Youtube Reports API 教学 - 告一个段落
「鲑鱼均,因为一场鲑鱼之乱被主管称为鲑鱼世代,广义来说以年龄和脸蛋分类的话这应该算是一种 KNN 的机器学习,不正经的数据分析师,毕业後把人生暂停了半年,在 Google 和 AWS 办过几场演讲,缓下脚步的同时找了份跨领域工作。偶而慢跑、爱跟小动物玩耍。曾立过很多志,最近是希望当一个有细节的人。」
Youtube Reports API 教学 - 告一个段落
这是系列文的最後一篇实战教学文章了,YouTube Reports API 能够使开发人员安排报告的排程,并且批量下载生成报告。对於 YouTube Reports API 而言, API 支持预先所以定义好的报告内容,并且每个报告都包含一组针对频道使用者或内容管理员 YouTube 资讯。灵活的追踪每 Youtube 影片的影片资讯,也有了更加弹性的资料运用方式。这篇是 Python - 数位行销的 Youtube 分析教学系列文章的第 29 篇,也是我参加 2021 iThome 铁人赛中系列文章的第 29 天。
系列文章:Python — 数位行销分析与 Youtube API 教学
昨日回顾:Youtube Reports API 教学 - 频道中出报表
关於 YouTube Reports API

YouTube Reports API 的目的在於,让开发人员与使用者可以快速生成报告,并且对於报告进行取用和分析,对於 YouTube Reports API 的使用来说我们大致上分为几个步骤。
- 呼叫 reportTypes.list() 方法以搜寻频道或内容管理员可以检索的报告列表。
- 呼叫 jobs.create() 方法来确定应该为频道或内容管理员生成报告。随後使用 API 的 jobs.list() 和 jobs.delete() 来检索或更改正在生成的报告列表。
- 呼叫 jobs.reports.list() 方法为特定作业生成的报告列表。响应中的每个资源都包含一个 downloadUrl 属性,该属性指定可以从中下载报告的 URL。
- 发送授权的 GET 请求下载 URL 检索报告。
得到了 Reports API 的结果後
在上一个章节中我们提到了 Reports API 回传的结果,会是不按照顺序的汇出资料列表资料,我们从中可以看见像是 9月24, 10月03, 10月10 等等的日期
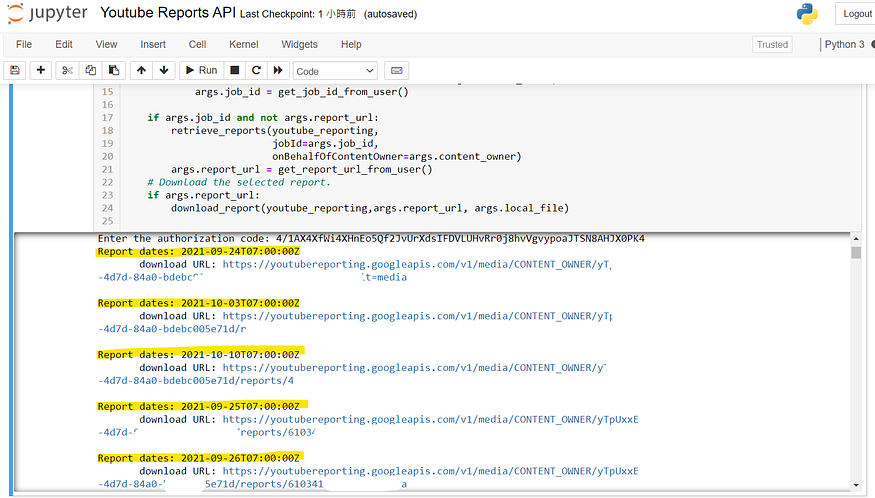
- 利用 Report dates 回传的 URL 资料,贴上最底下的 URL download,将会开始进行下载,直到100% 时,回传 Download Complete! 资讯,这里选择 8/12 日的资料做下载测试
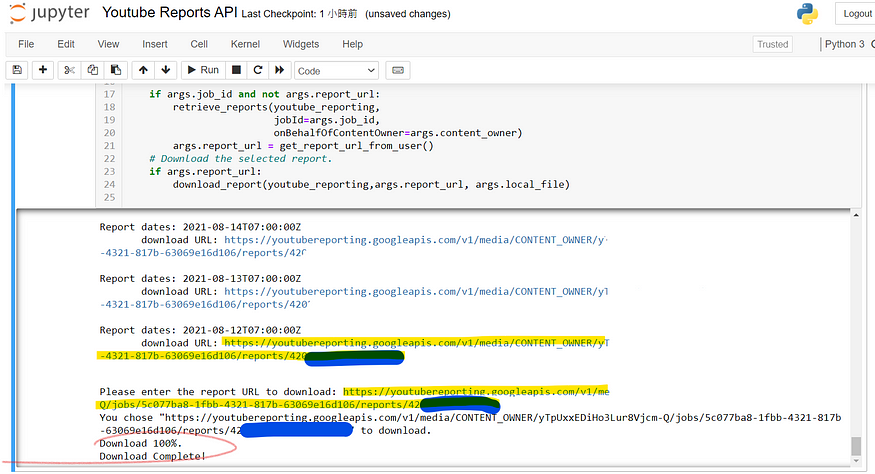
真的有成功吗,确认一下 !
- 查询一下储存地点,确认资料下载是否成功,从资料中确实可以看见资料被成功汇出至 local_file
if __name__ == '__main__':
aa = input("jobID:")
tt=time.strftime("%m%d_%H%M%S_", time.localtime())
parser = argparse.ArgumentParser()
parser.add_argument('--content_owner', default='y..你的ID...Q')
parser.add_argument('--job_id', default=aa)
parser.add_argument('--report_url', default=None)
parser.add_argument('--local_file', default='Output/'+str(tt)+'output.csv')
args = parser.parse_args(args=[])
youtube_reporting = get_authenticated_service()
if not args.job_id and not args.report_url:
if list_reporting_jobs(youtube_reporting,
onBehalfOfContentOwner=args.content_owner):
args.job_id = get_job_id_from_user()
if args.job_id and not args.report_url:
retrieve_reports(youtube_reporting,
jobId=args.job_id,
onBehalfOfContentOwner=args.content_owner)
args.report_url = get_report_url_from_user()
# Download the selected report.
if args.report_url:
download_report(youtube_reporting,args.report_url, args.local_file)
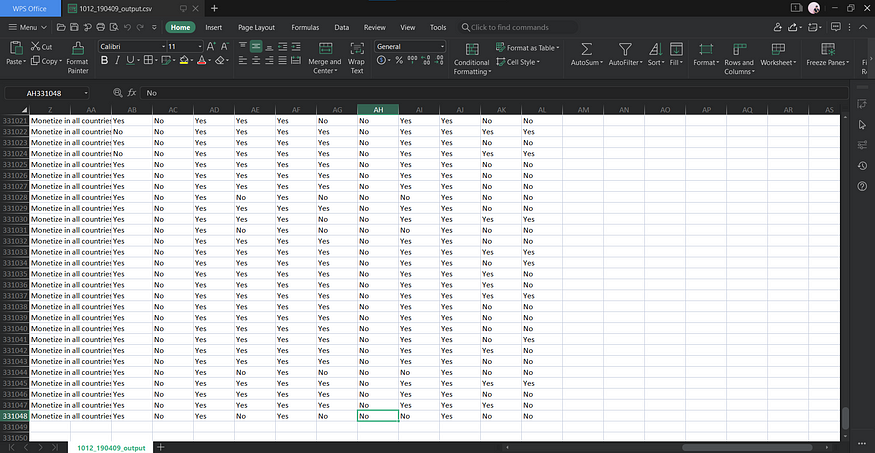
- 因为资料内容比较敏感,所以只能贴角落给大家看,但是可以得到所有影片相关的资料,包含观看次数,各影片的相关观看结果,得到结果为光是 8 月12 日的资料就能够获得33万笔的资料,在大数据资料抓取上比起 Youtube Analytics API 还要方便得多。
- 再次附上完整程序码做总结
import argparse,os
import sys,time,csv
import google.oauth2.credentials
import google_auth_oauthlib.flow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from googleapiclient.http import MediaIoBaseDownload
from google_auth_oauthlib.flow import InstalledAppFlow
from io import FileIO
from datetime import datetime
CLIENT_SECRETS_FILE = 'client_secret_5....你的金钥rcontent.com.json'
SCOPES = ['https://www.googleapis.com/auth/yt-analytics-monetary.readonly']
API_SERVICE_NAME = 'youtubereporting'
# Authorize the requests.
def get_authenticated_service():
flow = InstalledAppFlow.from_client_secrets_file(CLIENT_SECRETS_FILE, SCOPES)
credentials = flow.run_console()
return build('youtubereporting','v1', credentials=credentials)
# Remove arguments word.
def remove_empty_kwargs(**kwargs):
good_kwargs = {}
if kwargs is not None:
for key, value in kwargs.items():
if value:
good_kwargs[key] = value
return good_kwargs
# Call the YouTube Reporting API's jobs.
def list_reporting_jobs(youtube_reporting, **kwargs):
kwargs = remove_empty_kwargs(**kwargs)
results = youtube_reporting.jobs().list(**kwargs).execute()
if 'jobs' in results and results['jobs']:
jobs = results['jobs']
for job in jobs:
print('YouTube Reporting API job id: %s\n name: %s\n for reporting type: %s\n'
% (job['id'], job['name'], job['reportTypeId']))
else:
print ('None jobs')
return False
return True
# Call the YouTube Reporting API's reports.list method to retrieve reports created by a job.
def retrieve_reports(youtube_reporting, **kwargs):
kwargs = remove_empty_kwargs(**kwargs)
results = youtube_reporting.jobs().reports().list(
**kwargs
).execute()
if 'reports' in results and results['reports']:
reports = results['reports']
for report in reports:
print('Report dates: %s \n download URL: %s\n'
% (report['startTime'], report['downloadUrl']))
# print('Report dates: %s to %s\n download URL: %s\n'
# % (report['startTime'], report['endTime'], report['downloadUrl']))
# Call the YouTube Reporting API's media.download method to download the report.
def download_report(youtube_reporting, report_url, local_file):
request = youtube_reporting.media().download(
resourceName=' '
)
request.uri = report_url
fh = FileIO(local_file, mode='wb')
downloader = MediaIoBaseDownload(fh, request, chunksize=-1)
done = False
while done is False:
status, done = downloader.next_chunk()
if status:
print('Download %d%%.' % int(status.progress() * 100))
print('Download Complete!')
# Prompt the user to select a job and return the specified ID.
def get_job_id_from_user():
job_id = input('Please enter the job id for the report retrieval: ')
print('You chose "%s" as the job Id for the report retrieval.' % job_id)
return job_id
# Prompt the user to select a report URL and return the specified URL.
def get_report_url_from_user():
report_url = input('Please enter the report URL to download: ')
print('You chose "%s" to download.' % report_url)
return report_url
Youtube Reports API 告一个段落啦!!!!!!!!!!!!!!!!
终於结束啦!!!!! 如果有时间也欢迎看看我的夥伴们的文章
lu23770127 — SASS 基础初学三十天
10u1 — 糟了!是世界奇观!
juck30808 — Python — 数位行销分析与 Youtube API 教学
HLD — 浅谈物件导向与Design Pattern介绍
SiQing47 — 前端?後端?你早晚都要全端的,何不从现在开始?
Jerry Chien
【鲑鱼均】 现职是 200 多万订阅 Youtuber 的数据分析师,专长在 Python 的开发与使用,大学虽然是资讯背景但总是斜杠跑到商管行销领域,以工作角度来说的话,待过 FMCG、通讯软件、社群影音产业,也算是个数位行销体系出生的资讯人。这 30 天铁人挑战赛会从数位行销角度去重新切入数据分析这件事情,期待这个社会中,每个人能在各个角力间不断冲突而渐能找到一个平衡点回归最初的统计建立最终的初心。
<<: Day29. 虽然今年是2021,但我们要做2048(3)
Dungeon Mizarka 028
衔接VS和UI 好不容易掌握了UI架构的概念,也开始依照这个想法和VS进行接合,但UI架构里出现了很...
【程序】简说重构 转生成恶役菜鸟工程师避免 Bad End 的 30 件事 - 26
简说重构 何时、为何重构 重构难题 重构策略 ...
离职倒数15天:我本来以为子宫是我的附属品,但该不会其实我就只是子宫的容器而已?
辞职前,最犹豫的一件事是「没请产假会不会太亏」,哈哈。几乎公司所有前辈都会劝你辞职前先做的事:买房跟...
[D23] 物件侦测(4)
前面我们认识的都是"two stage"的方法,在整体的运行过程上没有那麽快速,所以在很多行动装置上...
Day5|【Git】动手建立、初始储存库(Repository)!
这里我们先看一张图,大概了解一下 Git 在发布专案时的流程。 先有个概念,之後会逐一详细解释。 开...