[Day 16] 每个模型我全都要 - 堆叠法 (Stacking)
堆叠法 (Stacking)
今日学习目标
- 了解 Stacking 方法
- 堆叠法的学习机制为何?
- 利用 Stacking 实作回归器
- 透过 Stacking Regressor 建立房价预测模型
前言
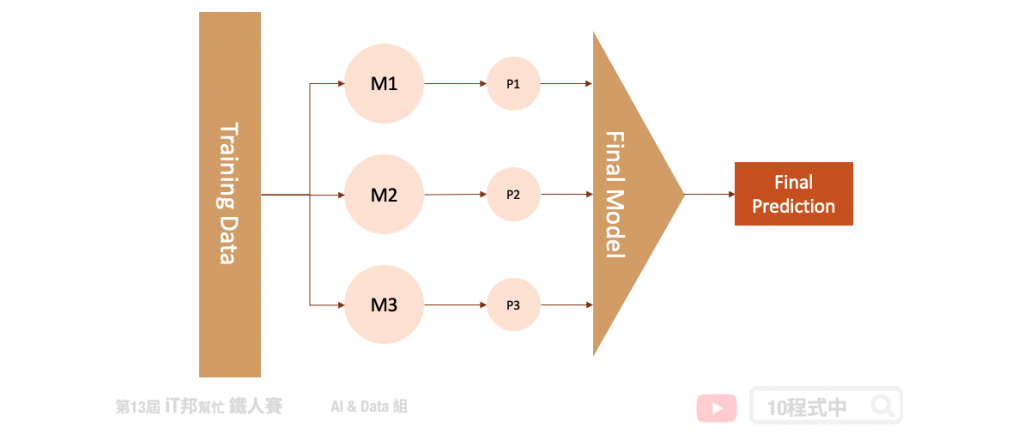
堆叠法 (Stacking) 是整体学习中其中一种实例。它是结合许多独立的模型所预测出来的结果,并将每个独立模型的输出视为最终模型预测的输入特徵,最後再训练一个最终模型。以下图为例,假设我们事先训练三个基底的模型 (base learner),这三个模型彼此互相无关连。由於每一个模型所训练出来的预测能力都不同,也许模型一在某个区段的资料有不太好的预测能力,而模型二能补足模型一预测不好的地方。藉由上述这个观点我们将三个训练好的模型输出集合起来(P1、P2、P3),如果是分类问题可以透过投票方式,而回归问题可以采用平均法或是加权平均法将所有的预测做最後评估。又或者是可以将这三个输出值当作是新模型的特徵再丢入一个机器学型模型做最後的预测得到最终输出。
[程序实作]
在此范例中我们透过 Sklearn 所提供的波士顿房价预测资料集进行 Stacking 方法建模。并观察同一组资料在单一模型下预测,与加入 Stacking 机制後的结果有无改善。
1) 载入资料集
首先我们够过 Sklearn 套件读入波士顿房价资料集,并将输入特徵与房价合并成一个 DataFrame。在此资料集中总共有 13 个输入特徵,以及一个输出 MEDV 即为房价。
# load boston_dataset
boston_dataset = load_boston()
boston = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names)
boston['MEDV'] = boston_dataset.target
boston
2) 切割训练集与测试集
在此范例中我们着重於比较模型的差异,因此没有按照正常的机器学习流程走。资料视觉化以及前处理...等是非常重要的哦!在此步骤我们快速物的将乾净的资料切出训练集与测试集,其中训练集 X_train 与 y_train 是实际参与行训练的资料。而 X_test 与 y_test 是未参与训练的资料,它是被拿来测试评估最终训练好的模型。
from sklearn.model_selection import train_test_split
X = boston.drop(['MEDV'],axis=1).values
y = boston[['MEDV']].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)
print('Training data shape:', X_train.shape)
print('Testing data shape:', X_test.shape)
由於 Sklearn 资料集提供的资料样本数比较少,因此测试集仅切出 0.1 的资料。
执行结果:
Training data shape: (455, 13)
Testing data shape: (51, 13)
XGBoost 模型
因为要与 Stacking 做一个比较。因此这里使用 XGBoost 先训练一个模型,并将结果与 Stacking 做比较。
from xgboost import XGBRegressor
# 建立 XGBRegressor 模型
xgboostModel = XGBRegressor()
# 使用训练资料训练模型
xgboostModel.fit(X_train, y_train)
# 使用训练资料预测
predicted = xgboostModel.predict(X_train)
print("训练集 Score: ", xgboostModel.score(X_train,y_train))
print("测试集 Score: ", xgboostModel.score(X_test,y_test))
从预测结果我们先来查看 R2 score,一切看似还 ok。不过这里要呼吁各位读者绝不要看 R2 分数高就高兴得太早!
执行结果:
训练集 Score: 0.9999920949016282
测试集 Score: 0.9292786904177338
我们来看一下 MSE 实际算一下训练集与测试集的误差。可以发现很明显的过度拟合了,简单来说在训练集的资料算出来的 MSE 很小,但是在测试集中 MSE 预测能力不足造成误差变大。
from sklearn import metrics
# 训练集 MSE
train_pred = xgboostModel.predict(X_train)
mse = metrics.mean_squared_error(y_train, train_pred)
print('训练集 MSE: ', mse)
# 测试集 MSE
test_pred = xgboostModel.predict(X_test)
mse = metrics.mean_squared_error(y_test, test_pred)
print('测试集 MSE: ', mse)
执行结果:
训练集 MSE: 0.0006847746512112584
测试集 MSE: 4.415429632025227
Stacking 模型
Stacking 结合许多弱学习器,将所有的弱学习器的输出当作新的模型的输入接着预测最终结果。在此范例中我们建立了四种回归器,分别有随机森林、支持向量机、KNN 与决策树。最终的模型我们采用两层隐藏层的神经网路作为最後的房价预测评估模型。
Parameters:
- estimators: m 个弱学习器。
- final_estimator: 集合所有弱学习器的输出,训练一个最终预测模型。预设为LogisticRegression。
Attributes:
- estimators_: 查看弱学习器组合。
- final_estimator: 查看最终整合训练模型。
Methods:
- fit: 放入X、y进行模型拟合。
- predict: 预测并回传预测类别。
- score: 预测成功的比例。
- predict_proba: 预测每个类别的机率值。
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn import svm
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import StackingRegressor
from sklearn.neural_network import MLPRegressor
estimators = [
('rf', RandomForestRegressor(random_state = 42)),
('svr', svm.SVR()),
('knn', KNeighborsRegressor()),
('dt', DecisionTreeRegressor(random_state = 42))
]
clf = StackingRegressor(
estimators=estimators, final_estimator= MLPRegressor(activation = "relu", alpha = 0.1, hidden_layer_sizes = (8,8),
learning_rate = "constant", max_iter = 2000, random_state = 1000)
)
clf.fit(X_train, y_train)
print("训练集 Score: ", clf.score(X_train,y_train))
print("测试集 Score: ", clf.score(X_test,y_test))
我们先观察训练後的 R2 score 在训练集与测试集上的分数。从数值看观察可以发现透过堆叠法两者间的分数差距变小了。
输出结果:
训练集 Score: 0.9608703782891547
测试集 Score: 0.9371735287625855
from sklearn import metrics
# 训练集 MSE
train_pred = clf.predict(X_train)
mse = metrics.mean_squared_error(y_train, train_pred)
print('训练集 MSE: ', mse)
# 测试集 MSE
test_pred = clf.predict(X_test)
mse = metrics.mean_squared_error(y_test, test_pred)
print('测试集 MSE: ', mse)
接着我们一样计算 MSE 实际观察模型在训练集与测试集上的误差。从计算解果可以看到两者的误差都是差不多的。从这里我们就可以很清楚的知道透过 Stacking 可以避免模型过拟合,并且透过多个基底的模型让最终预测结果有比较平滑的输出。
输出结果:
训练集 MSE: 3.389581229598408
测试集 MSE: 3.9225215768179433
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: [Day27] Esp32 + IFTTT + Google Sheet
>>: [Day 28] Node thread pool 3
使用贴图新增与移除身分组
使用Auttaja 点击Dashboard 选择Assignable & Giveable ...
[Day - 10] - 运用FlywayDB自动化整合Spring JPA 的模式注解之旅
Abstract 在一套系统架构中,势必需要运用到资料库的存取概念,开发者势必都会选择一种ORM[S...
ASP.NET Core 3 起布置在 Windows IIS 方式改变
最近要升级 windows 服务器的 ASP.NET Core 2.1 专案到 3.1 版本,发现 ...
Unity自主学习(十九):物件脚本(1)
昨天在"Main Camera"新增了一个"Test"的脚本...
[Day2] What is Pentest
渗透测试简介 今天来跟各位介绍一下,什麽是渗透测试。渗透测试(Penetration Test),简...