我们的基因体时代-AI, Data和生物资讯 Day04- 深度学习在基因体学的建模架构01
上一篇我们的基因体时代-AI, Data和生物资讯 Day03- 基因医学的数据问题介绍了基因医学中的数据问题,实际上面对DNA的序列ATCG,我们是在想什麽问题,以及去解析这样的资料背後所牵涉的复杂架构,我们举BRCA1这个鼎鼎有名的基因为例,实际去把它的序列部分显示出来,接者则把目前此领域的专家是如何去处理背後问题,以及基因是由外显子和内显子所构成(简化来说),另外,也分享目前人类两万多个基因,其实只有不到十个是人们常探究的,大部分的基因直到目前都还是空白的状态!
以单一个基因内两个相邻外显子是否会剪接
今天我们继续接者往下深入,为了能把生物问题有效的建构成学习问题,这边再往下分享一些分子生物学的知识,才会知道我们到底该怎麽利用深度学习来回答这领域的问题。上一篇有分享了一个基因的序列可以分为外显子(Exon)和内显子(Intron),本质上这些外显子是会转换成蛋白质的序列,一个基因可以经由排列组合不同的外显子顺序和数量,而产生不同的mRNA,进而产生不同的蛋白质,这个现象称作剪接(splicing),如下图所示:
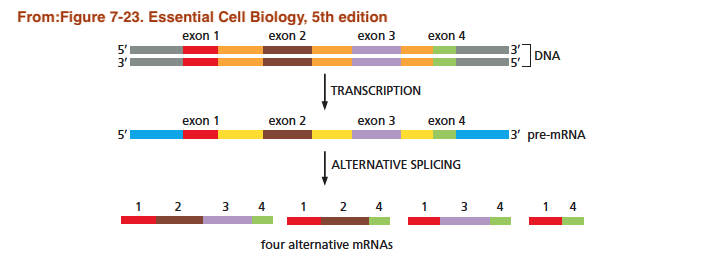
那一个基因中特定的外显子是否会被剪接呢?就可以把它变成是一个学习问题,而且是一个监督学习(supervised learning)如下:
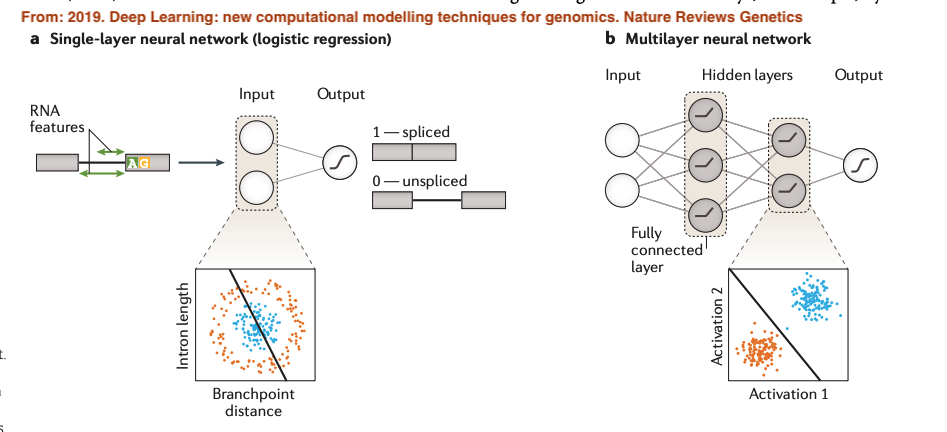
基本上,监督学习的目的是建立一个模型,这个模型有输入(features),然後会有个输出(target),在这个问题下,输入可以是这个外显子区域的序列,输出可以是1(剪接)和0(不剪接),而训练机器模型其实就是在学习他的参数,这过程会最小化所谓的Loss function,这样才能避免overfitting,也就是能对没有预测过的资料有较好的结果。
一个基因的外显子会如何剪接,其实外显子和内显子的序列可能会有所影响,如下面这张图所表示的:
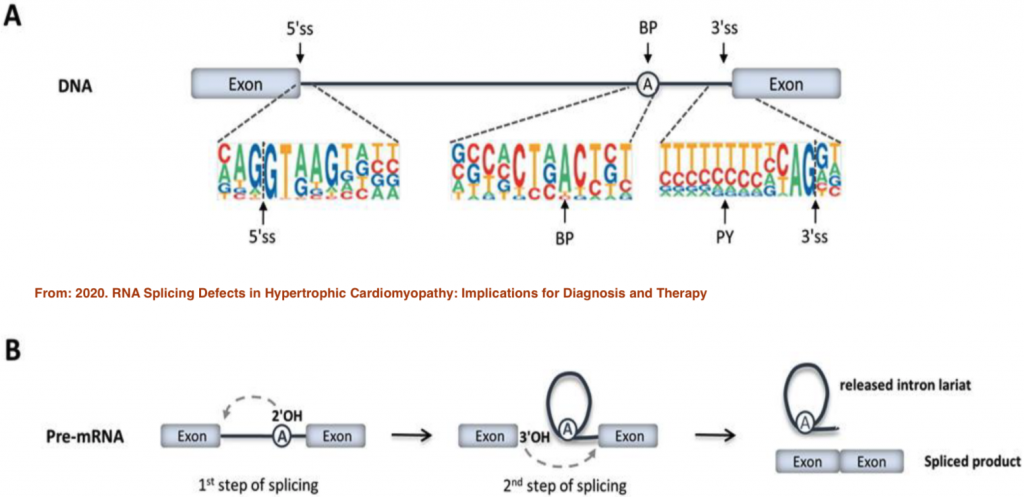
从上图中,很清楚地展示了外显子和内显子交界处会有特徵,另外,两个外显子中的内显子序列,会有个一个区域的序列是会影响剪接的,换句话说,这些都可以转换成所谓的特徵,来变成输入的资料。
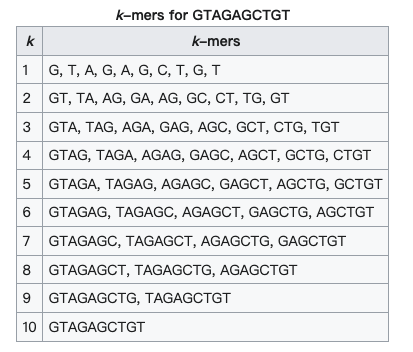
复杂的资料关联恰好可以用深度学习的架构来处理,大部分的监督学习的输入都是表格的资料,也就是一行为一笔资料料,每个栏位是关於这个资料的特徵(feature),当然也有这个资料的标签,以上面这个预测一个基因上的两个外显子会怎麽剪接来说,其区域上的ATCG频率和内显子中间区域的ATCG频率都可以变成输入表格中的一个栏位,在DNA的序列上,有一个提取特徵的概念叫做k-mer,简单而言,就是在说一个DNA序列中,在特定长度下去切割这个序列,会产生几种排列组合,再将这些资讯拿来做进一步的计画。下面这个就是wiki上面k-mer范例:
所以简单来做,我们要将一个分子生物的问题,转换乘下面这个资料架构,接者就可以来建模:
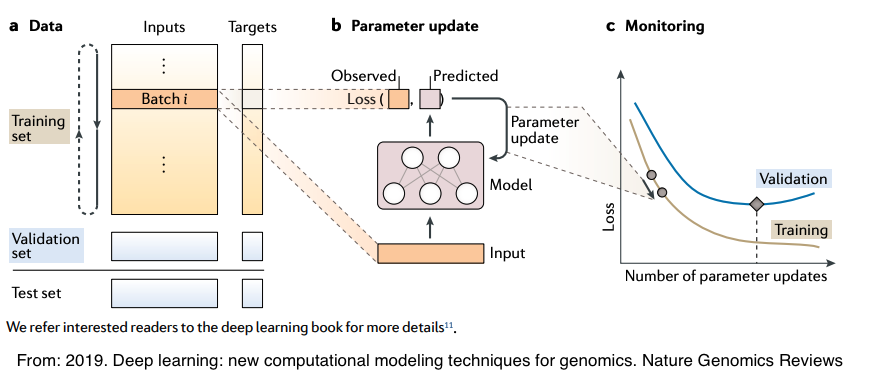
从左边往右边来看,左边是大部分建模前的资料型态,就是一个大表,在监督式学习下,每笔资料都会有个标签(就是target),通常会把资料切成训练以及验证的两组资料。在以前,建立完建模的资料後,还必须撰写很复杂的运算,但如今有超多写得非常简易的框架,可以直接用,比如下面就是用Python的keras来建立神经网络的架构:
# this code were from 2019. Deep learning: new computational modelling techniques for genomics. Nature Review Genetics
import keras.layers as kl
from keras.models import Sequential
# Fully connected model architecture
model = Sequential([
k1.Dense(3, activation='relu', input_shape=(2,)),
k1.Dense(2, activation='relu'),
k1.Dense(1, activation='sigmoid')
])
# Specify optimizer, loss and evaluation metric
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# Load the dataset
x, y = load_dataset(...)
# Train the model for 10 epochs
model.fit(x,y, epochs=10)
从上面keras的代码,可以感觉整个撰写的感受非常好,基本上就像是在写算式一样,不太有码农的味道,反而像是数学式,所以现在这样的技能快要变成是一种基本配备,这个主题会再往下展开,实在是很有趣,但也很复杂,因为需要理解分子生物学目前已知的现象,然後才有办法来定义问题,反而问题定义好後,建模的程序代码已经变得非常亲民!
这个月的规划贴在这篇文章中我们的基因体时代-AI, Data和生物资讯 Overview,也会持续调整!我们的基因体时代是我经营的部落格,如有对於生物资讯、检验医学、资料视觉化、R语言有兴趣的话,可以来交流交流!
目前许多深度学习的相关资源:
- 云端平台:
- Fabrik
- FloydHub
- PaperSpace
- Valohai
- Google CloudML
- Azure ML
- 软件
- Keras
- TensorFlow
- PyTorch
- 专门用在基因体问题的深度学习软件
- DragoNN
- Kipoi
- 相关线上课程
- fast.ai
- Textbook: http://neuralnetworksanddeeplearning.com/
阅读参考:
- Deep learning: new computational modelling techniques for genomics. Nature Reviews Genetics(2019)
- A primer on deep learning in genomics. Nature Reviews Genetics(2019)
- Deep learning for computational biology. Mol. Syst. Biol. 12, 878 (2016).
- Deep learning in bioinformatics. Brief. Bioinform. 18, 851–869 (2017).
- Computational biology: deep learning. Emerg. Top. Life Sci. 1, 257–274 (2017).
- Deep learning in biomedicine. Nat. Biotechnol. 36, 829–838 (2018).
- Opportunities and obstacles for deep learning in biology and medicine. J. R. Soc. Interface 15, 20170387 (2018).
DAY14 挑选合适的模型进行训练
机器学习可以分成监督式学习与非监督式学习,这部分我们在第四天有稍微提到过,这边就不多做说明了,今天我...
该如何证明资料曾经存在?
第一次发言, 请各路大神关照. 公司需要定期作资料库备份, 备份用的电脑OS为Win 7及Win 1...
[python 爬虫] 美金_欧元 半年走势
import matplotlib.pyplot as plt import requests im...
[DAY-08] 增进诚实敢言 把一切摊在阳光下
人们如果主动隐瞒某些事 反而会花两倍时间想着那着些事 秘密的问题在於 只要你说出来 他就不再是秘密...
Day 0x10 UVa10057 A mid-summer nights dream
Virtual Judge ZeroJudge 题意 输入 n 个数字,输出能使 (|X1 − A...