DAY18 机器学习专案实作-员工离职预测(下)
一、挑选模型
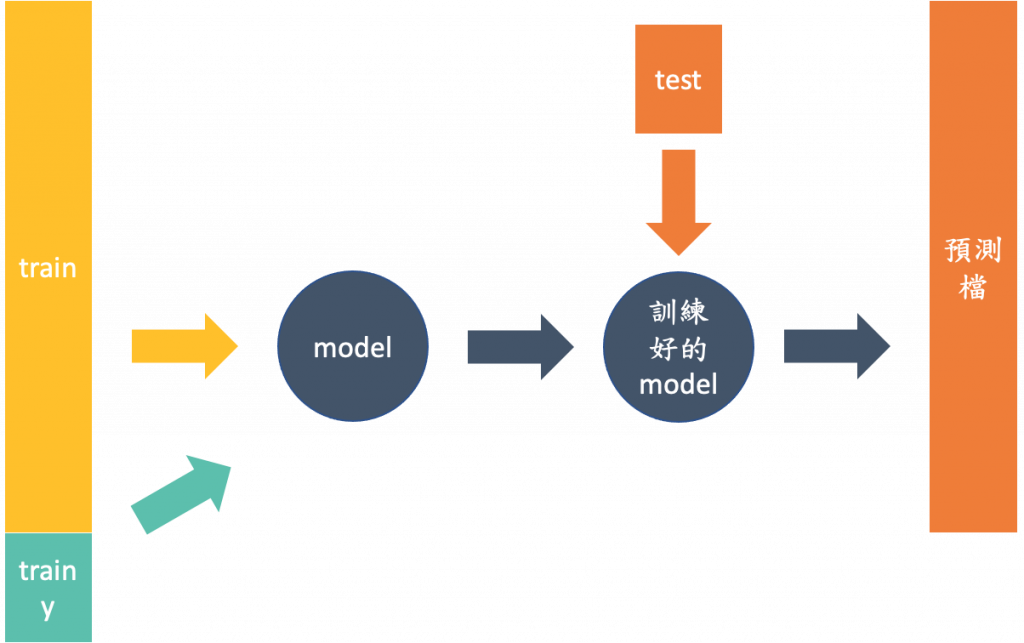
再将资料丢入模型前要先做好资料前处理,并将训练资料的答案另外独立出来,然後把训练资料与你独立出来的答案丢入模型做训练,最後再把你的测试及资料丢入训练好的模型,就可以得到一个预测档案。然後将预测档案用成主办方给你的范例样式,最後丢到网路上去看你的分数,如下图。
1. 随机森林
X=df_train.drop(["最高学历","毕业学校类别","PerStatus"],axis=1)
y=df_train["PerStatus"]
X=X.fillna(-1)
df_test=df_test.fillna(-1)
#%%
df_feature_scores.reset_index(inplace=True, drop=True)
#%%
df_X=X["PerNo"]
for i in range(1,21):
df_X=pd.concat([df_X,X[df_feature_scores["Feature"][i]]], axis=1)
#%%
data_test=df_test["PerNo"]
for i in range(1,21):
data_test=pd.concat([data_test,df_test[df_feature_scores["Feature"][i]]],axis=1)
#%%丢入模型做预测
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier(n_estimators=100)
rfc_model=rfc.fit(df_X,y)
pred_test = rfc_model.predict(data_test)
#%%将预测出来的值照着主办单位的形式做成提交档
pred_test=pd.DataFrame(pred_test)
submit2=df_test["PerNo"]
submit2=pd.DataFrame(submit2)
submit2=pd.concat([submit2,pred_test],axis=1)
submit2.columns=["PerNo","PerStatus"]
#%%将提交档案做储存
submit2.to_csv("你要储存的路径",index=False)
2. XGboost
X=df_train.drop(["最高学历","毕业学校类别","PerStatus"],axis=1)
y=df_train["PerStatus"]
X=X.fillna(-1)
df_test=df_test.fillna(-1)
#%%
df_feature_scores.reset_index(inplace=True, drop=True)
#%%
df_X=X["PerNo"]
for i in range(1,21):
df_X=pd.concat([df_X,X[df_feature_scores["Feature"][i]]], axis=1)
#%%
data_test=df_test["PerNo"]
for i in range(1,21):
data_test=pd.concat([data_test,df_test[df_feature_scores["Feature"][i]]],axis=1)
#%%丢入模型做预测
from xgboost import XGBClassifier
xgbc=XGBClassifier()
xgbc_model=xgbc.fit(df_X,y)
pred_test = xgbc_model.predict(data_test)
#%%将预测出来的值照着主办单位的形式做成提交档
pred_test=pd.DataFrame(pred_test)
submit2=df_test["PerNo"]
submit2=pd.DataFrame(submit2)
submit2=pd.concat([submit2,pred_test],axis=1)
submit2.columns=["PerNo","PerStatus"]
#%%将提交档案做储存
submit2.to_csv("你要储存的路径",index=False)
这次的模型握最後选用XGboost,因为我将XGboost与随机森林丢入还没筛选特徵的资料,发现前者更为准确,因此後面做评估我都以XGboost这个模型为基准。
二、评估
将资料上传到网站上给主办方评估成绩吧
这次主办方给我们的评估标准是F1 score,范围介於0~1,当然越趋近於1越准确。
我做了很多尝试,将资料分成使用onehot encoding跟未使用onehot encoding来整理给各位看
-
使用onehot encoding
未筛选特徵:0.2387755
使用卡方筛选特徵:0.1120689
用随机森林筛选特徵:0.1969696
-
未使用onehot encoding
未筛选特徵:0.1611570
使用卡方筛选特徵:0.1262953
用随机森林筛选特徵:0.1489971
三、结论
有没有发现做了很多但分数也一直没进步呢?其实当初这个资料在比赛的时候,第一名的准确率也仅仅只有0.3多而已,所以不用太气馁啦。小编0.238775的成绩可是也有短暂的位居第一呢,後来随着强者越来越多,排名也慢慢被往後面挤了,所以也要让自己不断进步才行。
重点是我们终於从无到有完成一个专案啦~给自己一个掌声。花了18天终於搞懂机器学习在干嘛了,但你们要知道小编在这18天的内容里可是走了好多冤枉路,最後一步步拼凑才有今天的文章。所以坚持下去,你也可以在资料科学发光发热。
明天开始我们将会来谈深度学习领域,又是一个全新的世界对吧?跟着小编一起继续探索吧!
Day 26 初学者补给站 学习方向讨论
大家好~~欢迎来到第二十六篇 聊聊学习方向讨论 本篇呢 会跟大家分享,平时本人会怎麽训练自己的程序。...
Day24 Let's ODOO: Discuss
Odoo在安装时内部就提供Discuss内容,透过创立群组,并以标记的形式我们可以更明确的沟通与合作...
Day15 - 请蛇上台
class Snake { constructor() { // 蛇头位子 this.head = ...
视觉设计(4)
渐层背景 背景(background)除了可以用图片、单色填满之外,也可以设定为渐层。其属性值为li...
如何用 AppFollow 做关键字研究
在 AppFollow 上查目标市场的 auto suggestion 找在一些大关键字中排名比较...