Python 演算法 Day 2 - 理论基础 线性代数
Chap.I 理论基础
Part 1:线性代数
1. Getting Started with Equations
1-1. eval(),算数
x=6
y=10
eval('100 * x +300 +y +9')
>> 919
1-2. exec(),把 () 中的语法视作 python 语法,接着执行
exec('''
for i in range(5):
print (f"iter time: {i}" )
''')
>> iter time: 0
iter time: 1
iter time: 2
iter time: 3
iter time: 4
1-3. Symbol Python(sympy)
A. 解方程序 (预设右侧为0)
from sympy.solvers import solve
from sympy import Symbol
x = Symbol('x')
print(solve(x**2 - 1, x))
>> [-1, 1]
B 产生上标 (jupyter 有效 QQ)
from sympy.solvers import solve
from sympy import Symbol
x = Symbol('x')
x**4+2*x**2+3
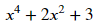
C. 直接解方程序
from sympy.core import sympify
x, y = sympify('x, y')
print(solve([x + y + 2, 3*x + 2*y], dict=True))
>> [{x: 4, y: -6}]
2. Linear Equations 线性方程序
2-1. Intercept (截距)
# 求 20 个 x 点对应的 y 值
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame ({'x': range(-10, 11)})
df['y'] = (3*df['x'] - 4) / 2
# 作图
plt.plot(df.x, df.y, color="0.5")
plt.xlabel('x')
plt.ylabel('y')
plt.grid()
plt.axhline()
plt.axvline()
x_i = [(1.33, 0), (0, 0)]
y_i = [[0, 0], [0, -2]]
plt.annotate('x-intercept',(1.333, 0))
plt.annotate('y-intercept',(0,-2))
plt.plot(x_i[0], x_i[1], color="r")
plt.plot(y_i[0], y_i[1], color="y
plt.show()
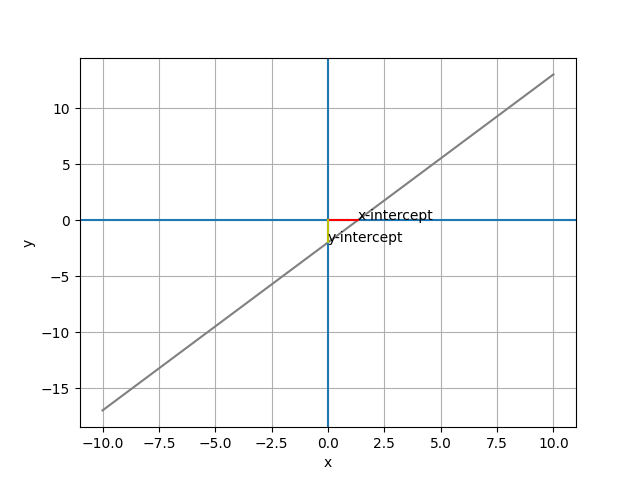 ")
")
2-2. slope
# 作图
plt.plot(df.x, df.y, color="0.5")
plt.xlabel('x')
plt.ylabel('y')
plt.grid()
plt.axhline()
plt.axvline()
# the slope
slope = 1.5
x_slope = [0, 1]
y_slope = [-2, -2 + slope]
plt.plot(x_slope, y_slope, color='red', lw=5)
plt.savefig('pic 03.png')
plt.show()
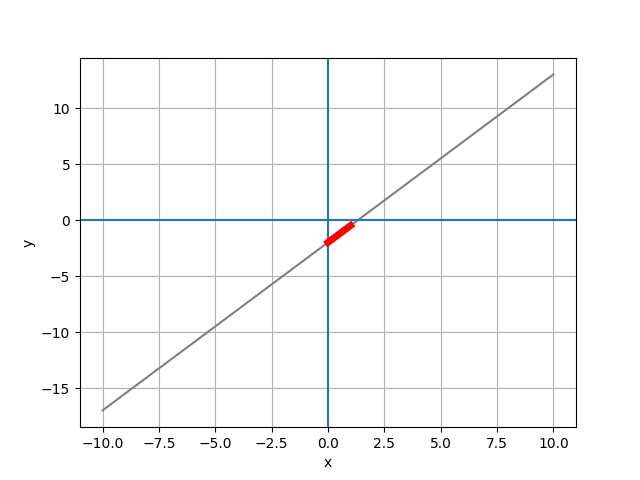
2-3. Regression
# 世界人口预测
year=[1950, 1951, 1952, 1953, 1954, ...2100]
pop=[2.53, 2.57, 2.62, 2.67, 2.71, ...10.85]
# 1. Numpy regression
x1 = np.linspace(1950, 2101, 2000)
fit = np.polyfit(year, pop, 1)
y1 = np.poly1d(fit)(x1)
# 作图
plt.figure(num=None, figsize=(18, 10), dpi=80, facecolor='w', edgecolor='k')
plt.plot(year, pop, 'b-o', x1, y1, 'r--')
plt.show()
# 2. LinearRegression
X = np.array(year).reshape(len(year), 1)
y = np.array(pop)
from sklearn.linear_model import LinearRegression as LR
clf = LR()
clf.fit(X, y) # 线性回归
print(f'y = {clf.coef_[0]:.2f} * x + {clf.intercept_:.2f}')
>> y = 0.06 * x + -116.36
# 作图
plt.figure(num=None, figsize=(18, 10), dpi=80, facecolor='w', edgecolor='k')
x1 = np.arange(1950, 2101)
y1 = clf.coef_[0] * x1 - clf.intercept_
plt.plot(year, pop, 'b-o', x1, y1, 'r--')
plt.show()
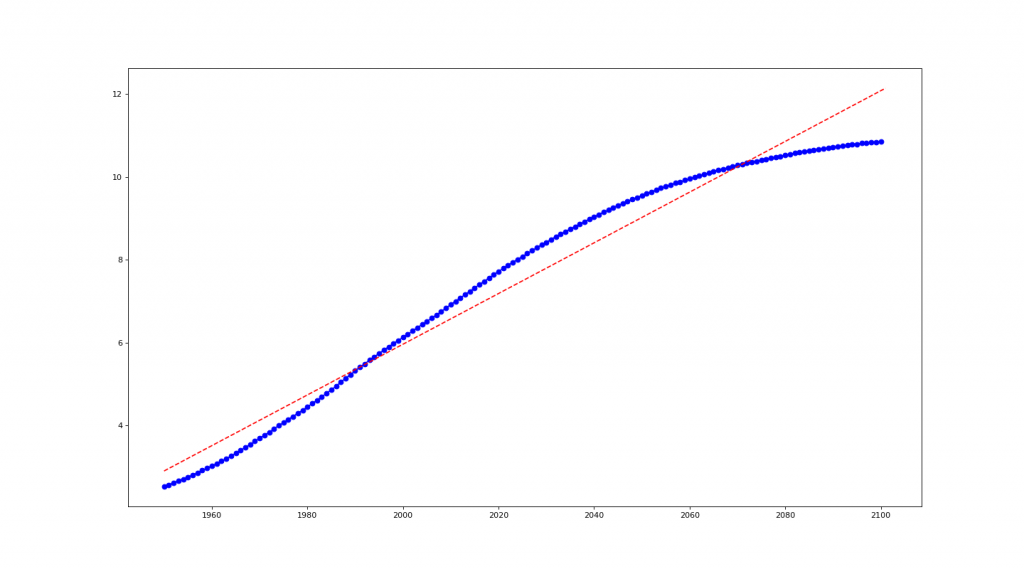
2-4. 用 make_regression 产生乱数资料
from sklearn.datasets import make_regression as mr
# n_features= : 几个 x
# noise= : 杂讯量
# bias= : 截距
X, y= mr(n_samples=1000, n_features=1, noise=10, bias=50)
# use sklearn LinearRegression
from sklearn.linear_model import LinearRegression as LR
clf = LR()
clf.fit(X, y)
coe = clf.coef_[0]
ic = clf.intercept_
print(f' y = {coe:.2f} * x + {ic:.2f}') # 1 + {clf.coef_[1]:.2f} * x2
>> y = 89.69 * x + 52.88
# 作图
import matplotlib.pyplot as plt
plt.figure(num=None, figsize=(18, 10), dpi=80, facecolor='w', edgecolor='k')
plt.scatter(X, y, c='b') # 画出 X, y 点点
X1 = np.linspace(-3, 2, 100)
plt.plot(X1, coe*X1 + ic, 'r') # 画出回归红线
plt.show()
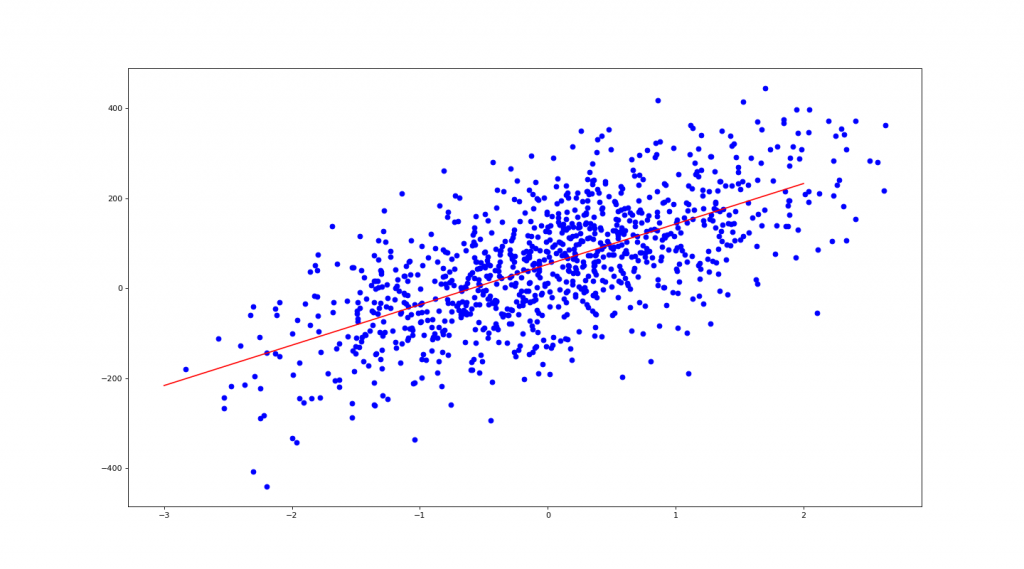
3. Systems of Equations 联立方程序
Numpy 线性代数解联立方程序
EX1. 4x - 5y = -13
-2x + 3y = 9
import numpy as np
a = np.array([[4, -5], [-2, 3]])
b = np.array([-13, 9])
print(np.linalg.solve(a, b))
>> [3. 5.]
EX2. x + 2y = 5
y - 3z = 5
3x - z = 4
a = np.array([[1, 2, 0], [0, 1, -3], [3, 0, -1]])
b = np.array([5, 5, 4])
print(np.linalg.inv(a) @ b)
>> [ 1. 2. -1.]
4. Exponentials, Radicals, and Logs 指数、根号和对数
4-1. Basic
import math
# 16 是 4 的几次方
print(math.log(16, 4))
>> 2.0
# 100 是 log10 的几次方
print(math.log10(100))
>> 2.0
# e & pi
print(math.e, math.pi) # 等同於 np.e, np.pi
>> 2.718281828459045 3.141592653589793
# 100 是 e 的几次方
print(math.log(100, math.e))
>> 4.605170185988092
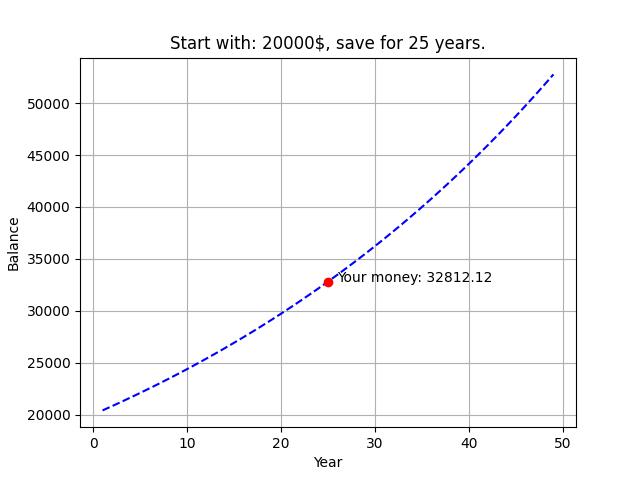
4-2. Solving Equations with Exponentials
复利计算
import pandas as pd
m = int(input('请输入你想存多少 (钱): '))
i = int(input('请输入你想存多久 (年): '))
total_monety = m*(1.02**i)
df = pd.DataFrame ({'Year': range(1, 50)})
df['Balance'] = m*(1.02**df['Year'])
from matplotlib import pyplot as plt
plt.plot(df.Year, df.Balance, 'b--', i, total_monety, 'ro')
plt.xlabel('Year')
plt.ylabel('Balance')
plt.grid()
plt.title(f'Start with: {m}$, save for {i} years.')
plt.annotate(f'Your money: {total_monety:.2f}',(i+1, total_monety))
plt.show()
5. Polynomials 多项式
- Adding Polynomials
- Subtracting Polynomials
- Multiplying Polynomials
- Dividing Polynomials
6. Factorization 因式分解
Greatest Common Factor (最大公因数)
a = int(input('数字1: '))
b = int(input('数字2: '))
def GCD(x, y):
while True:
if y == 0:
print(x)
break
else:
return GCD(y, x%y)
GCD(a, b)
7. Quadratic Equations 二次方程序
7-1. Parabola 抛物线
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.DataFrame ({'x': range(-9, 9)})
df['y1'] = 2*df['x']**2 + 2 *df['x'] - 4
df['y2'] = -(2*df['x']**2 + 2*df['x'] - 4)
# 作图
from matplotlib import pyplot as plt
plt.plot(df.x, df.y1, 'b', df.x, df.y2, 'r')
plt.plot()
plt.xlabel('x')
plt.ylabel('y')
plt.grid()
plt.axhline()
plt.axvline()
plt.show()
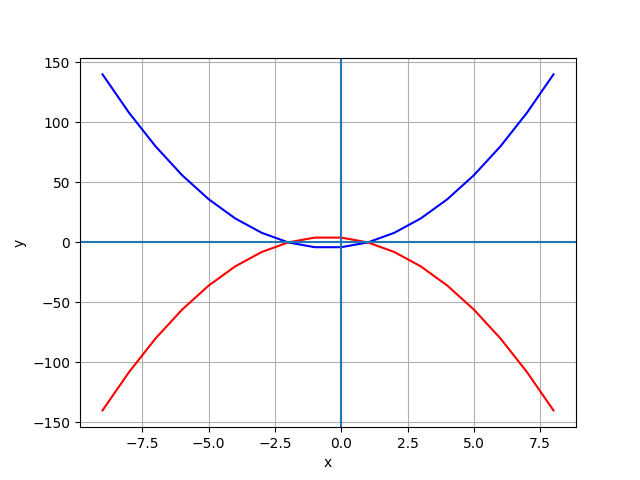
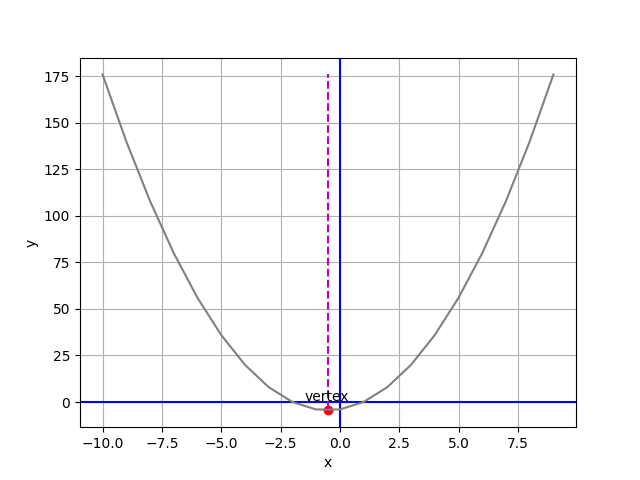
7-2. Parabola Vertex and Line of Symmetry 抛物线顶点与对称线
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def plot_parabola(a, b, c): # 代入 (2, 2, -4)
vx = (-1*b)/(2*a) # 极值点斜率必为0,f(x)'=2ax+b=0,x=(-b/2a)
vy = a*vx**2 + b*vx + c # 代入 f(x) 求极值 y 座标
df = pd.DataFrame ({'x': np.linspace(-10, 10, 100)})
df['y'] = a*df['x']**2 + b*df['x'] + c # 把 x, y 输入进 df
# 作图
plt.xlabel('x') # x 轴名称
plt.ylabel('y') # y 轴名称
plt.grid() # 灰色格线
plt.axhline(c='b') # 水平基准线
plt.axvline(c='b') # 垂直基准线
xp = [vx, vx]
yp = [df.y.min(), df.y.max()]
plt.plot(df.x, df.y, '0.5', xp, yp, 'm--') # 划出抛物线 / y 最小垂直线
plt.scatter(vx, vy, c='r') # 划出 y 最小点
plt.annotate('vertex', (vx, vy), xytext=(vx - 1, (vy + 5)* np.sign(a)))
plt.savefig('pic 10.png')
plt.show()
plot_parabola(2, 2, -4)
8. Function 函数
8-1. Basic
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return x**2 + 2
8-2. Bounds of a Function
import numpy as np
import matplotlib.pyplot as plt
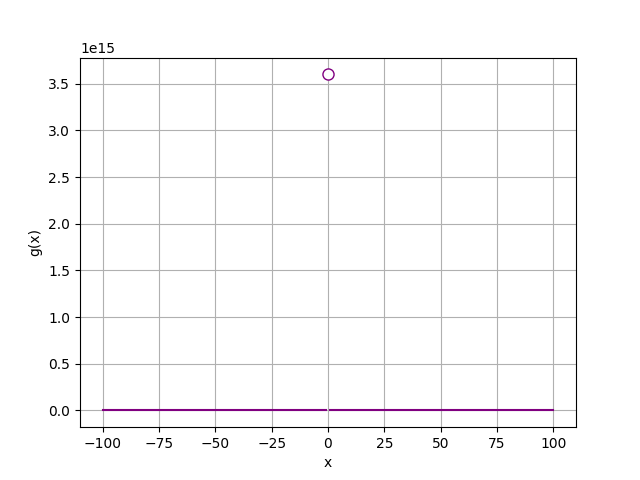
def g(x):
if x != 0:
return (12/(2*x))**2
x = range(-100, 101)
y = [g(a) for a in x]
# 作图
plt.xlabel('x')
plt.ylabel('g(x)')
plt.grid()
plt.plot(x,y, color='purple')
plt.plot(0, g(0.0000001), c='purple', marker='o', markerfacecolor='w', markersize=8)
plt.show()
.
.
.
.
.
Homework Ans:
1. 红酒分类:
import pandas as pd
import numpy as np
from sklearn import datasets
ds = datasets.load_wine()
X =pd.DataFrame(ds.data, columns=ds.feature_names)
y = ds.target
from sklearn.model_selection import train_test_split as tts
X_train, X_test, y_train, y_test = tts(X, y, test_size=0.1)
A. 使用 KNN 验算法:
from sklearn.neighbors import KNeighborsClassifier as KNN
clf = KNN(n_neighbors=3)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
>> 0.78
B. 使用 LogisticRegression 验算法:
from sklearn.linear_model import LogisticRegression as lr
clf2 = lr(solver='liblinear')
clf2.fit(X_train, y_train)
clf2.score(X_test, y_test)
>> 1.0
以上两种模型比较後,选择第二种模型。
此步骤是在做机器学习第八步:Evaluate Module
2. 糖尿病回归:
import pandas as pd
import numpy as np
from sklearn import datasets
ds = datasets.load_diabetes()
# 注意此处 X 的数值经过 standardization,固有出现年龄负值的情况。
# (X-m)/sigma,平均为 0 / 标准差为 1
X = pd.DataFrame(ds.data, columns=ds.feature_names)
y = ds.target
from sklearn.model_selection import train_test_split as tts
X_train, X_test, y_train, y_test = tts(X, y, test_size=0.2)
from sklearn.linear_model import LinearRegression
clf = LinearRegression()
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
>> 0.46
额外补充:求 MSE & Coefficients
from sklearn.metrics import mean_squared_error, r2_score
y_pred = clf.predict(X_test)
# Coefficients (一次项式系数)
# y = w1*x1 + w2*x2 + w3*x3 ... w10*x10 + b
print('Coefficients: ', clf.coef_)
>> Coefficients: [ -42.4665896 -278.41905956 519.81553297 346.25936576 -836.62271952
494.18394438 135.91708785 164.44984594 795.02484868 69.8608995 ]
print('Intercept: ', clf.intercept_)
>> Intercept: 152.2877890433722
# MSE (均方误差):1/n * sum(y_pred-y_test)
print(f'MSE: {mean_squared_error(y_test, y_pred)}')
>> MSE: 3161.582266519054
# Coefficient of determination (判定系数):越接近 1 越好
print(f'Coefficient of determination: {r2_score(y_test, y_pred)}')
>> Coefficient of determination: 0.4556662437750665
3. 小费回归:
import pandas as pd
import numpy as np
from sklearn import datasets
df = pd.read_csv('tips.csv')
print(df.head())
X = df.drop('tip', axis=1) # 把'tip'丢弃
y = df['tip'] # y 为要分析的资料
# 显示 'sex' 栏位不同的项目
print(X['sex'].unique())
>> ['Female' 'Male']
此时若直接跑演算法,会发现评分过低,推断为 X['day']转化为数字时编码问题。
解决方式如下:
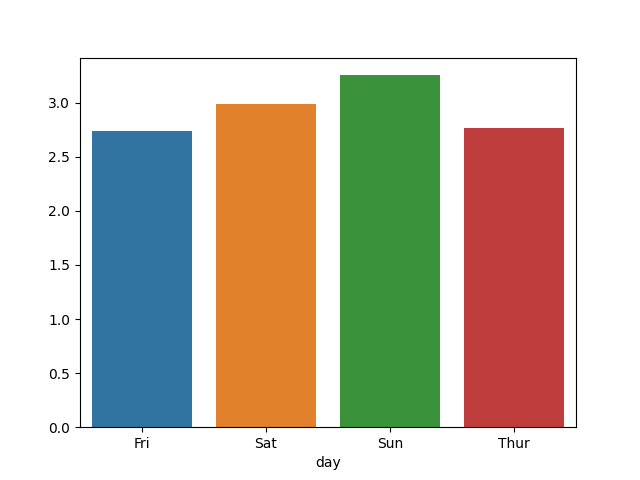
gb = df.groupby(['day'])['tip'].mean()
print(gb)
>> Fri 2.73
Sat 2.99
Sun 3.26
Thur 2.77
import seaborn as sns
import matplotlib.pyplot as plt
sns.barplot(gb.index, gb.values)
plt.show()
# 把所有值换成数字才能分析
X['sex'].replace({'Female' : 0, 'Male' : 1}, inplace=True)
X['smoker'].replace({'Yes' : 0, 'No' : 1}, inplace=True)
X['day'].replace({'Thur' : 0, 'Fri' : 0, 'Sat' : 2, 'Sun' : 3}, inplace=True)
X['time'].replace({'Lunch' : 0, 'Dinner' : 1}, inplace=True)
from sklearn.model_selection import train_test_split as tts
X_train, X_test, y_train, y_test = tts(X, y, test_size = 0.2)
from sklearn.linear_model import LinearRegression
clf = LinearRegression()
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
>> 0.4
<<: HTML教学课程 (入门篇) 4个章节 - 由浅入深学习HTML
[Day6] 自我必备沟通力:Content & Context
发挥影响力 随时必备的两个元素:Content & Context 自觉、找镜子、了解与掌握...
Day14-守护饼乾大作战(一)
前言 哈罗大家好,前几天讲完 HTTP Security Headers 之後今天紧接着要讲 coo...
Day27 过不去的槛就先绕过它 - LINE Notification
原本於Day26打算利用Message API来完成LINE Bot功能,但发现Webhook需要搭...
Day 23 : Tkinter-利用Python建立GUI(基本操作及布局篇)
在进入Tkinter之前,先来讲讲GUI到底是甚麽。 GUI GUI其实就是图形使用者介面(Grap...
Re: 新手让网页 act 起来: Day18 - React Hooks 之 useRef
前言 探索完 useState 与 useEffect ,今天就让我们回来继续介绍其他的 React...