Day.19 认识索引 - 二级索引 (Secondary Index)
InnoDB将索引分成Cluster Index & Secondary Index,认识前面的主索引(PK)後,今天来看当我们建表时自己建立的index又是如何执行的~
前面提到Cluster Index只能有一个,因为资料表纪录的排序方式会根据设定的Cluster Index排序分布,而Secondary Index(我们自己建立的栏位index),根据需求建立不会只能有一个(1~N个)~
ps.为何这边都会写Cluster Index(PK) -> 个人觉得比较好辨识,因为一般来说我们建表时都会顺便把Primary key订好,可以说PK基本上就是Cluster Index。
当然这是有设定的状态,没设表PK参考前一天了解主索引架构中知道Cluster Index是如何选择的~
- 常见问题
Q: 因为建立index能提高查询资料的速度,是不是多建一点在各个栏位就好?
A: 当然不行
前面有提到索引是占空间的,虽然合适的index能提升查询速度,但相反的会降低表数据更新速度。
因为当你建立了一组index等於另外生成一个Secondary Index结构,当有异动到相关的表数据时,需同时更新索引。
建立一个合适的index时需同时考虑到栏位重复值高低及如何搭配栏位去达到更佳的查询效果等等...,当然日後使用频率也是一大重点。
-
非聚集索引 Secondary Index (二级索引) 是什麽?

-
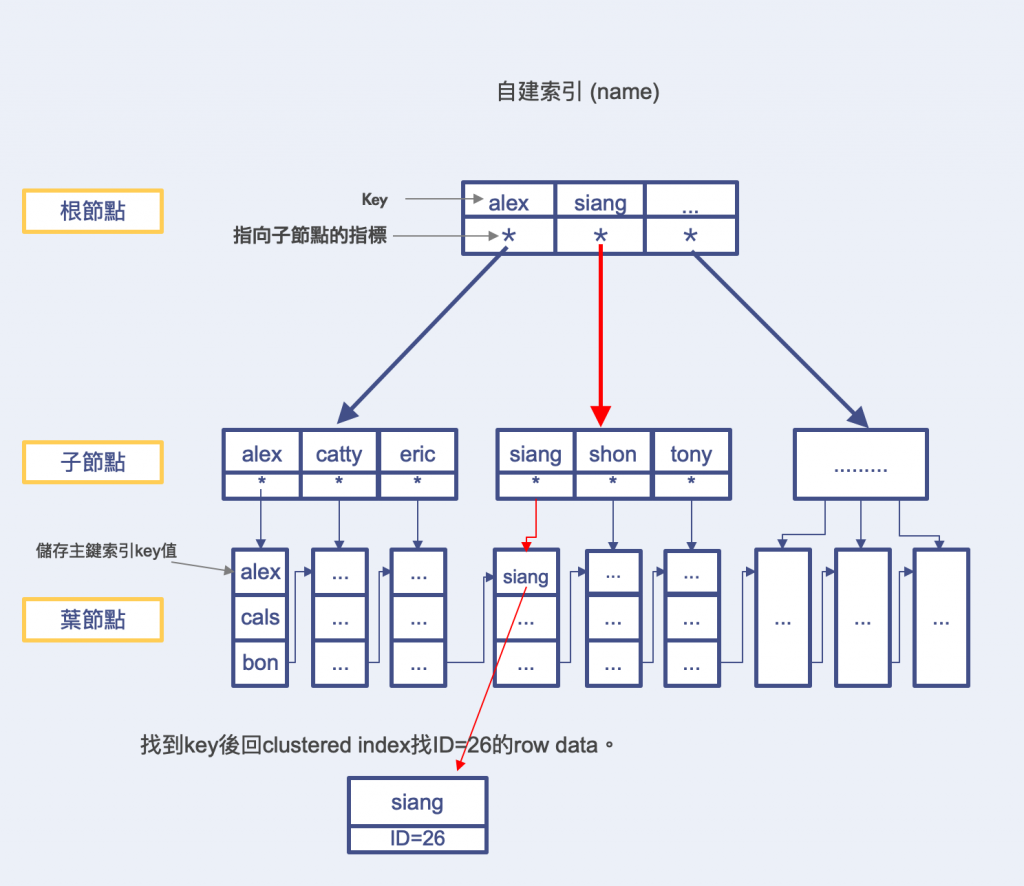
一样采用B+Tree来作为组织结构,但不同的是Secondary Index的叶节点内容存放的不是主键值的对应资料,而是储存key和clustered key(PK)值,找到後再去clustered index找资料行数据。
ps. 建立Secondary Index不会重新组织主索引结构喔~ -
在范围查询时存取row data时不一定是循序读。
-
-
简单流程
ex. 建立index(name) -> 查询name=siang的纪录
(先) 从Secondary Index找到资料对应的主键。
(後) 回Cluster Index根据主键找到具体数据行。
假设有以下资料表user的结构&索引 primary key (id) / secondary index (name)
| id | name | status | account |
|---|---|---|---|
| 1 | shawn | 1 | xxxxxx |
| ... | ... | ... | ... |
| 26 | siang | 1 | a1234 |
ex. 要找siang这笔资料的所有栏位纪录~
select * from user where name = 'siang';
覆盖索引
上面可以看到我们要查找id= 26,name= siang的所有数据行,需要进行二次查询回clustered index找。
那如果要查询的栏位资料只要从secondary index就能取得,则会直接从secondary index的leaf node取值返回数据内容,称为覆盖索引。
Example table: user
-资料准备-
CREATE TABLE `user` (
`id` bigint(20) NOT NULL,
`name` varchar(100) DEFAULT NULL,
`account` varchar(50) NOT NULL,
`Status` tinyint(5) NOT NULL,
PRIMARY KEY (`id`), -> (clustered index)
KEY `name` (`name`) -> (secondary index)
)
insert into user (id,name,account,status) values(1,'shawn','qq111',1),(2,'eric','w11zx',2),(3,'edwin','x12a1',2),(4,'shen','v2111',2),(5,'siang','a1234',1);
mysql> select * from user;
+----+-------+---------+--------+
| id | name | account | Status |
+----+-------+---------+--------+
| 1 | shawn | qq111 | 1 |
| 2 | eric | w11zx | 2 |
| 3 | edwin | x12a1 | 2 |
| 4 | shen | v2111 | 2 |
| 5 | siang | a1234 | 1 |
+----+-------+---------+--------+
5 rows in set (0.00 sec)
看一下查询语法分析explain:
PS. 查询SQL前只要加上explain能帮助你了解这句SQL使用到什麽索引等相关帮助SQL优化的资讯!!
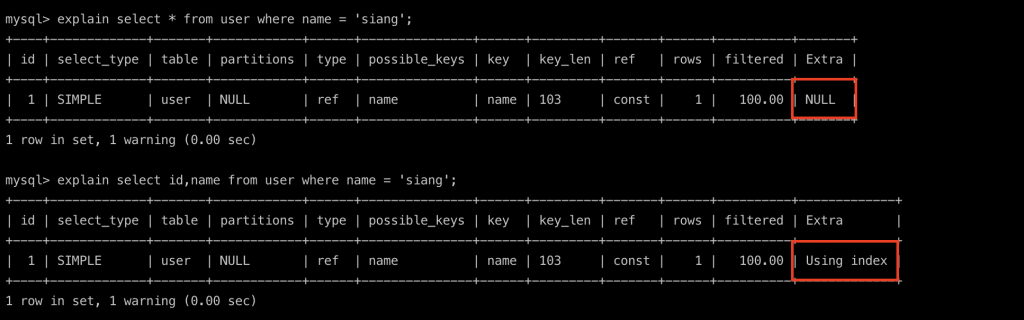
当查找id,name时,因为secondary index就有资讯能返回(Using index),不必在回clustered index找其他栏位内容。
了解这些基础索引知识後,能帮助日後建表时提供一些方向。
不过合适的index的建立与优化又是另一个课题了~
>>: Clean architecture in Android
Day.18 Graph-BFS
BFS是简写,全名是Breadth-First Search(广度优先搜寻演算法) BFS跟DFS一...
後端说修改时只需要送「有修改的栏位」过来
今天来介绍一个,因为後端提出这个需求。要接 PATCH API 而产生的做法。 如果都是 PUT 就...
Day-23 AVL Tree
树的高度(height of the tree) 在Binary Search tree中,我们知道...
[ Day 20 ] - AJAX
AJAX 是什麽? AJAX 全名是 Asynchronous JavaScript And XML...
[Day03] TS:泛型就。很。泛!用 extends 来加上一点限制吧!
昨天我们提到了泛型(generics)的使用,但泛型就像一个型别为 any 的变数一样,使用者爱带什...