Day 29 - Learned Index测试&比较
今天要来测试并比较我们实作出的 Learned Index 与单一 Model(SLR、NN) 的分布情况,我们随机产生 100k 笔 Lognormal (mean=0, sigma=2)分布的资料,产生出来的值乘以1000000。
Learned Index可分为 9 种:第一层 Model 为 SLR、8x8 NN、16x16 NN,第二层的 Model 都为 SLR,只是数量配置不同,可分为 3、10、100,总共 9 种 Learned Index。单一 Model 则分为 SLR、8x8 NN、16x16 NN、32x32 NN 共 4 种。
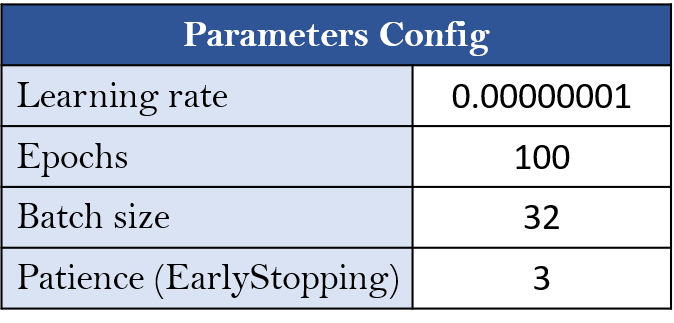
NN Model的参数配置如下(大家可再自行测试调整):
Learned Index
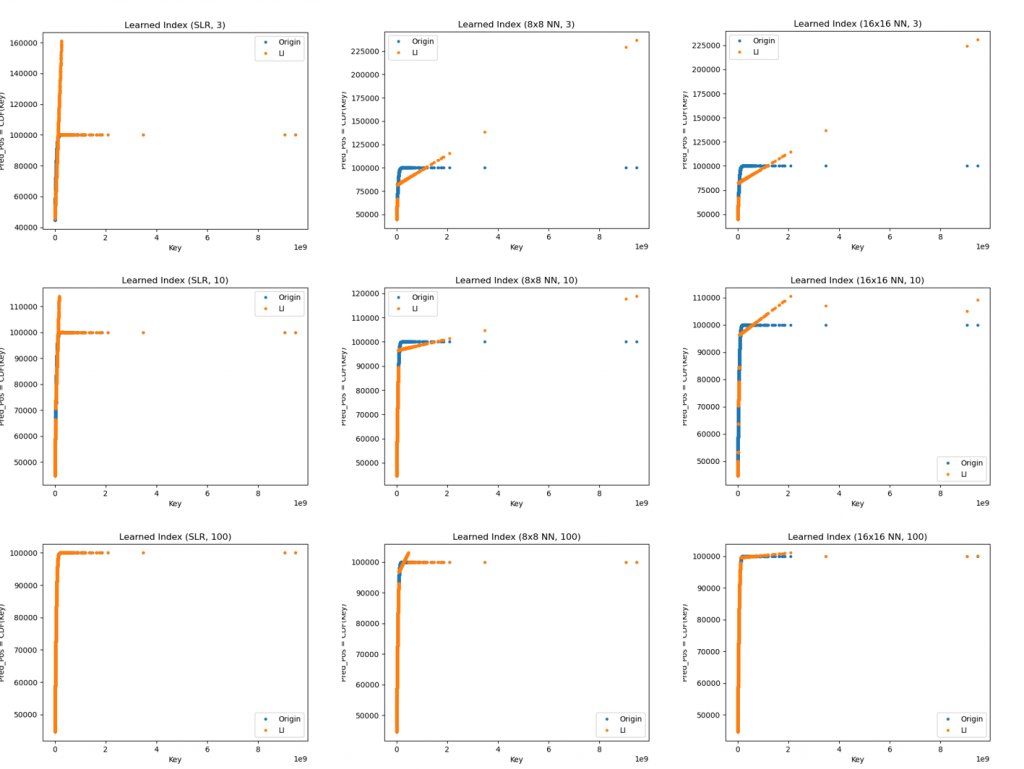
Learned Index不同配置下测试结果的比较图,图表标题表示的意思为Learned Index(第一层的模型为何, 第二层模型的数量) :
Single Model
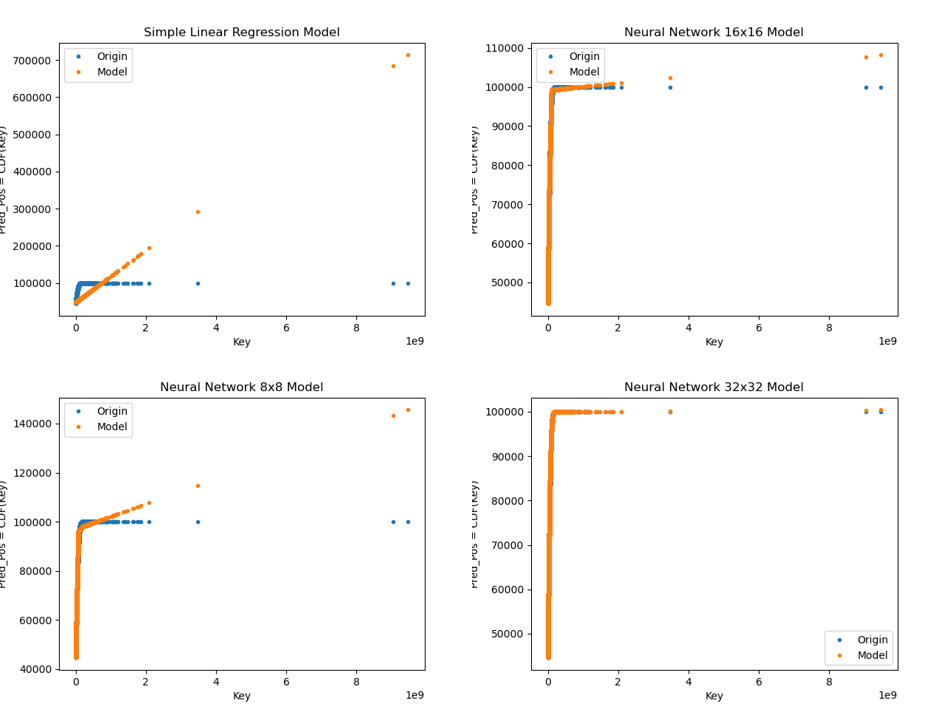
不同Single Model测试下的比较图 :
结论
测试完可以看到,对於 Learned Index 来说,第二层 Models 数量配置越多,越拟合 CDF分布,依据我们测试结果发现,对於 Learned Index 来说,架构配置为(SLR, 100) 最拟合 CDF分布! 跟我原本预想的不一样,我以为(8x8, 100)、(16x16, 100)的配置会最好的说><,对於单一模型来看,NN 32x32模型拟合效果最佳!
其实测试完後,感觉不用配置到相较复杂的Learned Index,使用单一模型 NN 32x32,就足以拟合分布嘞。但我们也只是进行简单的测试,资料数量很少只有100k,当资料来到 100M,Learned Index 是否会真的比较适合,是很值得去探讨的地方! 另外 Model 调参的部分,我是手动去调 XD,也许还其他更佳的参数配置,对於 Model 训练更好!
<<: 会员管理网站实作篇- (以律师谘询平台为例子) part4
Day 02 HTML/CSS 点击超连结会经历的伪类选取器(Pseudo-classes)
根据 MDN,目前 CSS 的伪类选取器有以下这些: 今天要介绍到的是关於点击超连结後会经历的五种伪...
【Day 9】Google Apps Script - 部署网页应用程序与触发doGet(e)测试
「查询Gamil资讯」API 实作完成,那就可以部署上线测试啦。 今日要点: 》部署 API 》呼...
Day 11 - 丰收款非官方 PHP SDK 发布
因为要陪老婆追剧鱿鱼游戏,所以还有几个测试还没写完,但大致上这个 PHP SDK 的 API 已经开...
DAY 4 - 牛头怪
大家好~ 我是五岁~ 今天来画牛头怪~ 今天会尝试卡通风格~ 目标是一只跟人一样站立的牛头怪,武器是...
[Day20]程序菜鸟自学C++资料结构演算法 – 杂凑法(Hash)
前言:之前谈到的方法都需要透过「关键字」的比较来找出想要的值,但是杂凑法与之前的搜寻法有些差异,究竟...