Day27-机器学习(1) SVM
SVM简单说明
为一种监督学习的方法,其原理是会根据资料的数据,划出一条界线来区分各群
我举个例子说明:
假如我们今天有一个任务,是要区分此生物是否为海洋生物
我们把海平面以下的生物都当作是海洋生物,海平面以上则否
海平面这个界线就是我们SVM的训练结果,此界线就是我们拿来分群的标准
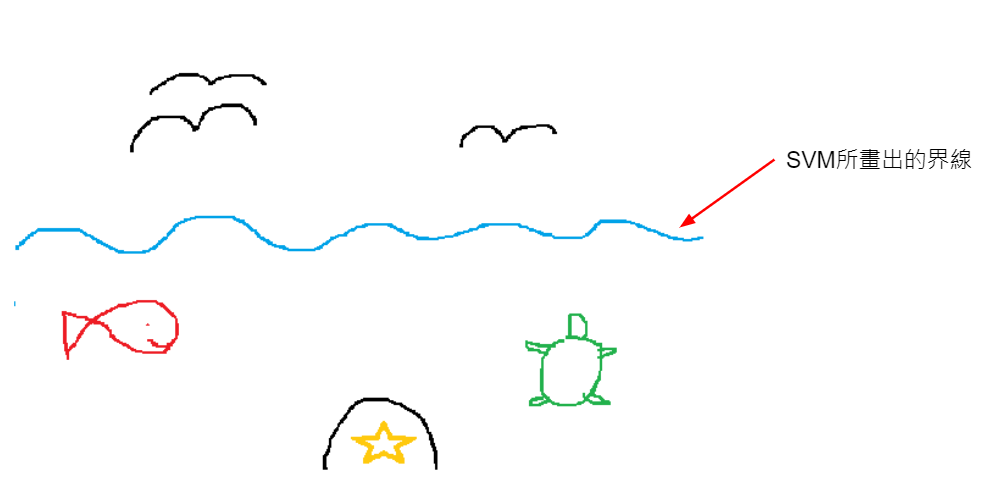
我只是以2维平面的方式来比喻,真正我们在训练时,资料维度都很高,所以无法图像化
反正我们知道其原理就好了
使用方法
这边我使用的资料集为Titanic
前处理我直接跟Day24、25、26的一样,如果想了解可以去看前面的文章
import SVM
from sklearn import svm
自己先设一个变数,此变数为你的model名称,并将svm.LinearSVC()指派给它
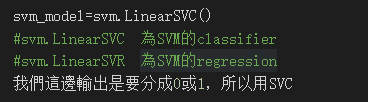
训练model
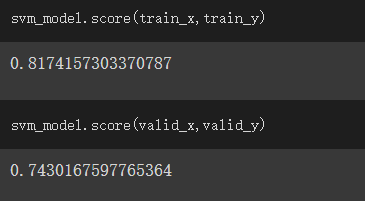
查看训练结果的成绩
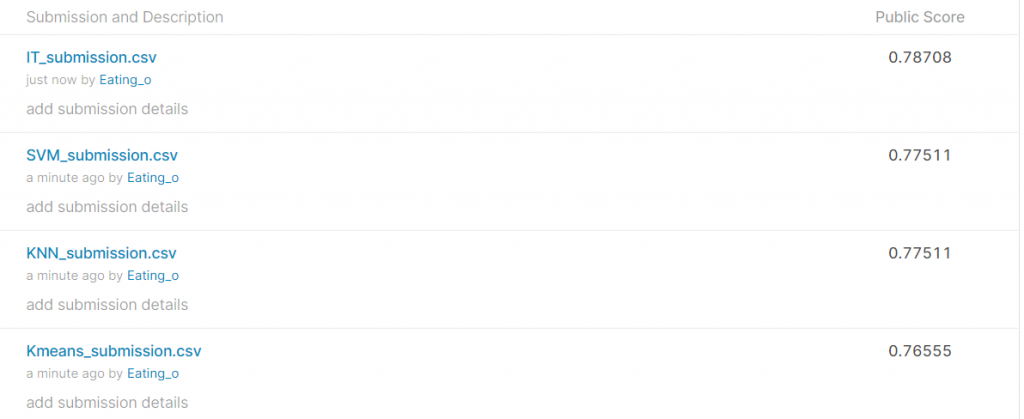
使用model预测结果

输出CSV档之後就可以缴上kaggle titanic罗
缴交结果
IT_submission 为DNN的训练结果(前面文章有写)
SVM_submission 为SVM的训练结果(就是本文章的结果)
KNN_submission 为KNN的训练结果 (後面文章会写)
Kmeans_submission 为Kmeans的训练结果(後面文章会写)
此全部都用相同的资料前处理
附上程序码,程序码我有分过目录,你可以直接跳到SVM
https://colab.research.google.com/drive/1sQrInNscPzKSMuekyH1Cwz1dYSB9PSNT?usp=sharing
Day 14-假物件 (Fake) - 模拟物件 (Mock)-3 (核心技术-6)
只针对一个关注点测试 昨天提到虚设常式与模拟物件的差异,两者之间之差在验证的时候如果是用该假物件验证...
列表与 Key ( Day 10 )
如果有使用过其他框架的经验,可能会需要熟悉一下React 的写法,是由 JSX 搭配回圈去产生。以下...
Day21 - 用 Ruby on Rails 抓台湾证券交易所资料-除权除息计算结果表
前言 这篇主要以抓「台湾证券交易所」的「除权除息计算结果表」为主 取得「除权除息计算结果表」CSV ...
Day 13 - 非同步元件
在大型专案中,我们会需要注入大量的元件,每次都要把所有的元件载入有时相对耗效能,这时候就可以使用非同...
大脑如何精准学习 (4) 固化
在学习时,假设拥有前三项要素:注意力、主动参与、保持错误回馈。但这时候,可能还有一个问题,就是很慢、...