Day28 Project4 - web crawler
今天来做一个爬虫的功能,以爬取铁人赛的所有参赛者的标题及名称为目标
先点开铁人赛的选手列表页面,首先可以观察到如果是使用报名顺序来排列的话在url上面会多一个order的key,其value=signup,再来每个页面只会显示10则讯息,但今天的目标是要找到所有的参赛者,所以需要一页一页往下点,也会观察到点到别的页面时在url上也会多一个page的key。
此时已经观察好网页显示的规则了,就可以打开Chrome的工具来寻找要爬取的tag name了,在开始写code之前先下载一个Laravel 专用的爬虫套件,回到VSCode下指令
composer require symfony/dom-crawler
为了专注在爬虫这件事情上面也是用Command的方式来制作速度会比较快
php artisan make:command crawlWeb
protected $signature = 'crawler:web';
protected $description = 'Participating title and contestants';
引入读取HTML套件及网页解析套件
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;
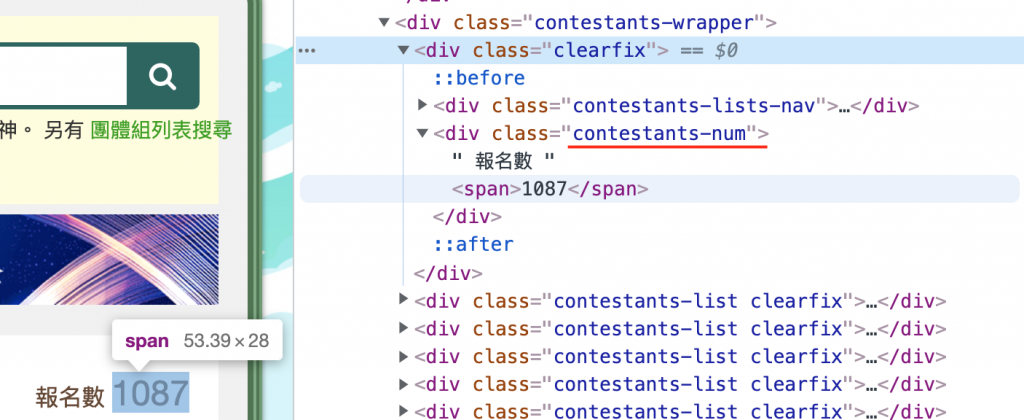
为了解决每一页的url不一样的问题,必须先做第一次的爬取,算出要爬的页面数量,用Chrome可以观察到报名数使用了div tag来包装,并给予class = contestants-num,并且在数量的地方又用了span tag来包装。
$path = 'https://ithelp.ithome.com.tw/2021ironman/signup/list';
$client = new Client;
$content = $client->get($path)
->getBody()
->getContents();
$crawler = new Crawler();
$crawler->addHtmlContent($content);
$number = (int) $crawler->filterXPath('//div[contains(@class, "contestants-num")]')
->filterXPath('//span')
->text();
$crawler = null;
$client此物件负责将整个HTML爬取回来
crawler此物件利用tag来解析HTML
使用text function 提取出来的资料会以字串的方式呈现,但我需要的是数字,所以在前方加上(int)
来固定型别
crawler物件使用完之後就没用了,将其设为null释放记忆体避免後续记忆体不足
接着观察每个专题的配置
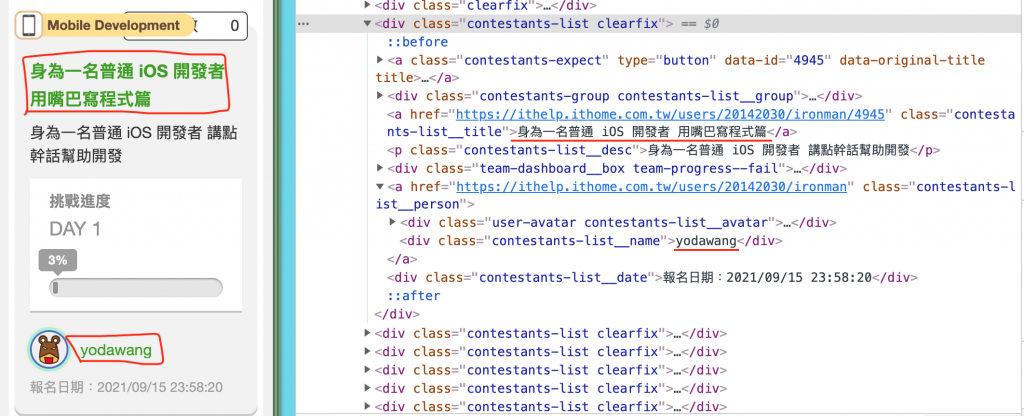
每个专题都会被一个div tag包装,并且以 class = contestants-list clearfix 来做为识别,
因为每一页会有十个专案,将十个专案爬取回来後利用each及匿名函式来做资料处理,每个专案底下的专案名称会使用div tag包装,并以 class = contestants-list__title用来识别,作者则是 class = contestants-list__name。
取得报名者数量之後就可以推断出页面数量了,使用for回圈来爬取每一页的资讯
for ($page = 1; $i < $number / 10 + 1; $page++) {
$path = 'https://ithelp.ithome.com.tw/2021ironman/signup/list?order=signup&page=' . $page;
$content = $client->get($path)
->getBody()
->getContents();
$crawler = new Crawler();
$crawler->addHtmlContent($content);
$projects = $crawler->filterXPath('//div[contains(@class, "contestants-list clearfix")]');
$projects->each(function($node) {
$projectName = $node->filterXPath('//a[contains(@class, "contestants-list__title")]')
->text();
$author = $node->filterXPath('//div[contains(@class, "contestants-list__name")]')
->text();
$message = '标题 : ' . $projectName . ' 作者 : ' . $author;
$this->info($message);
});
$crawler = null;
sleep(1);
}
接着就可以下指令开爬
php artisan crawler:web
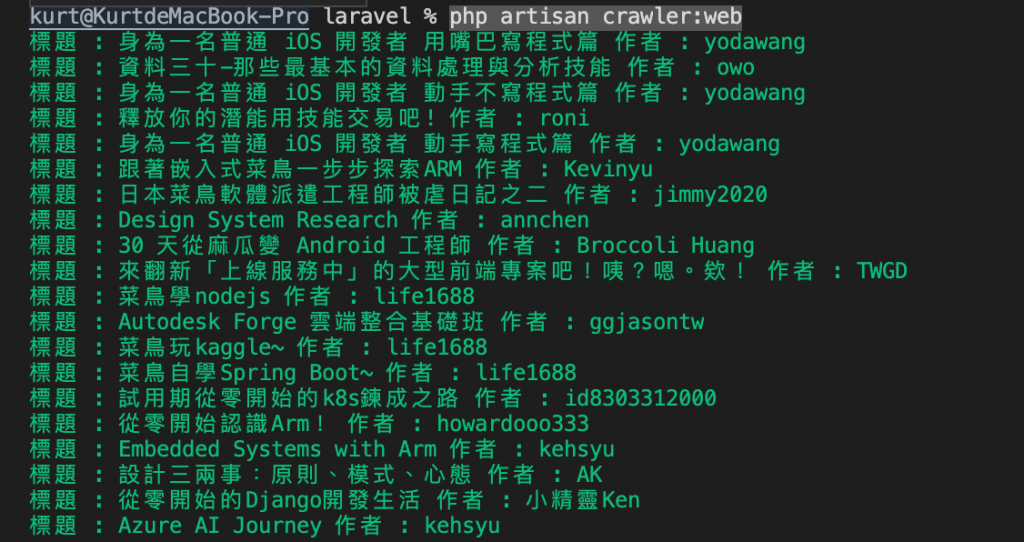
this->info()这个 function 可以字串直接输出在terminal上,还有line、comment、question、warn、error等用法,详细可至官方网站查看文件。
sleep(1)代表每捞取一页的资料会暂停一秒钟,避免同时间太多request打向server,有可能会因次被认为是DDOS而被封锁。
今天的project算是爬虫的入门,至少可以爬取一些完全没有防档的页面,後续还会有进阶的前置验证、动态页面无法爬取等困难点,有兴趣可以再自行深入研究。
今天的介绍就到这边结束了,希望可以赶快结束强力过敏头昏脑胀的今天,谢谢观看的各位,请记得按赞分享开启小铃铛,你的支持会让按赞数+1。
<<: 【Day 16】Function - Practice 2
[Day 23] 撰写我们的第一个 test double
回到我们的目标 我们希望能测试 updateUsersTags(),传入参数 filter时,会执行...
【在厨房想30天的演算法】Day 30 资讯安全与演算法 : 数位凭证
Aloha!我是少女人妻 Uerica!终於来到最後一天了!如果生命只剩一天,我想我会拿来学资料结构...
cmd 指令
记录一些常用指令 dir 查看目前目录 md 建立资料夹/档案 rd 删除资料夹/档案 cd 移动位...
第33天~还原资料库
这个的上一篇:https://ithelp.ithome.com.tw/articles/10283...