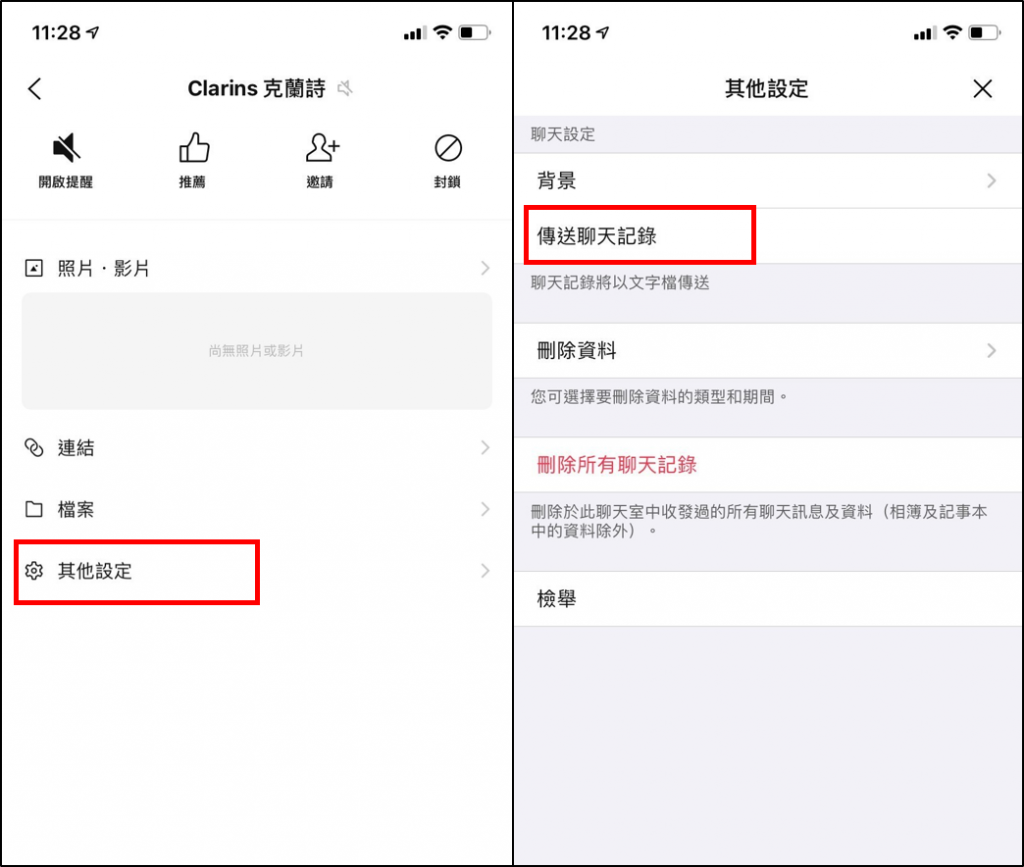
-
用jieba中文分词工具将下载的文字档做中文分词,找出出现最多次的词,而不是单字。
-
去除不需要分析的资料,例如上午、下午、数字(讯息传送时间)。
-
将分析结果用cutecharts图表显示。
程序码
#encoding=utf-8
import jieba
import jieba.analyse
from cutecharts.charts import Bar
from cutecharts.charts import Pie
content = open('line.txt', 'rb').read()
words = jieba.lcut(content) # 使用jieba这个library对文档内容进行分词
counts = {} # 此为由文字内容对应到出现次数的dictionary
# 进行统计
for word in words:
if len(word) <= 1: # 排除单个字
continue
elif word.isdigit(): # 排除数字
continue
else:
counts[word] = counts.get(word, 0) + 1
# 删除不重要的词语
text=' '.join(words)
excludes = {'\r\n','下午','上午','...'} # LINE纪录会有很多换行,如不去掉分析完会显示
for exword in excludes:
try:
del(counts[exword])
except:
continue
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True) # 根据单词出现次数进行排序
# 将出现次数最多的几个词画成图表
top_words = []
top_counts = []
i = -1
while len(top_words) <= 10:
i += 1
word, count = items[i]
if word == "通话" or word == "照片" or word == "影片" or word == "贴图" or word == "你的名字" or word == "对方名字":
continue
top_words.append(word)
top_counts.append(count)
chart = Bar("关键字图表")
chart.set_options(labels = top_words, x_label="单词", y_label="出现次数")
chart.add_series("次数", top_counts)
chart2 = Pie("通话/影片/照片数统计")
chart2.set_options(labels=['照片', '影片', '通话'])
chart2.add_series([counts.get("照片", 0), counts.get("影片", 0), counts.get("通话", 0)])
chart3 = Pie("传送讯息量")
chart3.set_options(labels=['你的名字', '对方'],inner_radius=0)
chart3.add_series([counts.get("你的名字", 0), counts.get("对方名字", 0)])
chart.render(dest="关键字.html")
chart2.render(dest="通话/影片/照片数统计.html")
chart3.render(dest="传送讯息量.html")
成果发表会
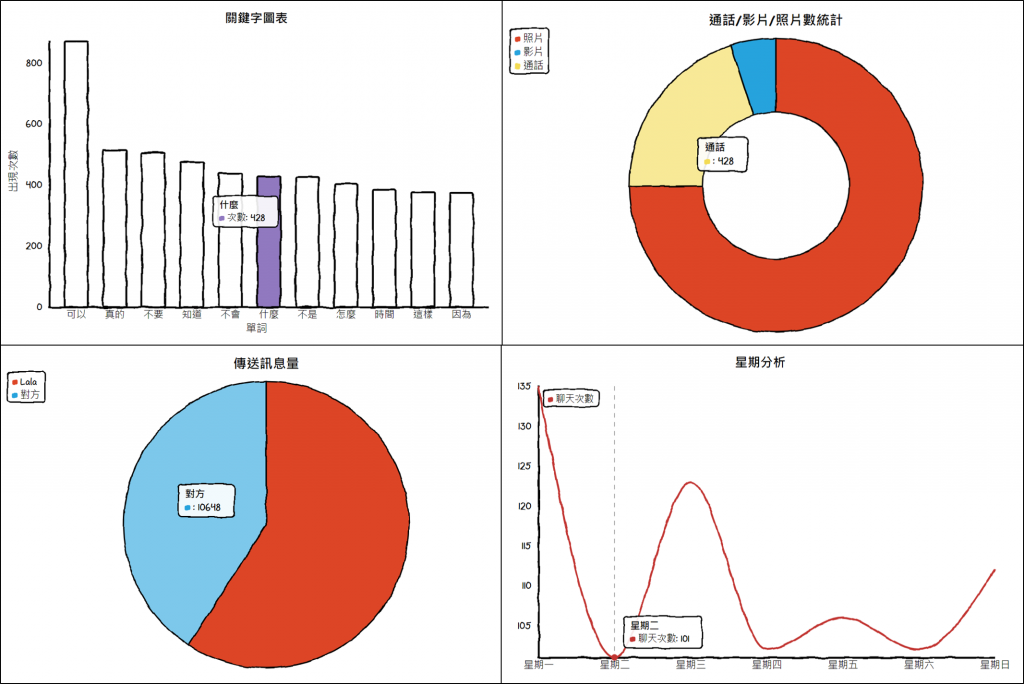
虽然要等个几秒让jieba分词,但是整体速度还是很快,而且自己做出来的感觉也不一样~
[Day29] Room创出来就好吗?
当然要拿来用啊 於是我想利用Room 当我储存每个平台帐号密码的资料库 并且要可以浏览每个平台 这个...
@Day8 | C# WixToolset + WPF 帅到不行的安装包 [自订动作]
前两天 已经建立好的自订页面, 现在我们要为这些页面上Action, 而WixToolset有专门自...
资料结构和演算法
https://wolkesau.medium.com/资料结构和演算法-c3a453c9c64c ...
Day 14. Tutorial: Create a scene flow - 10. Challenge Answer
如果你也有跟着教程做的话,第10节有个练习,可以来跟我交流一下答案,我也不知道我的写法是不是好的,但...
【Day13】数据展示元件 - Accordion/Collapse 摺叠面板
元件介绍 Accordion 是一个可折叠/展开内容区域的元件。主要是针对显示内容复杂或很多的页面进...