AI ninja project [day 13] 回归
这应该也是学习深度学习时的基础课程,
不确定跟图像分类比,哪一个会先学到,
但是在接触深度学习框架时,你应该是碰过回归分析预设的问题了。
参考页面:https://www.tensorflow.org/tutorials/keras/regression?hl=zh_tw
首先是引入模组:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.layers.experimental import preprocessing
读取资料集,
这里可以发现用pandas很神奇的读取了一个url,
而该url直接下载的话,为一个csv,
- MPG:miles per gallon,每加仑可以跑多少英里,为我们要预测的目标
- Cylinders:汽油缸
- Displacement:排气量
- Origin :来源为1、2、3的数值,代表来自美国、欧洲、日本
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(url, names=column_names,
na_values='?', comment='\t',
sep=' ', skipinitialspace=True)
我们可以查看有没有缺失的数值:
dataset = raw_dataset.copy()
print(dataset.isna().sum())
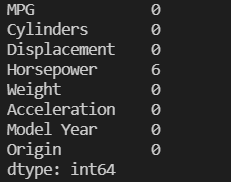
可以发现,马力的栏位有六笔缺失,
我们丢弃有缺失的资料:
dataset = dataset.dropna()
将Origin栏位转化为one-hot-encoding格式:
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, columns=['Origin'], prefix='', prefix_sep='')
print(dataset.tail())

切分训练集及测试集:
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
我们可以做图查看其他特徵与燃油效率(MPG)的关系:
sns.pairplot(train_dataset[['MPG', 'Cylinders', 'Displacement', 'Weight']], diag_kind='kde')
plt.show()

可以发现MPG与Displacement及Weight呈现反比。
将MPG设定成要预测的label:
train_features = train_dataset.copy()
test_features = test_dataset.copy()
train_labels = train_features.pop('MPG')
test_labels = test_features.pop('MPG')
再来,我们想先以单一特徵 马力(Horsepower) 来预测 MPG ,
我们先将 马力(Horsepower) 进行Normalization前处理,
- (input - mean) / sqrt(var) :(特徵值- 该特徵平均值) 除以 特徵变异数开根号
horsepower = np.array(train_features['Horsepower'])
horsepower_normalizer = preprocessing.Normalization(input_shape=[1,], axis=None)
horsepower_normalizer.adapt(horsepower)
搭建model, layers.Dense(units=1)为输出的预测(指预测MPG一个数值),设定好优化器及损失函数:
horsepower_model = tf.keras.Sequential([
horsepower_normalizer,
layers.Dense(units=1)
])
horsepower_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
进行训练:
history = horsepower_model.fit(
train_features['Horsepower'], train_labels,
epochs=100,
# suppress logging
verbose=0,
# Calculate validation results on 20% of the training data
validation_split = 0.2)
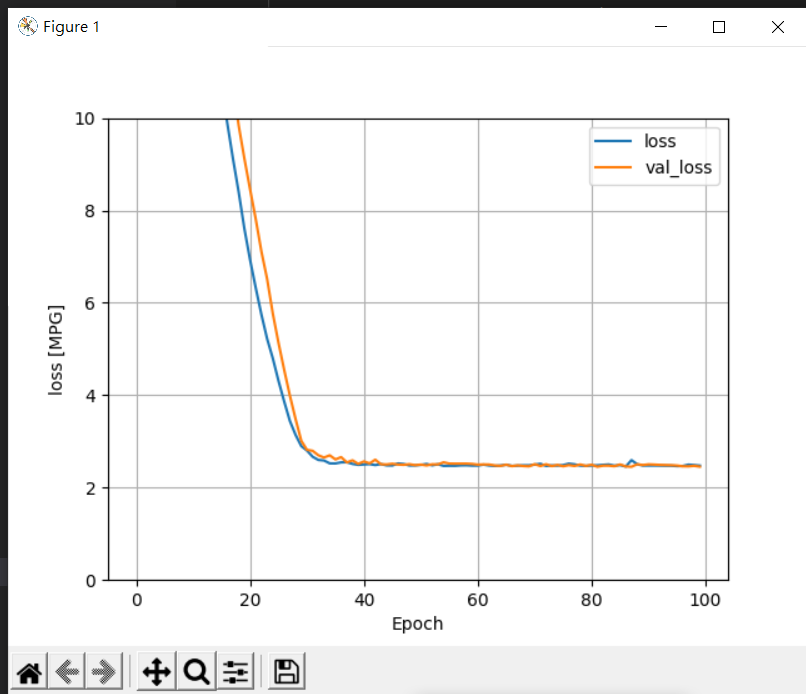
将损失函数作图,看犯的错误是不是越来越少:
def plot_loss(history):
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.ylim([0, 10])
plt.xlabel('Epoch')
plt.ylabel('Error [MPG]')
plt.legend()
plt.grid(True)
plt.show()

再来我们想将所有特徵都拿来进行预测,
先进行前处理
normalizer = preprocessing.Normalization(axis=-1)
normalizer.adapt(np.array(train_features))
# 在进行文字向量化、Normalization、CategoryEncoding等等前处理时,记得先call adapt这个方法
# 否则损失函数降不下来
# 参考资料: https://www.tensorflow.org/guide/keras/preprocessing_layers
建立model:
linear_model = tf.keras.Sequential([
normalizer,
layers.Dense(units=1)
])
linear_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
训练及作图
history = linear_model.fit(
train_features, train_labels,
epochs=100,
# suppress logging
verbose=0,
# Calculate validation results on 20% of the training data
validation_split = 0.2)
plot_loss(history)
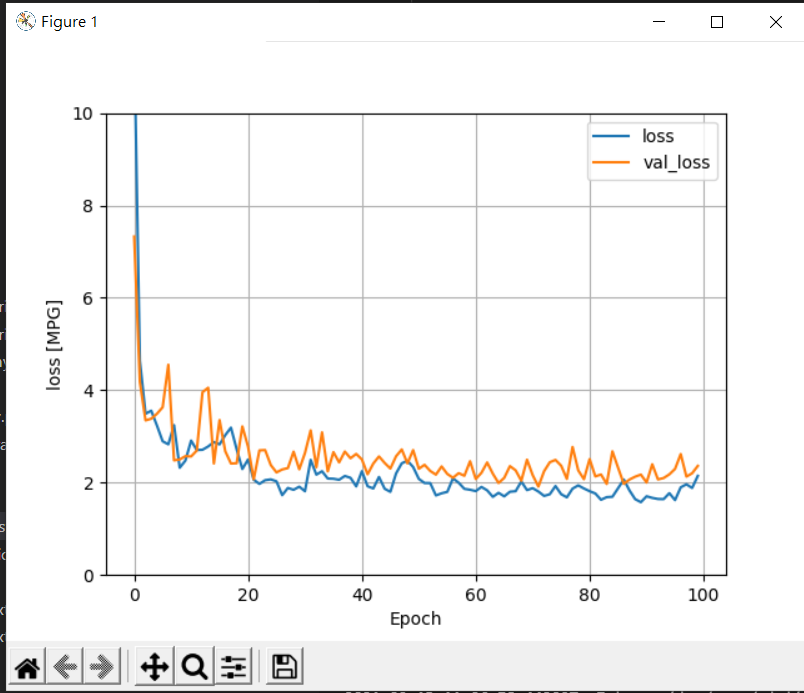
那我们也可以自行修改model layers的铺设:
linear_model = tf.keras.Sequential([
normalizer,
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(units=1)
])
察看结果:
<<: 第13天 - (配第11天) 修改MySQL资料表内容,配合下拉式选单
>>: 前端工程师也能开发全端网页:挑战 30 天用 React 加上 Firebase 打造社群网站|Day13 文章页面
[常见的自然语言处理技术] 文本相似度(II): Cosine Similarity
前言 昨天我们使用了 Python 自然语言处理套件 spaCy 预训练好的 word embedd...
[Tableau Public] day 27:台湾姓氏分布分析-5
原本计画今天要把前四天的工作表合成数据仪表板,不过早上看了看原始资料後,发现其实还可以再做一张工作表...
Day15 用python写UI-聊聊Spinbox
第15天~~~完成了一半的铁人赛,之後也要继续加油! 今天要讲的内容是Spinbox,後面有几个实例...
前言-为什麽想写这篇
2016年因着朋友的推荐来到了一个新的工作场域,部门的工程师有三十多人,而且各司其职。初来乍到时觉得...
Day-16 Pytorch 的 Training 流程
我们昨天已经讲解完了最基础 Regression 的简易 Pytorch 实作了,那我们今天要稍微...