Day21-pytorch(4)Dataset、DataLoader
为什麽需要用到这两个东西呢?
因为我们在训练资料时
如果每次输入的资料都是一整个一样的资料,表示每次微分的结果都会一模一样
只是一直往同一个方向做梯度下降,这样的训练结果并不理想,而且可能也会遇上Local Minima跳不出来
如果我们能每次都是从一整群资料里取出不同群来做微分,这样每次计算的结果都不一样
这样更有利於我们训练资料,DataLoader即能为我们做到此效果
这里我会用鸢尾花资料集来做操作示范
载入资料集
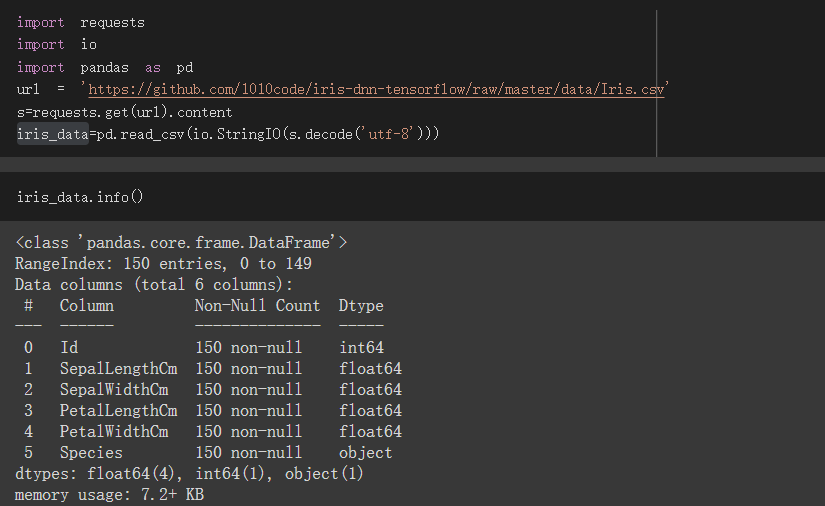
id 只是资料编号,等一下不会拿来用
SepalLengthCm、SepalWidthCm、PetalLengthCm、PetalWidthCm为特徵值
Species为训练目标
资料转为np
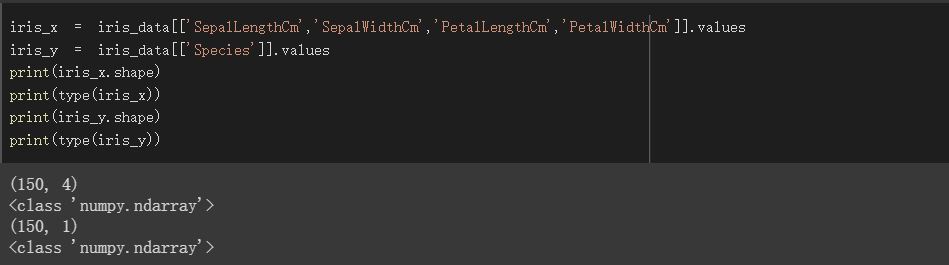
分别将特徵栏位及训练目标栏位透过属性values得到numpy形式的值
import Dataset、DataLoader
from torch.utils.data import Dataset,DataLoader
设置Dataset

在__init__後方传入x(特徵值)、y(训练目标)
设置self.x(特徵值), self.y(训练目标), self.n_sample(资料个数)这三种属性
__getitem__需有index参数,最後__len__就是回传资料个数
dataset设置完後传入刚刚的资料train_set = dataset(iris_x,iris_y)
设置DataLoader
将刚刚设置好的train_set传入DataLoader後方dataset参数
batch_size设置每次要一起处理几笔资料
shuffle为Ture会不规则的取出资料,可使每次微分结果不同,要训练资料时都会设为Ture

DataLoaer为一种迭代物件,根据我们设置的batch_size会决定它的长度
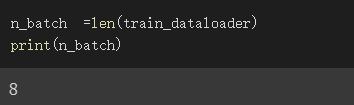
上面范例我设batch_size为20,而我们种共有150笔资料
所以DataLoader的长度为8
因150/20取整数为7,余数10,剩下的10笔资料也须成为1组,7+1为八组
设n_batch为dataloader的长度
Dataset、DataLoader就写到这里
明天我会以iris资料集为范例写出一个完整的训练过程,
送上colab连结,可自行在上面多做点练习更加熟悉pytorch
https://colab.research.google.com/drive/1yBz68LIIYFQEZNHDjHeBvyEVsDR8ulTQ?usp=sharing
Day07:资料结构 - 杂凑表(Hash Table)
杂凑表,我需要那个酷东西 在线性资料结构中,若要找一个资料,花费的时间复杂度为O(n),或是可以选择...
Day 23:获取位置权限
本篇文章同步发表在 HKT 线上教室 部落格,线上影音教学课程已上架至 Udemy 和 Youtu...
连续 30 天 玩玩看 ProtoPie - Day 29
糟糕 突然就 29 天 了。 今天来看官网上的 ProtoPie Advanced Workshop...
【Day4】[资料结构]-链结串列Linked List-实作
链结串列(Linked List)建立的方法 append: 在尾部新增节点 insertAt: 在...
[ Day 09 ] State 是什麽?
在前面的篇幅中有提到, React.js 是采用元件式开发并可以设定每个元件不同的状态( Stat...