Gradient Descent
今天来聊聊在ML里面一天到晚听到的gradient descent!
Gradient descent是用来解决Optimization问题的常见算法,也因为只是一个计算的方式,透过变换不同的Loss function,gradient descent可以应用在很多不同的场景中。
原理
想了解gradient descent首先要先知道一点点微积分的概念,基本上只要知道一阶微分还有微分其实就是斜率这两件事就可以了(笑,主要的步骤有:
- 对你的loss function做微分:看有几个参数就对个别参数做一次偏微分,你偏微完的东西就叫gradient
- 对参数随机设置起始值:你可以说刚开始大家都是0,或是任何数字
- 计算slope: 把你设定的参数值放进你的gradient里算出的就叫slope
- 计算step: step=slope * learning rate
- 计算新的参数值:等於旧的参数值-step
- 重复步骤3-5直到你的slope/step趋近於0
只看上面的步骤可能觉得我不知道在说什麽,这边举一个简单的例子:如果我们今天有一个3个资料点的dataset,我们想要找出一条最好的线来表现(y=ax+b),在这里为了简化我们假设已知a=0.64,所以目标是找出最理想的b,这里的loss function我们假设为距离最小平方和(SSR)
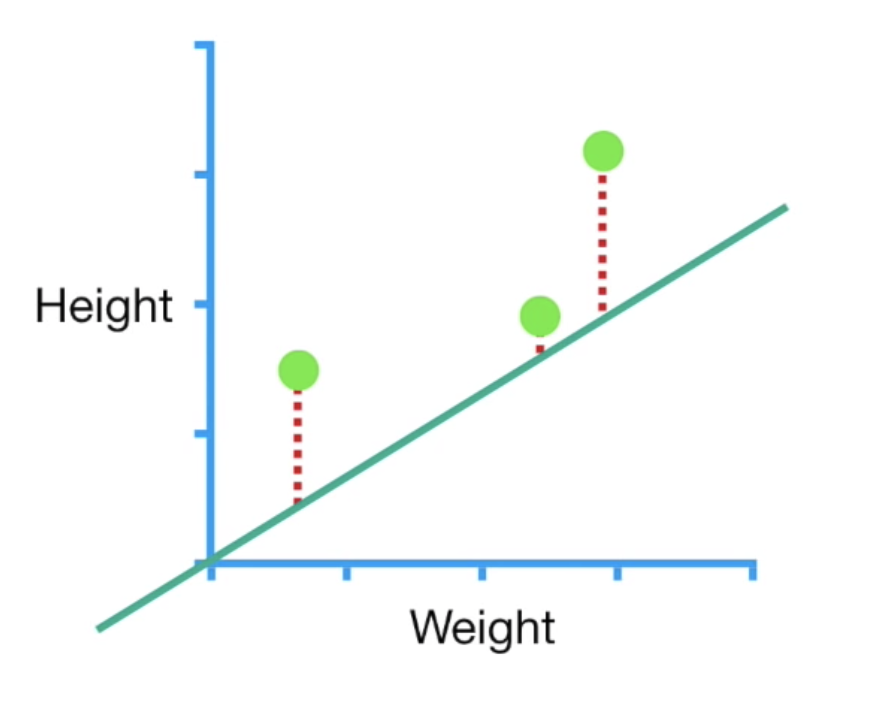
接下来我们帮b设置一个随机起始值,计算SSR,根据起始值的不同,我们可以算出不同的SSR然後画成如下右图:
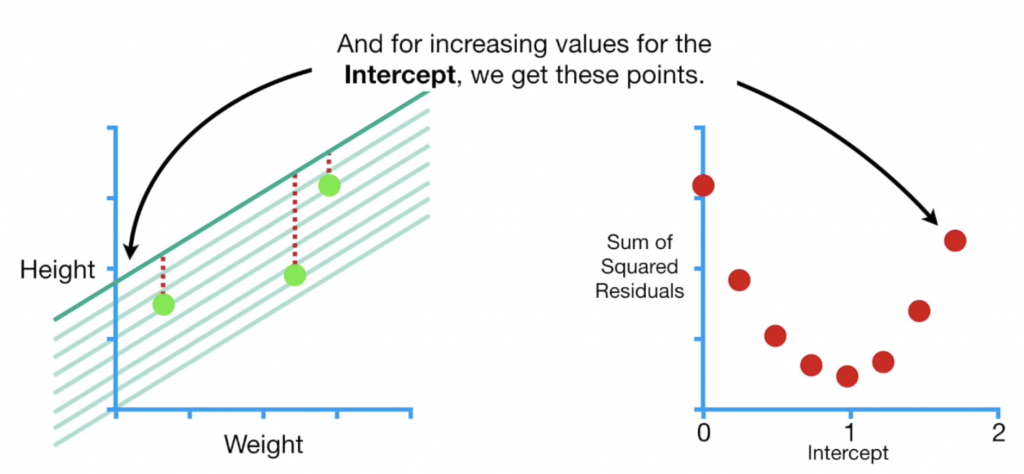
其实我们最想要找到的点就是右边这个红色曲线的最低点,也就是找到一个b值让loss(SSR)最小,也就是曲线切线斜率等於0的位置。
偏微分就是让你的b值从起始走到那个最理想的点的方式,首先按照步骤一,我们把所有资料带入loss function之後对b做偏微:
data: (0.5, 1.4),(2.3, 1.9),(2.9, 3.2)
SSR = (y - y_pred)^2 =
(1.4 - (0.64 * 0.5 + b))^2 +
(1.9 - (0.64 * 2.3 + b))^2 +
(3.2 - (0.64 * 2.9 + b))^2
= (1.08 - b)^2 + (0.42-b)^2 + (1.34-b)^2对b微分:
= 2(1.08 - b)(-1) + 2(0.42 - b)(-1)+2(1.34 - b)*(-1)
= -2(1.08 - b + 0.42 - b + 1.34 - b) **
= -5.68 + 3b
得到偏微结果後,我们就可以进入步骤二:对参数随机设置起始值,我们假设b起始为0,所以带入偏微结果等於-5.68,我们知道偏微就是斜率的概念,所以这个-5.68其实就是下图红色线的斜率
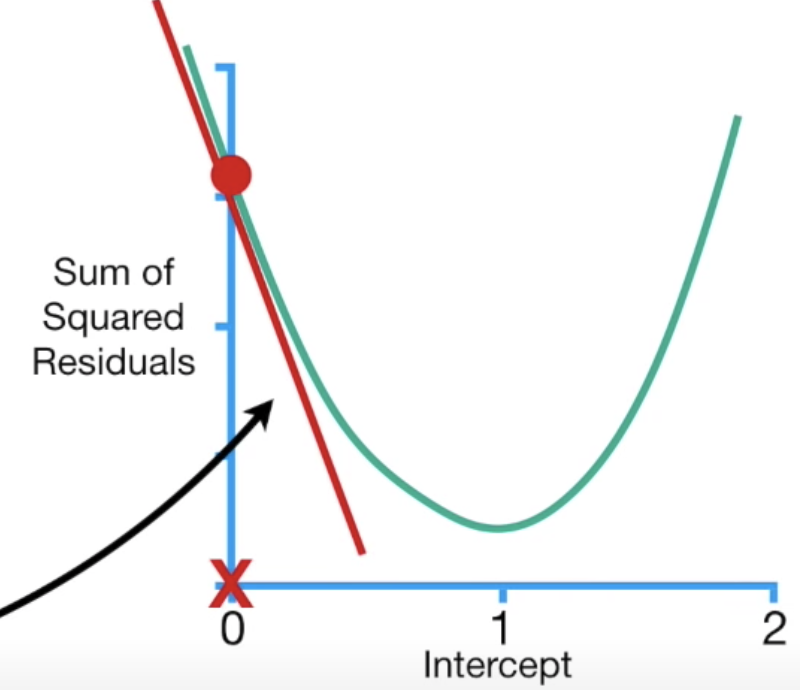
下一步骤是计算step,step=slope * learning rate,learning rate会影响到步伐的大小,如果走太小就会走很慢,如果走太大步可能就会直接错过我们想找的loss最小值,这里我们先设定为0.1,所以第一个step是-5.68 * 0.1 = -0.568,而下一个步骤是计算新的参数值:等於旧的参数值-step,也就是前一个b值-step = 0-(-0.568) = 0.568,根据计算的结果,我们往右走0.568的步伐,如下图:
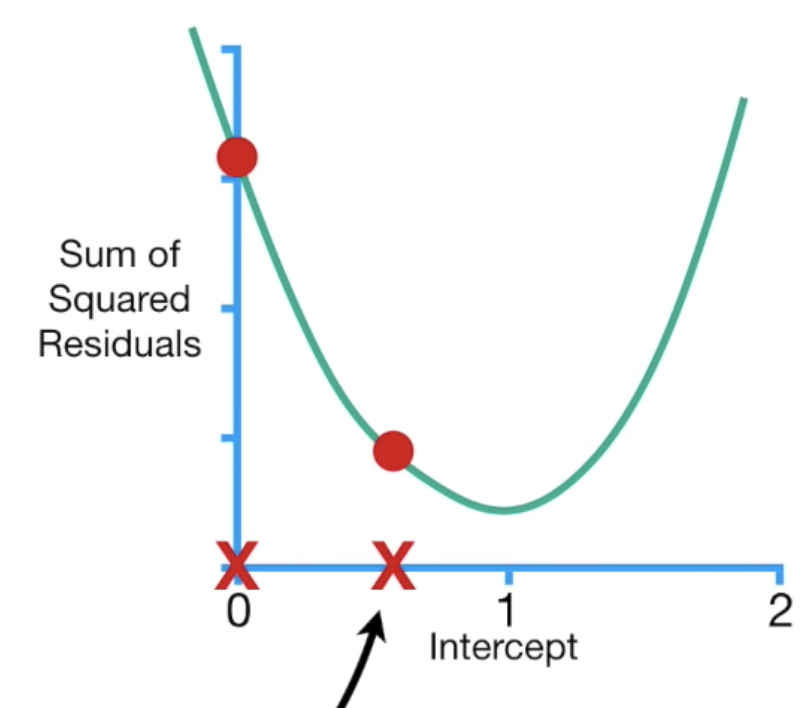
接下来就是重复的步骤,把新的b值带回偏微公式(-5.68 + 3 * 0.568),然後计算新的step(0.568-(-0.397)=0.965),依此类推,走到step趋近於0,就大功告成啦~
希望这篇文章可以让大家更了解Gradient Descent的计算过程,其实并不复杂呦!
reference:
https://www.youtube.com/watch?v=sDv4f4s2SB8&t=653s
>>: 33岁转职者的前端笔记-DAY 24 jQuery DOM 节点
[Day27] JSON
JSON (JavaScript Object Notation) 是一种资料交换格式,内容为属性与...
JavaScript基本功修练:Day27 - AJAX基本概念
对於新手来说,AJAX课题里比较难懂的部分应该是背後的运作概念,而非程序码本身。这个课题会分开几篇,...
rsync备份操作
现在可以利用前两天建立的ZFS阵列对unRaid 做rsync了~ 会从介绍到实作,根据不同状况进行...
Day 03 - 动态调整的PM职涯规划(2)
图片来源 继续上一篇的目标设定, 有时候我觉得是因为你心中已有一个"既定的目标"...
day15_Linux ARM 的网站开发之旅
Linux ARM 可以当日常的网站开发吗? 我们这里的能够开发,定义为可以独立执行, 除错, 并发...