Day26 我有权保持沉默?
- Development log - Pivot
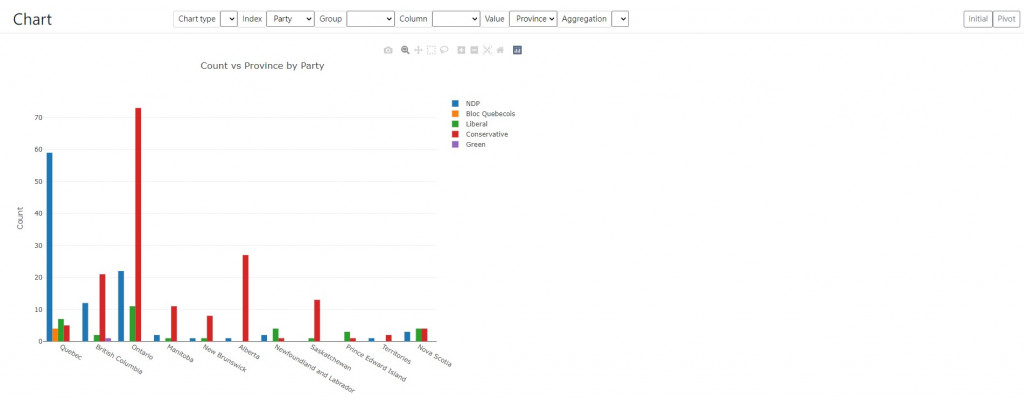
承袭昨天说到,我们现在策略是把产生图表(这部分比较适合建data)挖出来,然後再把需要的或呼叫到的拚上去。今天有初步成果了:
好。谢谢大家。明天请继续收看。
不行,有字数限制,让我们继续讲下去。目前row和column只能各选一个,aggregation只有先刻一个count,然後先用plotly.js画图。这三部分难度尚可,也都是需要时间再整理。而且主要如之前所提还是在aggregation function的部分,这部分做了枢纽的资料处理功能,其他都是格式和控制处理。
虽然只是初步成果,但总算跨出了一步,连日一直在心路历程和自我对话(虽然今天还是有一半篇幅),信心确实颇受打击(does it depress you? To know just how alone you really are?),而今天的一小步,着实鼓舞了我,转眼间剩4天,期待有个happy ending。
I will climb out of the hell, one inch at a time.
>>: [神经机器翻译理论与实作] Google Translate的神奇武器- Seq2Seq (I)
#8 Button Ripple Effect(原生JS版)、#5. Q&A Section(Vue版)
Button Ripple Effect(原生JS版) CodePen Link: https://...
Best Digital Marketing Company | Immortal Business
Do you want to learn digital marketing? Digital Ma...
【第二六天 - Flutter 知名外送平台画面练习(中)】
前言 接续上一篇 【第二五天 - Flutter 知名外送平台画面练习(上)】~~。 今日的程序码 ...
DAY6-EXCEL统计分析:计算连续型机率
上次学会了有关离散型的机率生活题 今天来说有关连续型的机率生活应用 NORMAL DISTRIBUT...
透过Mac终端机 使用MySQL
透过Mac终端机 登入MySQL cd /usr/local/mysql cd bin pwd ./...