【12】新手容易忽略的 logit 与 loss 之间的搭配
通常在 model.compile() 时,我们要指定这个训练应该要使用哪种 loss 来计算,前面几天我们比较了各种 cross entropy 的使用方式,今天我们来讲一下模型训练新手容易忽略的 from_logits 。
什麽是 logits ?
根据维基百科,logit 在数学上是一个将0~100%映射到负无限大到正无限大的函示,举例来说,50%就是代表0,不到50%在 logit 上都是负的,可以到负无限大,50%以上的 logit 范围就是大於0到无限大。
而我们再计算 loss 值时,label 通常都是0与1,我们必须经过 sigmoid 或 softmax 将 logit 的范围缩到同样也是0和1之间,这麽一来计算出的 loss 才有意义,所以一般我们会把在最後经过 softmax 或 sigmoid 的前一个 tensor 称作 logit。
tf.keras.losses.* 系列提供的 API 中,很多都提供了 from_logits 这个参数让你直接接 logit 层,预设 from_logits=False,我们来看看使用 from_logits=False 来训练的结果。
实验一:在oxford_flowers102用 softmax 跑 SparseCategoricalCrossentropy
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
net = tf.keras.layers.Softmax()(net) # from_logits=False时,多加这一层
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 0.0056 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.6840 - val_sparse_categorical_accuracy: 0.8608
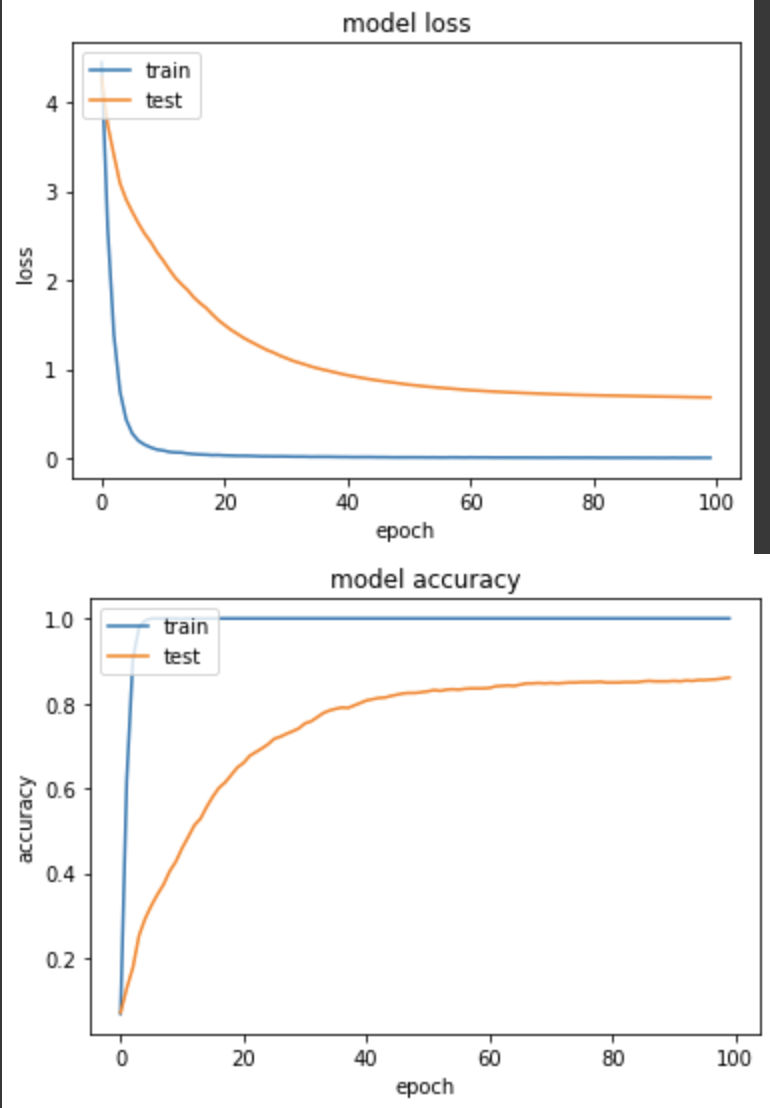
没什麽问题,和day10的实验一结果差不多。
实验二,错误示范,忘记加 softmax
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
# net = tf.keras.layers.Softmax()(net) # from_logits=False,忘记多加这一层
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=10,
validation_data=ds_test,
verbose=True)
产出:
loss: 5.4419 - sparse_categorical_accuracy: 0.0098 - val_loss: 6.3155 - val_sparse_categorical_accuracy: 0.0098
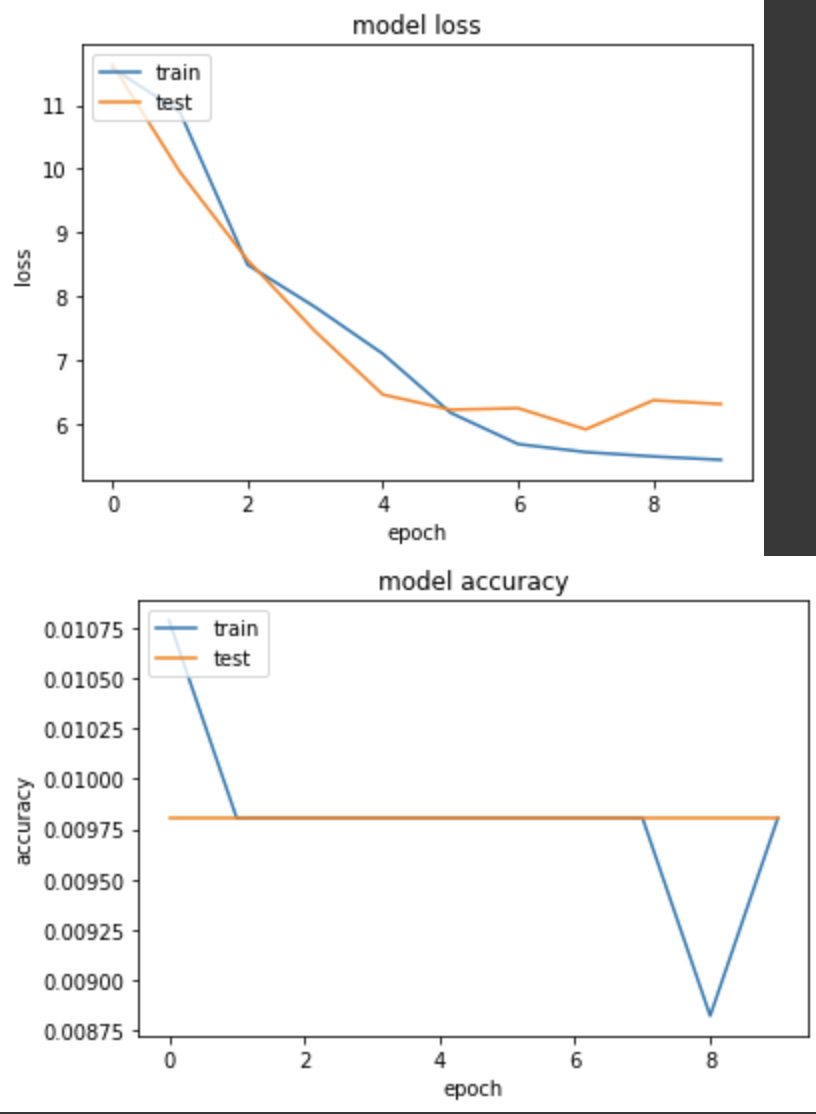
实验三,在cats_vs_dogs用 sigmod 跑 BinaryCrossentropy
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(1)(net) # dense node = 1
net = tf.keras.activations.sigmoid(net) # from_logits=False时,多加这一层
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.BinaryAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 0.0051 - binary_accuracy: 0.9986 - val_loss: 0.0327 - val_binary_accuracy: 0.9895
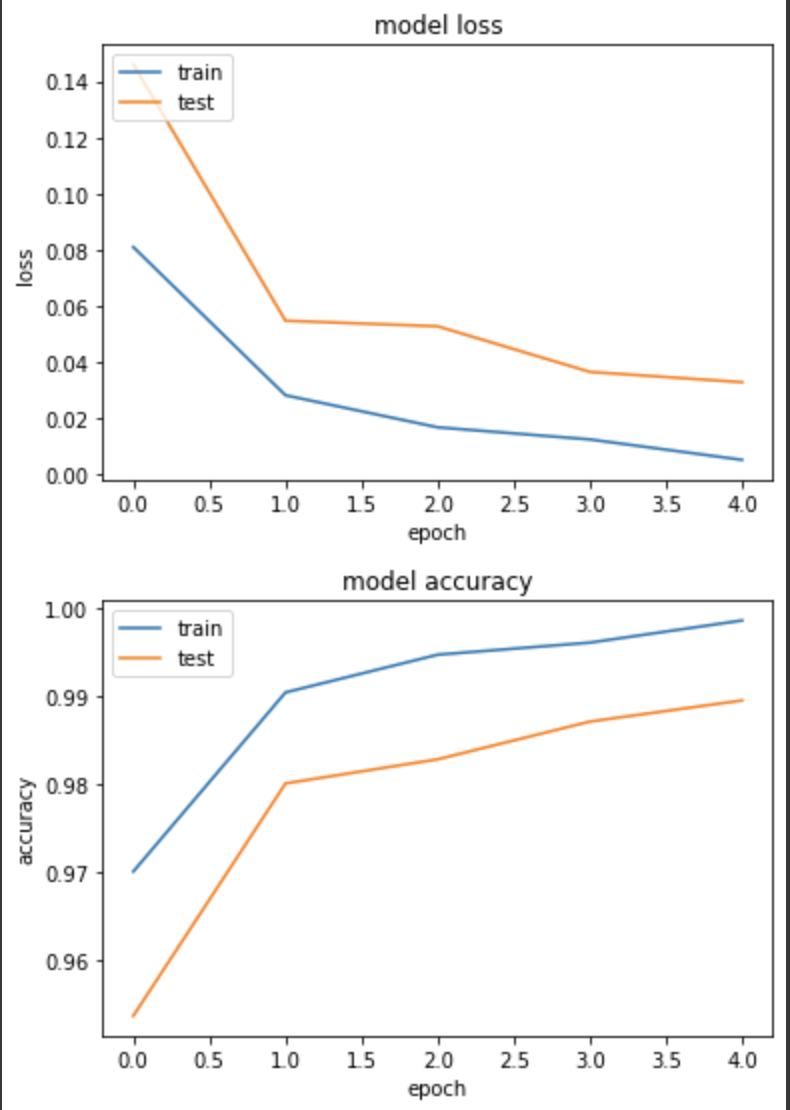
和day11的实验二差不多,准确度都高达98.9%
实验四:错误示范,忘记加 sigmoid
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(1)(net) # dense node = 1
# net = tf.keras.activations.sigmoid(net) # from_logits=False时,忘记加这一层
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.BinaryAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 7.6577 - binary_accuracy: 0.5036 - val_loss: 7.0626 - val_binary_accuracy: 0.5156
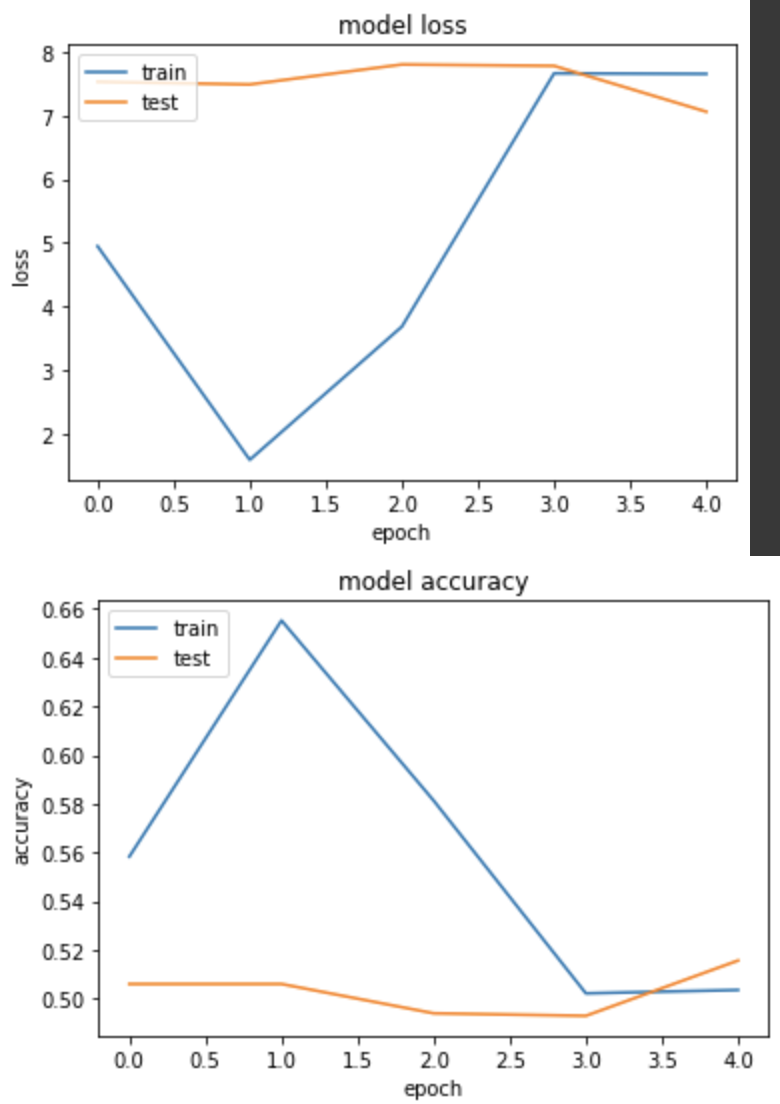
以上结果,可以得知在计算 loss 值时,如果不透过 softmax 或 sigmoid 将 logit 缩限范围会导致与 label 的值计算错误,从而让模型学不到东西,因此在建构模型时,请务必检查这个地方是否有遗漏!
<<: Day11 - 在 Next.js 中使用 CSR - feat. useSWR
>>: Day 12:145. Binary Tree Postorder Traversal
Day 23: 元件原则 — 耦合性 (待改进中... )
「本章描述的依赖性管理度量,可以用来量测一个设计有多符合『好的依赖及抽象』模式。经验告诉我们,依赖...
成员 3 人:别让人落单,就成功一半
「三是一个质数,是一个特别的存在。」 「三角形是最坚固的形状,最强韧的组合。」 三个人的团队,是最适...
AI ninja project [day 13] 回归
这应该也是学习深度学习时的基础课程, 不确定跟图像分类比,哪一个会先学到, 但是在接触深度学习框架时...
[DAY-13] 走向全球
有效沟通 要先了解彼此文化 才能有效沟通 Google 有强烈的企业文化自豪 Google 把心思放...
[13th][Day15] dockerfile 指令
第一个 dockerfile 中已经用过几个指令了 RUN EXPOSE 接下来会遇到的还有 CMD...