[Day19] 为什麽都没有 Google Map 评论抽奖器? 只好用Python做一个了!
不管是IG还是FB,都可以看到网路上有免费的留言抽奖神器,
但是不知道为什麽都没看过Google Map评论抽奖器(还是只有我没看过?)
本篇会将指定店家的Google评论全部爬下来,并指定给五星评价的人才有抽奖资格~
如果有想指定评论时间的也可以设定条件喔~
使用环境
行前说明
在抽奖前我要推荐一下内湖站超好吃的餐厅-极饿便当专门店,因为实在太好吃,
所以这篇就用极饿便当专门店举例喔~
程序码
import requests
import json
import random
j = 0
lottery_pool = []
while 1:
# 这边的连结不是Google Map商家的连结喔!我们明天再说这个连结是怎麽来的~
url = "https://www.google.com.tw/maps/preview/review/listentitiesreviews?authuser=0&hl=zh-TW&gl=tw&pb=!1m2!1y3765762734390772041!2y17055821615375049737!2m2!1i"+ str(j) +"!2i10!3e1!4m5!3b1!4b1!5b1!6b1!7b1!5m2!1siMZEYbemFIeymAWI2pko!7e81"
j = j + 10 # 因为一页评论最多有十条,连结规律是10、20、30...,所以一次要加10
text = requests.get(url).text # 发送get请求 (这边我是看zino lin大神的教学)
pretext = ')]}\'' # 取代特殊字元
text = text.replace(pretext,' ') # 把字串读取成json
soup = json.loads(text) # 载入json档
review_list = soup[2] # 留言的位置
if review_list is None:
break
for i in review_list:
print("正在抽奖...")
# 姓名: str(i[0][1])
# 时间: str(i[1])
# 星星数: str(i[4])
# 留言内容: str(i[3])
if i[4]==5 and i[3] != None: # 给五星加有留言的评价才可以抽奖喔
dict = [str(i[0][1]),str(i[1]),str(i[4]),str(i[3])]
lottery_pool.append(dict)
winner_index = random.sample(range(0, len(lottery_pool)-1), 3) # 设定抽3人
print("-------中奖名单------")
for i in winner_index:
print(lottery_pool[i])
成果发表会
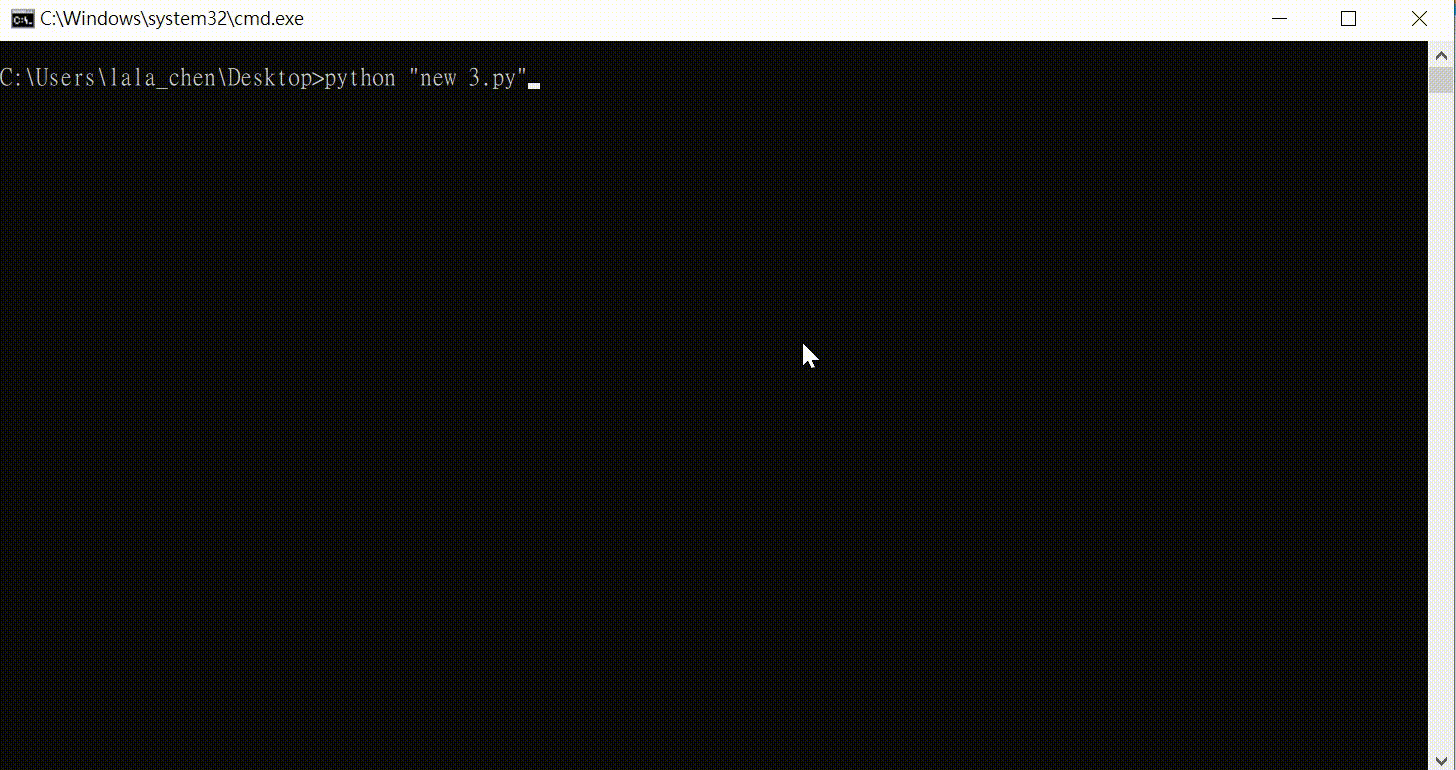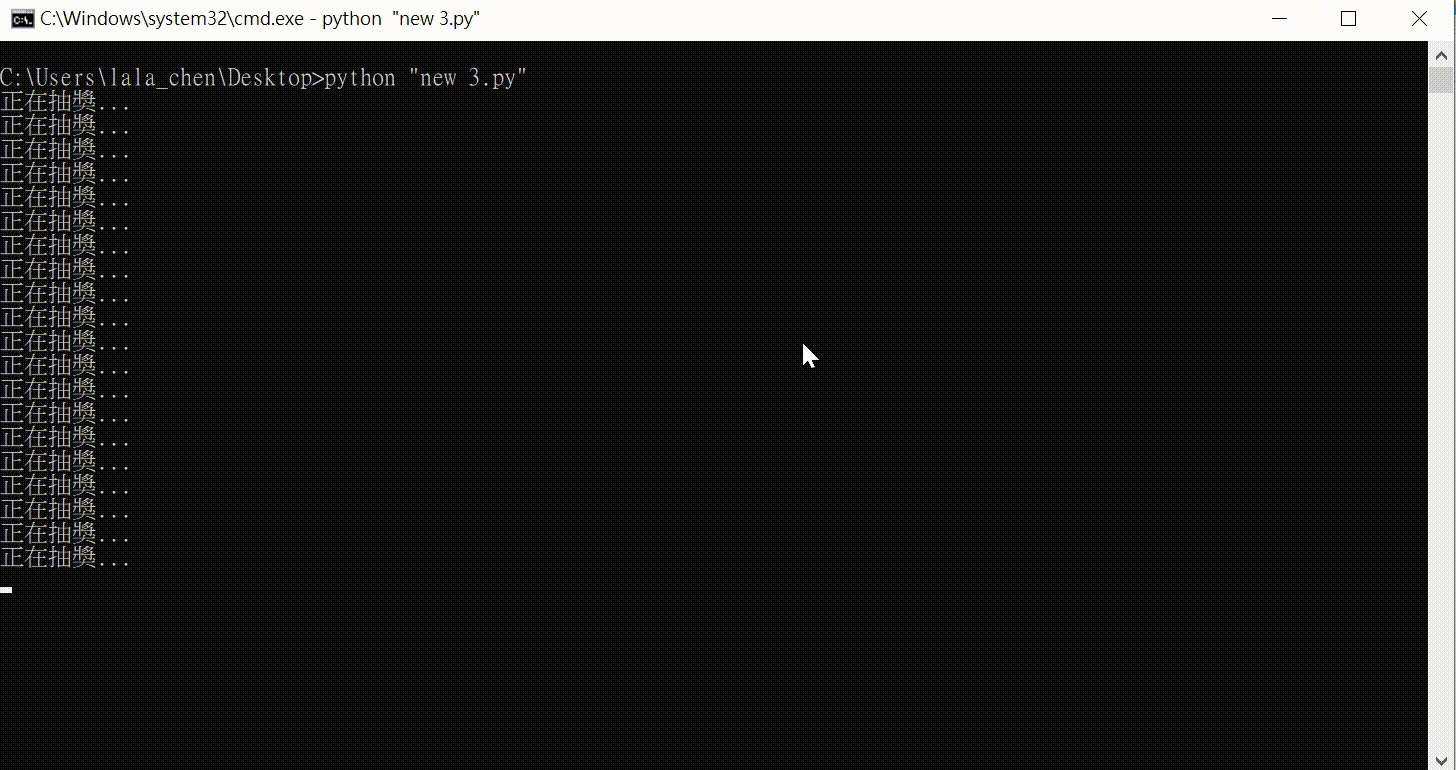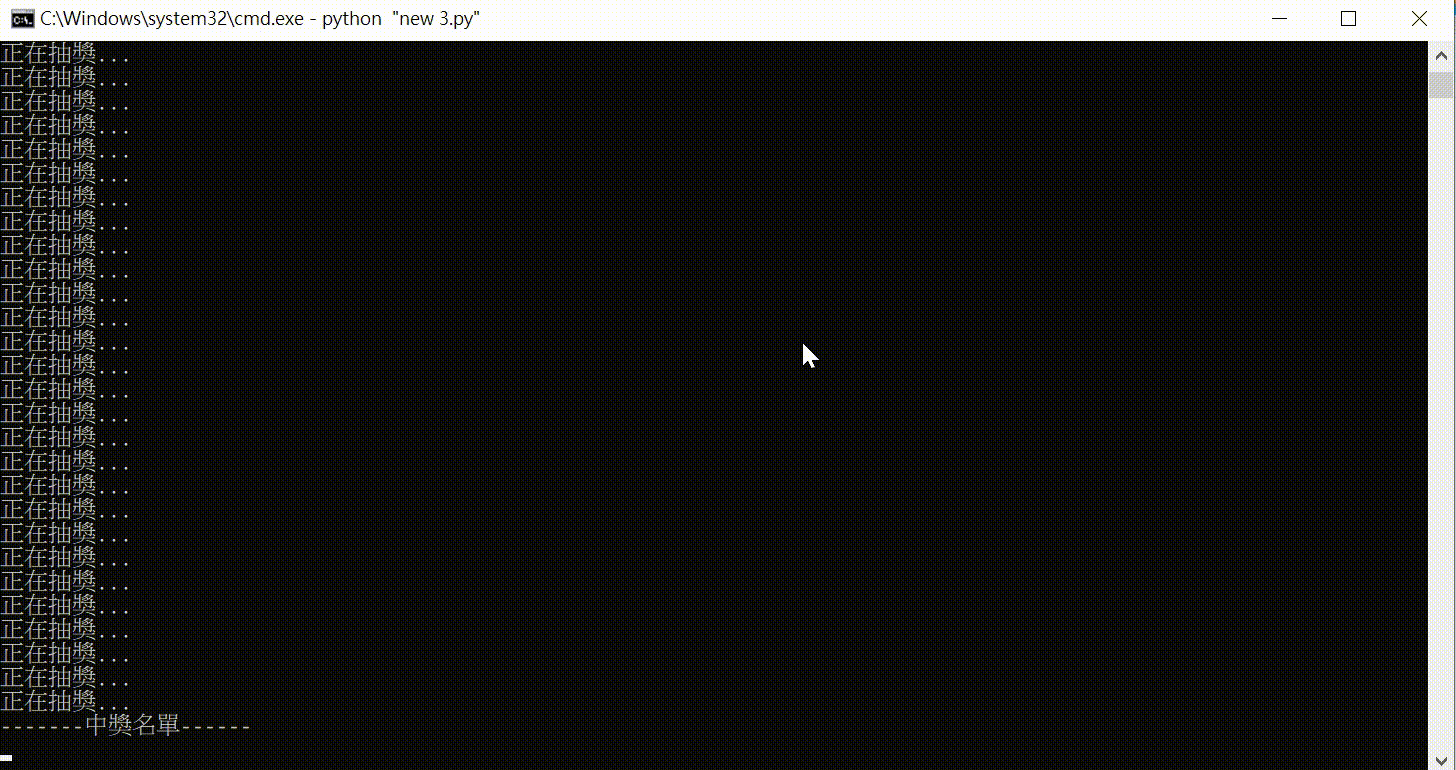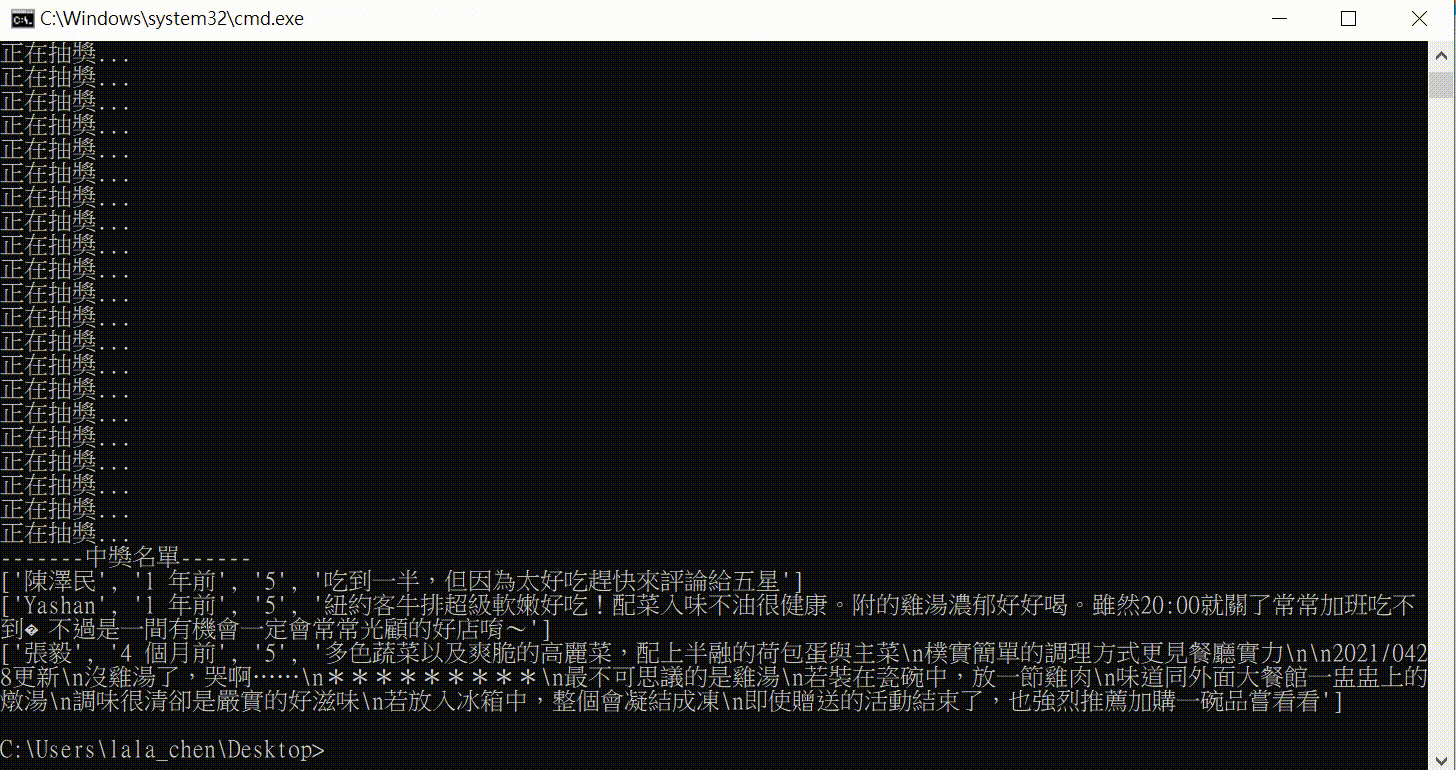
没错! 这间便当就是这麽好吃!
温馨小提醒
程序中的url连结不是Google Map店家的连结喔!
明天再跟大家解释详细的抓评论方法~
我在执行程序大概到第30次左右的时候会出现这个错误讯息:
File "C:\Users\User\Downloads\google.py", line 24, in <module>
soup = json.loads(text)
File "C:\Users\User\lib\json\__init__.py", line 346, in loads
return _default_decoder.decode(s)
File "C:\Users\User\lib\json\decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "C:\Users\User\lib\json\decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
如果不是一开始编译就出现这个错误,而是执行数次後突然发生,
那就是对方网站发现你在爬虫把你挡掉了!
这时候除了换连一个网路这种治标不治本的方法外,还可以用fake_useragent套件将我们爬虫请求的身分伪装成某个浏览器,详细步骤如下:
- 安装 fake_useragent
pip install fake_useragent - 产生随机的user agent
from fake_useragent import UserAgent
ua = UserAgent() # 产生一个 user agent
user_agent = ua.random # 随机产生一个 user agent字串
- 把 requests 的 header 替换成刚刚随机产生的假 user agent
headers = {'user-agent': user_agent}
text = requests.get(url, headers=headers).text
这样执行好几次就不会再出现上面的错误讯息罗~
但是还是建议加个time.sleep()让程序休息一下,毕竟爬虫会消耗对方服务器资源,我们要有礼貌 ^-^
<<: Day 4 - 用 canvas 复刻 小画家 填入色彩, 橡皮擦
>>: Day19 - 轻前端 Vue - 复杂型别 object + collection
第35天~
这个得上一篇:https://ithelp.ithome.com.tw/articles/10258...
DAY19 搞样式--CSS Gird 怎麽用(上)?
前言 上一篇提到了格线布局的概念,简单的用图片来呈现,并没有提到程序码的部分,今天就让我们来开始研究...
Day23 设定Alerts
今日我们要来使用Kibana内的警报功能,看如何设定Alert让我们能收到异常的通知。 设定Aler...
程序语言、Ruby、Rails
新手入门笔记 我为素人,以分享角度提供个人心得笔记等,主要在帮自己做笔记。 内容有误或英文打错,非常...
Day13 NiFi - Variables & Parameters
今天要来讲的主题是 - Variables & Parameters。如果读者们还记得 Fl...