[Day 15] Facial Recognition - Eigenfaces
有兴趣知道特徵脸方法 (Eigenfaces)的基本原理 - 主成分分析 (PCA),推荐你看看这篇生动也有趣的介绍
本文开始
使用特徵脸方法 (Eigenfaces)来做人脸辨识实际上是:
- 进行人脸侦测并且将人脸部分取出 (这个在前面讲很多了)
- 将人脸以像素为单位,摊平转成一个一维阵列 (例:[1, 2, 3, 5, 8, 13]就是一维阵列)
- 将所有一维阵列的人脸放在一起,找出最能代表人脸的特徵 (也就是主成分分析方法)
- 将这些特徵用,得到特徵脸资料库
- 实际辨识时,拿测试图片与特徵运算完的特徵脸,与前一步得到的特徵脸资料库比对,找出最相似的图片
用文字说明,不如实际操作。
- 在Day9的专案下,新增一个目录
face_recognition与dataset,分别用来存放人脸辨识的程序码与资料集 - 在PyCharm中安装下列套件:
- scikit-image (版本:0.18.3)
- scikit-learn (版本:1.0rc2)
- 安装完後你的
pip freeze应该跟我一样:
cmake==3.21.2
cycler==0.10.0
dlib==19.22.1
imageio==2.9.0
imutils==0.5.4
joblib==1.0.1
kiwisolver==1.3.2
matplotlib==3.4.3
networkx==2.6.3
numpy==1.21.2
opencv-contrib-python==4.5.3.56
Pillow==8.3.2
pyparsing==2.4.7
python-dateutil==2.8.2
PyWavelets==1.1.1
scikit-image==0.18.3
scikit-learn==0.24.2
scipy==1.7.1
six==1.16.0
threadpoolctl==2.2.0
-
资料集部分我们使用加州理工学院提供的人脸测试资料集。从这里下载CALTECH脸部资料集;解压缩後,里面是450张不同人的正面照
-
这450张图片请依照下面的顺序依次建立子资料夹并分类 (资料夹名称只是用做识别,你可以改成喜欢的名称):
- man_1:image_0001.jpg ~ image_0021.jpg - man_2:image_0022.jpg ~ image_0041.jpg - man_3:image_0042.jpg ~ image_0046.jpg - man_4:image_0047.jpg ~ image_0068.jpg - woman_1:image_0069.jpg ~ image_0089.jpg - man_5:image_0090.jpg ~ image_0112.jpg - woman_2:image_0113.jpg ~ image_0132.jpg - man_6:image_0133.jpg ~ image_0137.jpg - man_7:image_0138.jpg ~ image_0158.jpg - man_8:image_0159.jpg ~ image_0165.jpg - woman_3:image_0166.jpg ~ image_0170.jpg - woman_4:image_0171.jpg ~ image_0175.jpg - woman_5:image_0176.jpg ~ image_0195.jpg - man_9:image_0196.jpg ~ image_0216.jpg - man_10:image_0217.jpg ~ image_0241.jpg - man_11:image_0242.jpg ~ image_0263.jpg - man_12:image_0264.jpg ~ image_0268.jpg - woman_6:image_0269.jpg ~ image_0287.jpg - man_13:image_0288.jpg ~ image_0307.jpg - man_14:image_0308.jpg ~ image_0336.jpg - woman_7:image_0337.jpg ~ image_0356.jpg - woman_8:image_0357.jpg ~ image_0376.jpg - man_15:image_0377.jpg ~ image_0398.jpg - man_16:image_0404.jpg ~ image_0408.jpg - woman_9:image_0409.jpg ~ image_0428.jpg - woman_10:image_0429.jpg ~ image_0450.jpg特别注意: 照片中399 ~ 403由於样本数太少或是非一般照片照,所以排除在我们这次的资料集之外;请将这些照片与非jpg格式的档案都删除。
-
将整理好的资料集放到专案目录下的
dataset目录下。这时你的专案结构应该会长这样:
-
首先我们需要先撰写将资料集载入的程序码。在
dataset目录下新建一个档案load_dataset.py,并新增下面的程序码:# 汇入必要套件 import ntpath import os import pickle from itertools import groupby import cv2 import numpy as np from imutils import paths # 汇入人脸侦测方法 (你可以依据喜好更换不同方法) from face_detection.opencv_dnns import detect def images_to_faces(input_path): """ 将资料集内的照片依序撷取人脸後,转成灰阶图片,回传後续可以用作训练的资料 :return: (faces, labels) """ # 判断是否需要重新载入资料 data_file = ntpath.sep.join([ntpath.dirname(ntpath.abspath(__file__)), "faces.pickle"]) if os.path.exists(data_file): with open(data_file, "rb") as f: (faces, labels) = pickle.load(f) return (faces, labels) # 载入所有图片 image_paths = list(paths.list_images(input_path)) # 将图片属於"哪一个人"的名称取出 (如:man_1, man_2,...),并以此名称将图片分群 groups = groupby(image_paths, key=lambda path: ntpath.normpath(path).split(os.path.sep)[-2]) # 初始化结果 (faces, labels) faces = [] labels = [] # loop我们分群好的图片 for name, group_image_paths in groups: group_image_paths = list(group_image_paths) # 如果样本图片数小於15张,则不考虑使用该人的图片 (因为会造成辨识结果误差);可以尝试将下面两行注解看准确度的差异 if (len(group_image_paths)) < 15: continue for imagePath in group_image_paths: # 将图片依序载入,取得人脸矩形框 img = cv2.imread(imagePath) rects = detect(img) # loop各矩形框 for rect in rects: (x, y, w, h) = rect["box"] # 取得人脸ROI (注意在用阵列操作时,顺序是 (rows, columns) => 也就是(y, x) ) roi = img[y:y + h, x:x + w] # 将人脸的大小都转成50 x 50的图片 roi = cv2.resize(roi, (50, 50)) # 转成灰阶 roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY) # 更新结果 faces.append(roi) labels.append(name) # 将结果转成numpy array,方便後续进行训练 faces = np.array(faces) labels = np.array(labels) with open(data_file, "wb") as f: pickle.dump((faces, labels), f) return (faces, labels) -
接下来到
face_recognition目录下新增eigenfaces.py档案:import ntpath import sys # resolve module import error in PyCharm sys.path.append(ntpath.dirname(ntpath.dirname(ntpath.abspath(__file__)))) # 汇入必要套件 import argparse import os import pickle import time import cv2 import imutils import numpy as np from imutils import build_montages from matplotlib import pyplot as plt from skimage.exposure import rescale_intensity from sklearn.decomposition import PCA from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn.svm import SVC from dataset.load_dataset import images_to_faces def main(): # 初始化arguments ap = argparse.ArgumentParser() ap.add_argument("-i", "--input", type=str, required=True, help="the input dataset path") ap.add_argument("-n", "--components", type=int, default=25, help="number of components") args = vars(ap.parse_args()) data_file = ntpath.sep.join([ntpath.dirname(ntpath.dirname(ntpath.abspath(__file__))), args["input"], "data.pickle"]) print("[INFO] loading dataset....") if not os.path.exists(data_file): (faces, labels) = images_to_faces(args["input"]) with open(data_file, "wb") as f: pickle.dump((faces, labels), f) else: with open(data_file, "rb") as f: (faces, labels) = pickle.load(f) print(f"[INFO] {len(faces)} images in dataset") # 进行主成分分析时需要将资料转成一维阵列 pca_faces = np.array([face.flatten() for face in faces]) # 将名称从字串转成整数 (在做训练时时常会用到这个方法:label encoding) le = LabelEncoder() labels = le.fit_transform(labels) # 将资料拆分训练用与测试用;测试资料占总资料1/4 (方便後续我们判断这个方法的准确率) split = train_test_split(faces, pca_faces, labels, test_size=0.25, stratify=labels, random_state=9527) (oriTrain, oriTest, trainX, testX, trainY, testY) = split print("[INFO] creating eigenfaces...") pca = PCA(svd_solver="randomized", n_components=args["components"], whiten=True) start = time.time() pca_trainX = pca.fit_transform(trainX) end = time.time() print(f"[INFO] computing eigenfaces for {round(end - start, 2)} seconds") # 确认使用的主成分可以解释多少资料的变异 cum_ratio = np.cumsum(pca.explained_variance_ratio_) plt.plot(cum_ratio) plt.xlabel("number of components") plt.ylabel("cumulative explained variance") plt.draw() plt.waitforbuttonpress(0) # 来用"图像"看一下PCA的结果 vis_images = [] for (i, component) in enumerate(pca.components_): component = component.reshape((50, 50)) component = rescale_intensity(component, out_range=(0, 255)) component = np.dstack([component.astype("uint8")] * 3) vis_images.append(component) montage = build_montages(vis_images, (50, 50), (5, 5))[0] montage = imutils.resize(montage, width=250) mean = pca.mean_.reshape((50, 50)) mean = rescale_intensity(mean, out_range=(0, 255)).astype("uint8") mean = imutils.resize(mean, width=250) cv2.imshow("Mean", mean) cv2.imshow("Components", montage) cv2.waitKey(0) # 建立SVM模型来训练 model = SVC(kernel="rbf", C=10.0, gamma=0.001, random_state=9527) model.fit(pca_trainX, trainY) # 验证模型的准确度 (记得将测试资料转成PCA的格式) pca_testX = pca.transform(testX) predictions = model.predict(pca_testX) print(classification_report(testY, predictions, target_names=le.classes_)) # Optional: 你也可以直接用OpenCV内建的模型来训练;下面的程序码可以取代前面的SVM模型训练 # recognizer = cv2.face_EigenFaceRecognizer().create(num_components=args["components"]) # recognizer.train(trainX, trainY) # predictions = [] # for i in range(0, len(testX)): # (prediction, _) = recognizer.predict(testX[i]) # predictions.append(prediction) # print(classification_report(testY, predictions, target_names=le.classes_)) # 随机挑选测试资料来看结果 idxs = np.random.choice(range(0, len(testY)), size=10, replace=False) for i in idxs: predName = le.inverse_transform([predictions[i]])[0] actualName = le.classes_[testY[i]] face = np.dstack([oriTest[i]] * 3) face = imutils.resize(face, width=250) cv2.putText(face, f"pred:{predName}", (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2) cv2.putText(face, f"actual:{actualName}", (5, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2) print(f"[INFO] prediction: {predName}, actual: {actualName}") cv2.imshow("Face", face) cv2.waitKey(0) plt.close() if __name__ == '__main__': main() -
都完成後,请在terminal内输入
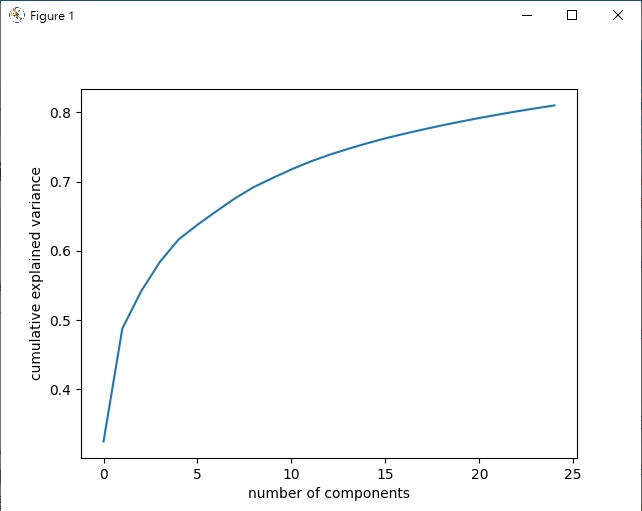
python face_recognition/eigenfaces.py -i dataset/caltech_faces就可以测试程序看看结果了!前25个主成分累积变异值
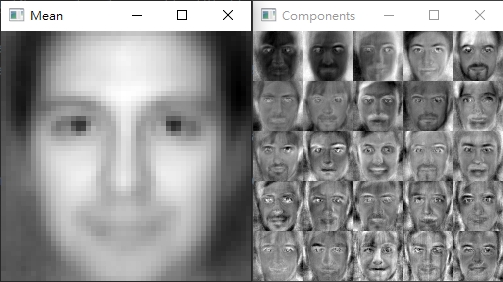
PCA结果图像化的样子
辨识结果错误的例子
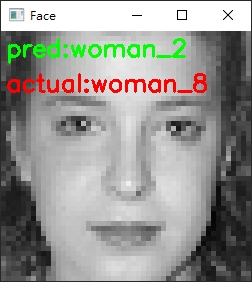
辨识结果正确的例子

这一篇文章的内容比较多,程序码的部分也比较复杂,因此在实作的过程可以参考下面一节的结论一起观看。
结论
- 在进行资料集的整理 (建立名称目录、分类、去除不需要的图片与档案等)实际上是在进行资料分析时最花时间却也最重要的第一个步骤,同时也会影响最终准确度的高低
- 在进行
特徵脸方法时,需要将图片都转为灰阶 -> 确认值的范围都相同 -> 转成一维阵列 - 在
eigenfaces.py程序码的第53-58行,我们实际用累积图来看到PCA方法的主成分前25个已经可以表达原始资料的80%左右 (我们图像实际上是50 * 50 = 2500个数值的阵列)- 你也可以透过改变输入参数
-n来看看不一样数量的主成分辨识结果有什麽不同
- 你也可以透过改变输入参数
- 在
eigenfaces.py程序码的第60 - 76行,我们用图像实际来看PCA前25个主成分用画面看是什麽感觉;这里你可以看到平均值Mean的图像看起来就像一个"模板型的人脸",而各主成分Components中,颜色越白的代表在真实图片中,变异性越大;可以看出大部分在眼睛、眉毛、鼻子、嘴唇部分比较没有太大的变化 - 在最後预测的准确度大约在85%左右,主要原因在於使用的人脸侦测方法不是最佳、样本数过少的资料也被用作训练、以及PCA方法中的components值较低;调整这些参数後可以将准确率拉至**97%**左右
- 人脸侦测模型可以参考Day13的结论来选择适合的模型
- 还有一个重要的点,使用
特徵脸方法来辨识脸部,会需要图片尽可能都是正面照;因为我们在处理图片时,都需要将其转成一维阵列,其实这正代表者即使脸部有些微转动或是非正面脸,都会使得後面在透过SVM模型训练时准确度大幅下降
使用特徵脸方法大概是最直觉也很简单的人脸识别方法了,主要使用的方法主成分分析(PCA)在应用上也不局限於图像而已 (还没看过这篇介绍的建议看一下)
就这样,接着我们明天会介绍在特徵脸方法後,稍微强一点的人脸识别 - 局部二值方法
程序码传送门
Day11 - 在 Next.js 中使用 CSR - feat. useSWR
为什麽我们需要 SWR ? 先前我们已经了解了 CSR、SSR 与 SSG 的优劣,SSR 与 SS...
如何制作一个精美的网站
什麽是好的网站设计? 使用者使用网站时是否容易操作及有良好的动线,避免过多不必要的元素,让使用者快速...
第一天:为什麽该学好 Gradle?
开始接触 Gradle 的原因 身为一位 Kotlin 开发者,每天需要接触的就是 JVM 生态系的...
Day30 vue.js docker部署
延续昨日 今天的要做是把东西布署在docker(就不解释docker罗) 首先要先创一个docker...
[前端暴龙机,Vue2.x 进化 Vue3 ] Day1.在认识vue之前(一)
[讲古时间]: 回忆过去~ 痛苦的相思忘不了~ 哈哈,记得刚出社会时,虽然说是张白纸,不过可能太白...