Day 11 - [爬虫] 01-蒐集训练资料 以卫服部长照常见问题为例
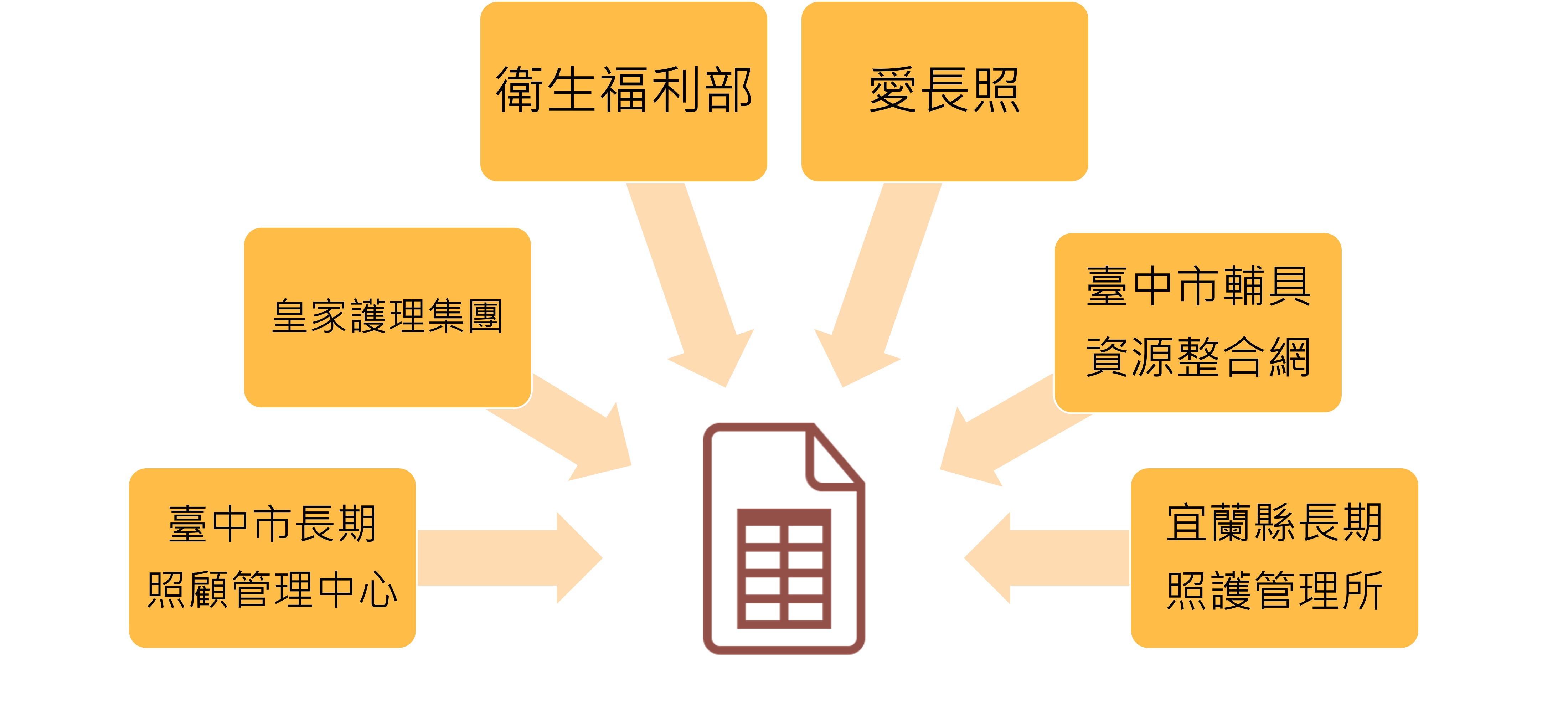
撰写 Python 程序码蒐集网路上的长照相关问答资讯,相比使用人工蒐集的方式,程序自动化蒐集方便又快速,也比较不会有缺漏。本研究将程序蒐集到的资料汇整成 CSV 格式,问答集来源包括:爱长照(爱长照编辑团队,2017)、台中市长期照顾管理中心(台中市长期照顾管理中心,2020)、皇家护理集团(皇家护理集团,2019)、台中市辅具资源整合网(台中市辅具资源整合网,2015)、卫生福利部(卫生福利部,2017、2020)、宜兰县长期照护管理所(宜兰县长期照护管理所,2019),共六个来源。
如果不想在自己电脑安装 Pytnon 环境,或装一些有的没的套件,很推荐使用 Google 提供的 Colab。我真的觉得这个工具是佛心来着,可以免费使用 Google 的 GPU、TPU。程序又可以分段执行,也很适合用来 debug。
不过我用 Colab 的最大原因是,因为爬虫的过程会需要大量发送请求(request),我很怕实验室 IP 被学校计中或卫福部 ban 掉。
进入正题!
今天选择爬卫福部的资料做为范例,完整的程序码可以参考: https://github.com/dreambo4/MOHW-QandA
载入函式库
首先载入等下要用的 Library
from bs4 import BeautifulSoup
import requests
import csv
目标网页
今天的目标是: https://1966.gov.tw/LTC/np-3972-201.html
我们要取得这 7 个分类里的所有 Q&A。因为只有 7 个分类,所以我只让程序从每个分类的第一页开始爬,而不是列出所有分类的这页。也就是说,以下的这个动作要做 7 次。
- 长期照顾特别扣除额: https://1966.gov.tw/LTC/lp-4641-201.html
- 长照服务法相关规定: https://1966.gov.tw/LTC/lp-3973-201.html
- 长照服务申请及评估: https://1966.gov.tw/LTC/lp-3974-201.html
- 长照给付支付基准: https://1966.gov.tw/LTC/lp-3975-201.html
- 预防延缓失能与照护计画: https://1966.gov.tw/LTC/lp-3976-201.html
- 长照机构法人: https://1966.gov.tw/LTC/lp-4112-201.html
- 其他: https://1966.gov.tw/LTC/lp-3977-201.html
可以发现网址的前半段都是相同的,因此 7 个 URL 可以写成
baseUrl = "https://1966.gov.tw/LTC/"
url = baseUrl + "lp-3977-201.html"
主程序
主要的程序是这样的
qaList = []
while True:
soup = getContent(url)
questions = soup.find("div", class_="List").find_all("a")
for q in questions:
qa = {}
answerUrl = q.get("href")
qa['url'] = answerUrl
qa['q'] = q.get("title")
qa['a'] = getAnswer(answerUrl)
print(qa)
qaList.append(qa)
nextPageUrl = getNextPage(soup)
if nextPageUrl is False:
break
url = baseUrl + nextPageUrl
取得问题列表
首先 getContent() 取得该页的完整内容。找到网页中的内容,我们要的就是这个 class="List" 的 div,并取得所有的 <a></a>,当中有我们需要的问题列表。
在 BeautifulSoup,要取得 Html tag 有两种方式: find、find_all,并且可以搭配使用
- find: 取得第一个标签
- fing_all: 取得所有标签
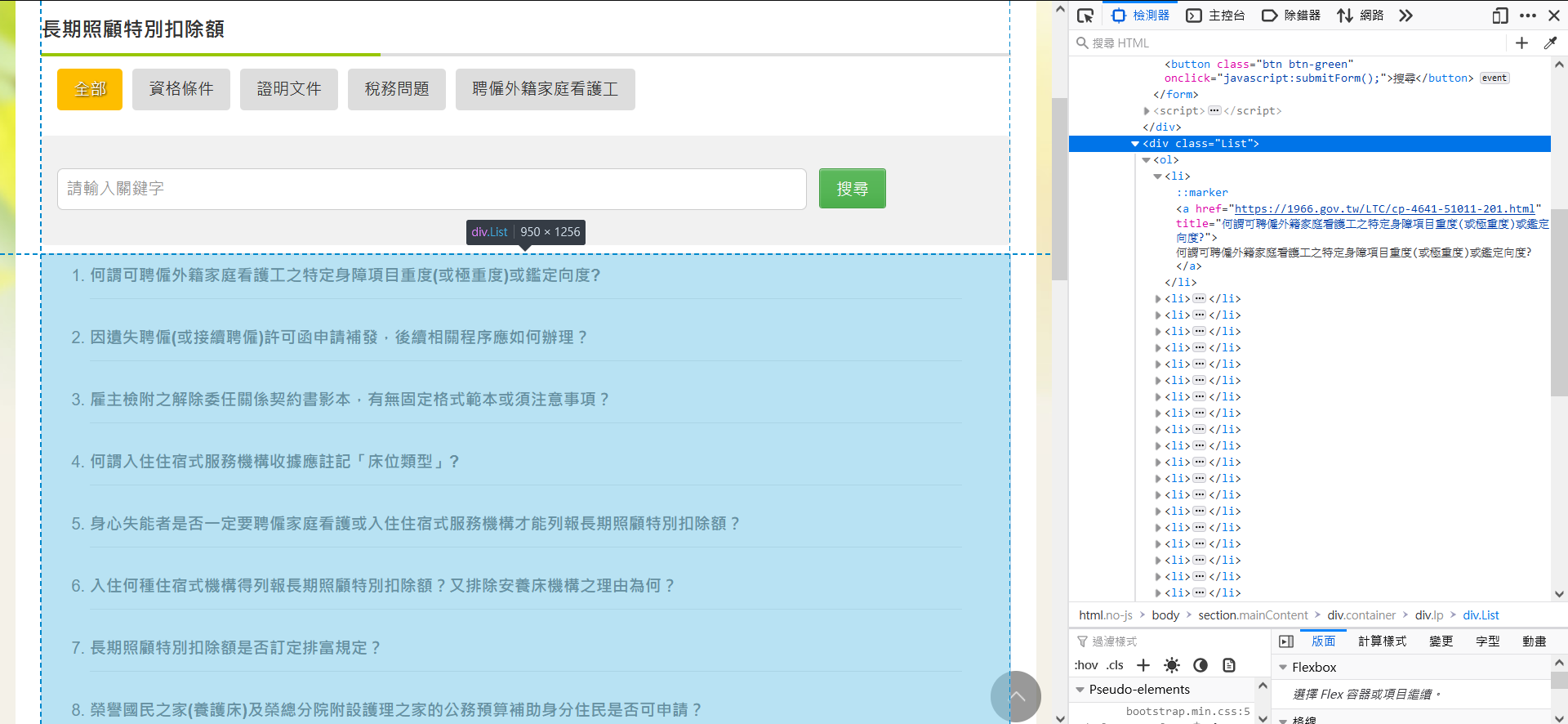
得到的问题列表(questions)大概会长这样,此时把 href 拿出来,便等於取得答案页的 URL。
[<a href="https://1966.gov.tw/LTC/cp-3977-42249-201.html" title="台湾的失智症长照服务资源量能?">台湾的失智症长照服务资源量能?</a>, <a href="https://1966.gov.tw/LTC/cp-3977-42248-201.html" title="「高龄政策白皮书」与「人口白皮书」,这两者的关系为何?何者应优先适用?">「高龄政策白皮书」与「人口白皮书」,这两者的关系为何?何者应优先适用?</a>, <a href="https://1966.gov.tw/LTC/cp-3977-42245-201.html" title="长照基金奖助之申请程序?">长照基金奖助之申请程序?</a>, <a href="https://1966.gov.tw/LTC/cp-3977-42244-201.html" title="有关长照服务资源不足地区的定义,建议重新检讨及订定检讨年限?">有关长照服务资源不足地区的定义,建议重新检讨及订定检讨年限?</a>]
整理 Q&A
但是里面还是有太多我们不需要的东西,因此再用个回圈整理一下,把一个个的 <a> 变成 dict 的资料结构。
BeautifulSoup 中取得 Html tag 中的内容,使用
get()
q.get("href") 可取得 "https://1966.gov.tw/LTC/cp-3977-42249-201.html"。这是此问题的回答页的连结,需要用getAnswer()再爬一次这个回答页的内容,来解析内容。
q.get("title") 可取得 "台湾的失智症长照服务资源量能?"
做成一个一个的 dict
{'url': 'https://1966.gov.tw/LTC/cp-3977-42249-201.html', 'q': '台湾的失智症长照服务资源量能?', 'a': '一、为因应我国快速增加的老年及失智人口,延缓及减轻失智症对社会及家庭的冲击,并提供失智症及其家庭所需的医疗及照护需求,本部於102年8月公布「失智症防治照护政策网领」,订定两大目标及七大面向,以作为我国失智症照护发展方向。并结合跨部会机关依据政策纲领七大面向提出行动方案32项,并依各工作项目之效益指标达成目标,以完善失智症照护防治体系。\n二、为提升失智症社区服务普及性,扩增失智症长照服务量能,已推动措施如下:\n(一)97年起失智者已纳入长照十年计画,失智症长者可经一般失能之基本日常生活活动能力(ADL)或临床失智评估量表(CDR)评估,判定失能或失智程度,核定补助时数,按老人之需求,提供失智老人适切长照服务。长照服务个案中失智症患者约占9.7%,截至104年5月底,提供失智症长照服务个案约1万5千多人。\n(二)完善社区照护网络-多元、在地服务及家庭照顾者:\n1.已完成185个多元日照服务单位(日照中心159个、日托据点26个),预计105年完成「一乡镇一日照」。\r\n2.失智专责服务:已设置日间照顾服务(17县市共25处)、老人团体家屋(10个单位/83床) 、瑞智学堂(19县市/60处)、失智症社区服务据点(28据点)、有失智症专区之机构 (41家,计1,317床;另规划中7家239床)。\r\n3.建构家庭照顾者服务支持网络:已设置失智症谘询关怀专线,针对长照十年个案高风险家庭提供谘询服务(1,141人/年);提供家庭照顾者照顾训练(908/场;17,137人次/年),及建立失智症互助家庭(2,451人次)。\n(三)充足长照服务人力:已完成医事长照专业三个阶段培训课程并展开训练,至104年8月已训练约30,000人次;又为让在地人照顾在地人,扩大培养在地长照人力,100-104年8月止约训练3200人次。\n(四) 提升民众对失智症防治及照护的认知:\n1.全民教育:拍摄纪录片如「被遗忘的时光」、「昨日的记忆」、忆起爱相随」、「照顾者心情故事-居家服务」、制作失智症卫教手册、认识失智症单张;办理学校、职场宣导讲座等进行教育宣导。\r\n2.社区健康促进网络如结合社区关怀据点(1,978个) 办理老人健康促进活动(6,359场;超过10万人)。\r\n3.建构高龄友善机构及城市方面:通过认证机构,医院有105家、长照机构有3家及1家卫生所;并於22县市全面推动高龄友善城市,让 280万之长者受惠。\n三、未来规划:\n(一) 104年5月已完成长期照顾服务法立法,可依法设置长照基金,发展服务及人力资源。\r\n(二) 整合原有之长照十年计画与长照服务网基础,推动长期照顾服务量能提升计画。'}
{'url': 'https://1966.gov.tw/LTC/cp-3977-42248-201.html', 'q': '「高龄政策白皮书」与「人口白皮书」,这两者的关系为何?何者应优先适用?', 'a': '(一) 人口政策白皮书所关注的人口议题包含了少子女化、高龄化、移民,高龄社会白皮书主要针对高龄者及未来高龄社会提出四大愿景与相关具体行动措施。虽两者皆有针对高龄化提出相关对策,但为因应人口老化迅速、家庭与生活型态改变与社会价值变迁的挑战,我国必须针对当今社会之高龄多元需求,同时参考国际经验与趋势,必须即早提出更前瞻且整体性的政策规划,以满足我国高龄者能够享有健康生活、幸福家庭、活力社会与友善环境,达到延长国人健康年数、减少失能老年人口的目标,并且整体提升高龄者生活幸福感。\r\n\xa0(二) 人口政策白皮书与高龄社会白皮书两者并无冲突与适用之优先顺序,高龄社会白皮书亦有融合人口政策白皮书之理念,并特别针对未来高龄人口需求延伸提出高龄政策之前瞻性架构与规划,以共同实践政府政策之愿景。'}
{'url': 'https://1966.gov.tw/LTC/cp-3977-42245-201.html', 'q': '长照基金奖助之申请程序?', 'a': '1.本部长照十年计画2.0-106年度补助计画,106年部分,本部社家署已於106年1月12日以卫授家字第1060800004号函送本部「106年度运用社会福利基金办理长照十年计画2.0补助项目及基准」,将补助案件分为主轴计画、整合型计画及专案计画等三类,可依该三类之补助项目、基准、作业程序办理。\r\n2.107年(含)以後及非属上开长照十年计画2.0-106年度补助计画经费之申请程序与相关作业规范,本部将另订长照基金奖助作业要点。'}
{'url': 'https://1966.gov.tw/LTC/cp-3977-42244-201.html', 'q': '有关长照服务资源不足地区的定义,建议重新检讨及订定检讨年限?', 'a': '1.现行长照服务资源不足地区,系依本部99年及103年办理长照服务资源盘点所规划之长照服务网区域划分。\r\n2.本办法第三条已明定「至少每五年办理长照服务资源供需之调查」。\r\n3.将依前项办理之调查结果,定期检讨长照服务资源不足地区之定义。'}
下一页
好了,这页读完了,下一页怎麽办,总不会还要再改网址重跑吧?
当然不是,下方可以看到有下一页的按钮,我们需要做的是,取得下一页的 URL,一样取得问题列表,直到最後一页(没有下一页)。

Functions
取得网页内容
根据 URL,取得该页的完整 Html。
def getContent(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
return soup
取得下一页的 URL
大概的意思是,一直找有没有下一页的箭头,有的话就取得下一页的连结。没有箭头,就表示没有下一页,回传 False。
def getNextPage(htmlContent):
if htmlContent.find('a', class_="icon-angle-right") is not None:
return htmlContent.find('a', class_="icon-angle-right").get("href")
else:
return False

取得回答
根据前面取得问题列表时得到的答案页 URL,再爬虫一次,取得相应的答案。
BeautifulSoup 中
get_text()可以取得标签中间的文字(不含标签)
def getAnswer(answerUrl):
answerSoup = getContent(answerUrl)
answer = answerSoup.find("div", class_="user_edit").find("p")
return answer.get_text()
资料清理/整理
我最後用来建模型的 CSV 是还有经过整理的,使用 Excel 或 LibreOffice Calc 可以方便的去除重复资料和编号。
| 栏位 | 说明 |
|---|---|
| id | 流水号 |
| Intent ID | [已弃用] 这个栏位可以略过,这是之前与 Zenbo DDE 对应用的 |
| Q | 问题 |
| A | 答案 |
| url | 问答组合的出处 |
| category | 纪录问答组合属於何种类别,编号对应会在之後的文章介绍 |
结语
今天就到这,谢谢大家。明天的主题是有关於,将这些爬下来的内容存成 CSV 档,方便後续使用。明天见!
参考资料
- Beautiful Soup 4.9.0 documentation. (2021). Beautiful Soup Documentation. Retrieved from https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- 宜兰县长期照护管理所(2019)。长照常见问题及回应。检自:https://ltc.ilshb.gov.tw/subject/15/view/42。
- 皇家护理集团(2019)。皇家Q&A。检自:https://www.royalnursinghome.com.tw/%e8%ad%b7%e7%90%86%e4%b9%8b%e5%ae%b6/。
- 爱长照编辑团队(2017)。简单搞懂「长照 2.0」-常见 QA 与新增服务项目。检自:https://www.ilong-termcare.com/Article/Detail/1533。
- 台中市长期照顾管理中心(2020)。长照常见问与答 (109.10 更新)。检自:http://ltcc2.health.taichung.gov.tw/files/15-1000-1042,c89-1.php。
- 台中市辅具资源整合网(2015)。常见问题。检自:https://www.tatrc-taichung.com.tw/QuestionAnswer?SearchForm.QuestionAnswerType=%e5%b8%b8%e8%a6%8b%e5%95%8f%e9%a1%8c。
- 卫生福利部(2017)。卫福部长照专区 常见问题。检自:https://1966.gov.tw/LTC/np-3972-201.html。
- 卫生福利部(2020)。卫生福利 e 宝箱 长期照顾。检自:https://www.mohw.gov.tw/cp-88-208-1-18.html。
JWT实作(三)(Day7)
我们现在设定两种权限,管理员(ADMIN)&正常(NORMAL) 要实作权限功能,我们先在u...
Ruby、演算法学习心得(一) 二元搜寻法 Binary Search。
铁人赛结束後一阵空虚?? 文章内容都会以Ruby来撰写程序码,然後继续来传教K-POP啦! 有请韩国...
[DAY 07]查询各国物品名称
昨天写完查询物品拍卖价格网址後发现...既然都有各国物品名称了 乾脆多做一个查询各国物品名称并附上W...
Day 22: Recurrent Neural Network — 循环精神网路初探(上)
Recurrent Neural Network 循环精神网路 RNN是一种专门设计用以解决时间序列...
[30天 Vue学好学满 DAY16] slot 插槽
slot 在子元件(内层)中预留空间,由父元件(外层)设定、分配内容。 子元件本身对slot无控制权...