【14】如果不做图片标准化(Normalization)会怎麽样
图片标准化 Image Normalization 不做可以吗?小实验实测差别
一般我们在处理大部分的机器学习问题时,我们都会将输入的资料特徵做 Normalization,将范围缩小到0的附近後在进行训练,而这个再丢给模型推论之前所做动作称之为资料预处理,而预处理的方式又有很多种,像是减去平均值除上标准差等方式。
通常大家在学习上听到的预处理是为了让模型收敛速度加快,而我们今天就来做个小实验比较看看这两者的差别。
实验一:有做 Normalization
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return image / 255., label. # Normalization 到 [0,+1]
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 3.6706e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.4833 - val_sparse_categorical_accuracy: 0.8647
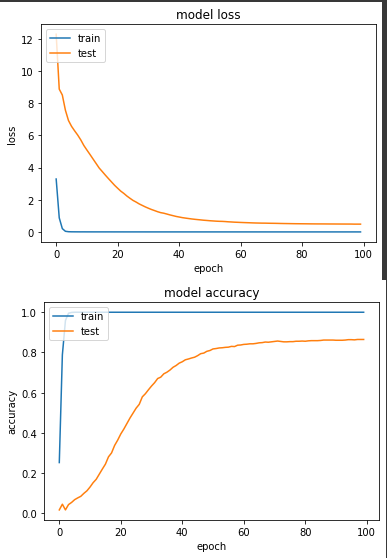
loss值落在 0.4833,准确度落在86.5%
实验二:不做 Normalization,使用原图片输入数值范围 [0, 255]。
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return image, label # 不除255.
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 3.7623e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.4478 - val_sparse_categorical_accuracy: 0.8873
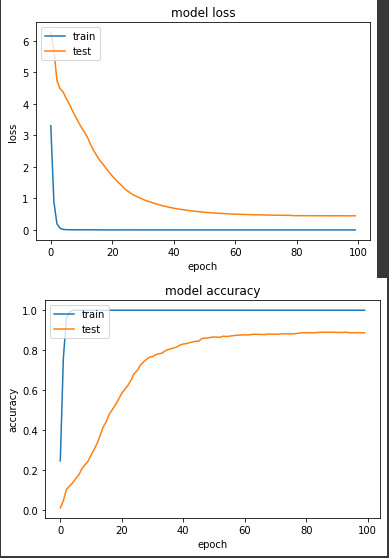
结果有些出乎我意料,loss 值0.4478,准确度88.7%,整体结果比实验一好,而且实验一在第50个 epoch 达到80%准确度,但实验二更快,在第36个 epoch 就到达了80%,实验一并没有收敛比较快。
虽然这次实验结果是不做 Normalization 的成绩好一些,但我还是不太建议略过 Normalization ,之所以会有这样的结果,我猜想可能是我的模型用了 Batch Normalization 来解决数值的差异,如果数值的差异很大的话,其实蛮容易训练到一半时,loss变成nan 的状况(gradient exploding),有关这种状况,後面我会再独立介绍。
<<: [Day28] CH13:画出你的藏宝图——事件处理(上)
Google Static Map Maker 静态地图 API 工具|专案实作
Google Static Map API 是将网页上需要的地图画面,以静态地图图片的方式显示。 优...
Week37 -我当时害怕极了,原来Golang用指标是母汤的 [Server的终局之战系列]
大家好,在这个周末我参加了Golang-Conference-2020,每个议程养分都很高,而在最後...
如何让网路社团的发文得到较好的转换效果
透过网路社团发文做行销,因为几乎等於零成本,所以一直都是很热门的行销管道,但要得到好的发文转换效果,...
第三天 Routes 与 MVC
呈前一天的问题!昨日的答案是因为我们有在 yml 档设定 production 的环境要使用 pgs...