Day02 - 语音辨识的架构、发展过程
虽然目前深度学习的技术是开发语音辨识系统的主流,而且也已经取得不错的成果。但如果要了解语音辨识系统的架构、运作原理,就必须要从传统的语音辨识技术开始说起。
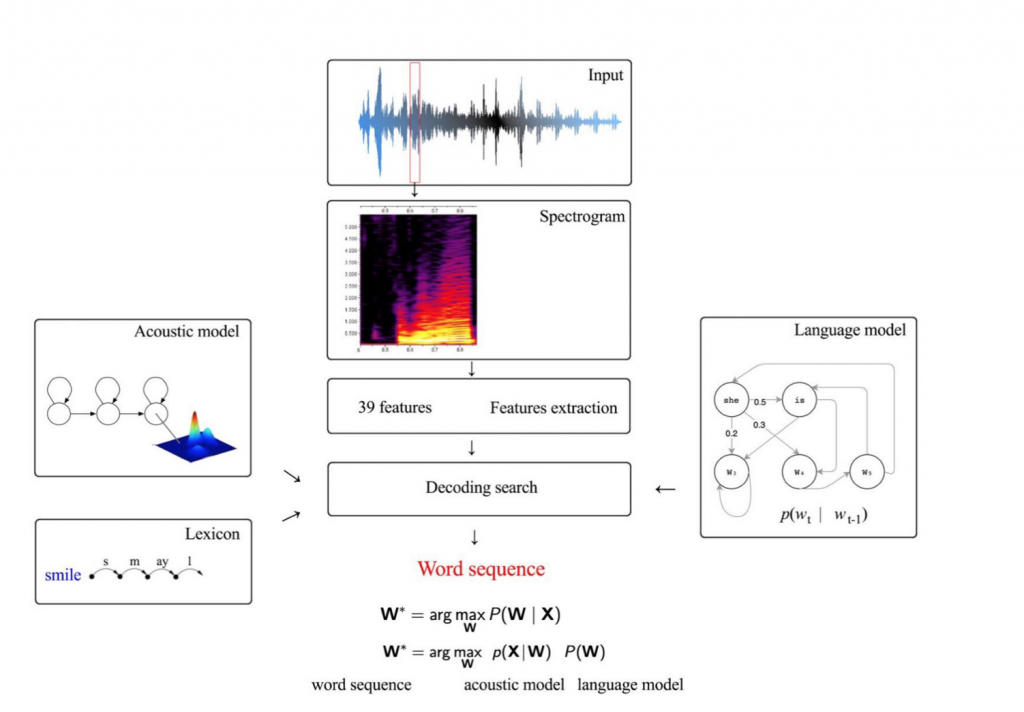
传统的语音辨识系统主要包含3部分
- 声学模型(Acoustic model, AM): 负责处理输入音频(audio)转换成音素(phoneme)
- 发音词典(Lexicon): 负责将声学模型产生的音素(phoneme)转换成字(word)
- 语言模型(Language model, LM): 负责将各别的字(word)组合成句子(sentence)
其中声学模型和语言模型是分开训练,一般常使用高斯混合模型(GMM-HMM) 作为系统架构,如下图:
Seq2seq 架构图,图片来源: https://jeddy92.github.io/JEddy92.github.io/ts_seq2seq_intro/
语音辨识的原理其实可以简单地用一个数学式表达:
W 是辨识得到的文字序列,X 是输入的音讯(包含多个音框, frame),因此目标就是在已知的输入音讯下,找出机率最
高的输出文字序列。透过贝氏定理(Bayes' theorem) 可将上述数学式转换成:
其中,P(X|W) 表示给定一文字序列 W 下出现音讯 X 的机率,即为声学模型(AM);P(W) 表示文字序列W出现的机率,即为语言模型(LM)。
但是随着深度学习的发展,愈来愈多的研究开始使用类神经网路(Neural Network, NN) 去取代GMM,形成 DNN-HMM 的混合(hybrid)架构,达到与GMM-HMM相同甚至更好的表现。到了现在,研究人员连 HMM 也舍弃不用,让整个语音辨识系统全由单一神经网路构成,像这样从输入端到输出端只透过一个神经网路模型完成称做端到端(end-to-end)语音辨识。
第二天的内容就到这边,接下来将会介绍什麽是端到端(end-to-end)语音辨识 !
参考资料: https://engineering.linecorp.com/zh-hant/blog/speech-technology-0207/
[Day 13] 简单的单元测试实作(七)-建立共用的函式
昨天有提到, 其实我们通常不会把函式直接写在web.php当中, 其实我们回传的这个资料, 如果要透...
#14 No-code 之旅 — 怎麽利用 Chakra UI 去做 React 元件客制化?
继续昨天的主题,该怎麽用 Chakra UI 做开发呢?现成的元件该怎麽去做客制化?专案有定设计系统...
React-视窗滚动改变DOM
一开始我想实现一个办法 就是在滑鼠滚动到指定位置时 我指定的区块会浮现出来 滑鼠往上滚时,区块会一起...
[面试][人格特质]一再被问的经典面试题
每个人的性格不同,不要去追求所谓的完美解答;而是去寻找适合自己的环境。 这边笔者依照类型统整了经常...
【2】学习率大小的影响与学习率衰减(Learning rate decay)
Colab连结 大家应该听到烂了,学习率(Learning rate)指的是模型每做完一次 back...